[link]
Summary by Alexander Jung 7 years ago
* When using pretrained networks (like VGG) to solve tasks, one has to use features generated by these networks.
* These features come from specific layers, e.g. from the fully connected layers at the end of the network.
* They test whether the features from fully connected layers or from the last convolutional layer are better suited for face attribute prediction.
### How
* Base networks
* They use standard architectures for their test networks, specifically the architectures of FaceNet and VGG (very deep version).
* They modify these architectures to both use PReLUs.
* They do not use the pretrained weights, instead they train the networks on their own.
* They train them on the WebFace dataset (350k images, 10k different identities) to classify the identity of the shown person.
* Attribute prediction
* After training of the base networks, they train a separate SVM to predict attributes of faces.
* The datasets used for this step are CelebA (100k images, 10k identities) and LFWA (13k images, 6k identities).
* Each image in these datasets is annotated with 40 binary face attributes.
* Examples for attributes: Eyeglasses, bushy eyebrows, big lips, ...
* The features for the SVM are extracted from the base networks (i.e. feed forward a face through the network, then take the activations of a specific layer).
* The following features are tested:
* FC2: Activations of the second fully connected layer of the base network.
* FC1: As FC2, but the first fully connected layer.
* Spat 3x3: Activations of the last convolutional layer, max-pooled so that their widths and heights are both 3 (i.e. shape Cx3x3).
* Spat 1x1: Same as "Spat 3x3", but max-pooled to Cx1x1.
### Results
* The SVMs trained on "Spat 1x1" performed overall worst, the ones trained on "Spat 3x3" performed best.
* The accuracy order was roughly: `Spat 3x3 > FC1 > FC2 > Spat 1x1`.
* This effect was consistent for both networks (VGG, FaceNet) and for other training datasets as well.
* FC2 performed particularly bad for the "blurry" attribute (most likely because that was unimportant to the classification task).
* Accuracy comparison per attribute:
* 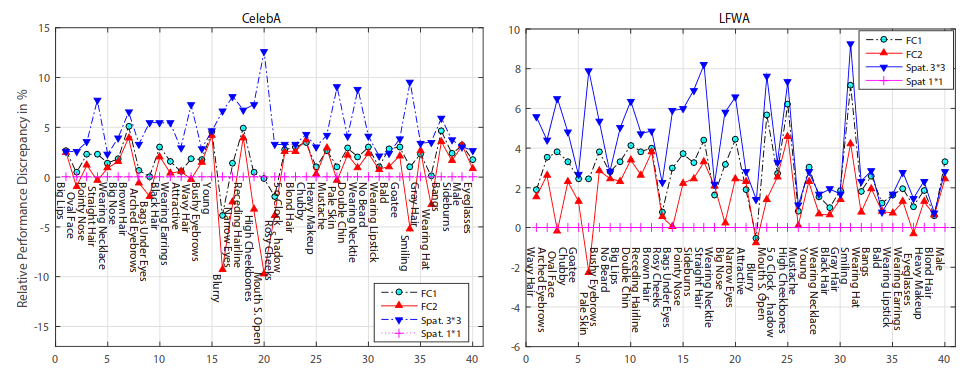
* The conclusion is, that when using pretrained networks one should not only try the last fully connected layer. Many characteristics of the input image might not appear any more in that layer (and later ones in general) as they were unimportant to the classification task.















