Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Denton, Emily L. and Chintala, Soumith and Szlam, Arthur and Fergus, Rob
Neural Information Processing Systems Conference - 2015 via Local Bibsonomy
Keywords: dblp
Denton, Emily L. and Chintala, Soumith and Szlam, Arthur and Fergus, Rob
Neural Information Processing Systems Conference - 2015 via Local Bibsonomy
Keywords: dblp













[link]
* The original GAN approach used one Generator (G) to generate images and one Discriminator (D) to rate these images.
* The laplacian pyramid GAN uses multiple pairs of G and D.
* It starts with an ordinary GAN that generates small images (say, 4x4).
* Each following pair learns to generate plausible upscalings of the image, usually by a factor of 2. (So e.g. from 4x4 to 8x8.)
* This scaling from coarse to fine resembles a laplacian pyramid, hence the name.
### How
* The first pair of G and D is just like an ordinary GAN.
* For each pair afterwards, G recieves the output of the previous step, upscaled to the desired size. Due to the upscaling, the image will be blurry.
* G has to learn to generate a plausible sharpening of that blurry image.
* G outputs a difference image, not the full sharpened image.
* D recieves the upscaled/blurry image. D also recieves either the optimal difference image (for images from the training set) or G's generated difference image.
* D adds the difference image to the blurry image as its first step. Afterwards it applies convolutions to the image and ends in one sigmoid unit.
* The training procedure is just like in the ordinary GAN setting. Each upscaling pair of G and D can be trained on its own.
* The first G recieves a "normal" noise vector, just like in the ordinary GAN setting. Later Gs recieve noise as one plane, so each image has four channels: R, G, B, noise.
### Results
* Images are rated as looking more realistic than the ones from ordinary GANs.
* The approximated log likelihood is significantly lower (improved) compared to ordinary GANs.
* The generated images do however still look distorted compared to real images.
* They also tried to add class conditional information to G and D (just a one hot vector for the desired class of the image). G and D learned successfully to adapt to that information (e.g. to only generate images that seem to show birds).
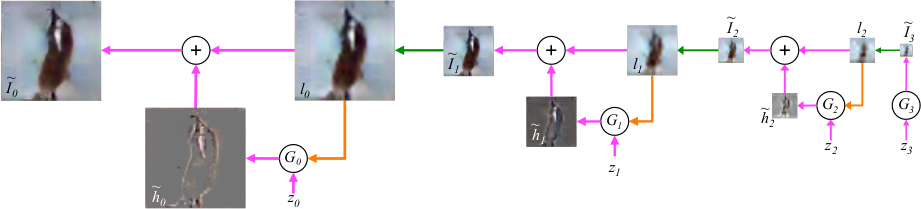
*Basic training and sampling process. The first image is generated directly from noise. Everything afterwards is de-blurring of upscaled images.*
-------------------------
### Rough chapter-wise notes
* Introduction
* Instead of just one big generative model, they build multiple ones.
* They start with one model at a small image scale (e.g. 4x4) and then add multiple generative models that increase the image size (e.g. from 4x4 to 8x8).
* This scaling from coarse to fine (low frequency to high frequency components) resembles a laplacian pyramid, hence the name of the paper.
* Related Works
* Types of generative image models:
* Non-Parametric: Models copy patches from training set (e.g. texture synthesis, super-resolution)
* Parametric: E.g. Deep Boltzmann machines or denoising auto-encoders
* Novel approaches: e.g. DRAW, diffusion-based processes, LSTMs
* This work is based on (conditional) GANs
* Approach
* They start with a Gaussian and a Laplacian pyramid.
* They build the Gaussian pyramid by repeatedly decreasing the image height/width by 2: [full size image, half size image, quarter size image, ...]
* They build a Laplacian pyramid by taking pairs of images in the gaussian pyramid, upscaling the smaller one and then taking the difference.
* In the laplacian GAN approach, an image at scale k is created by first upscaling the image at scale k-1 and then adding a refinement to it (de-blurring). The refinement is created with a GAN that recieves the upscaled image as input.
* Note that the refinement is a difference image (between the upscaled image and the optimal upscaled image).
* The very first (small scale) image is generated by an ordinary GAN.
* D recieves an upscaled image and a difference image. It then adds them together to create an upscaled and de-blurred image. Then D applies ordinary convolutions to the result and ends in a quality rating (sigmoid).
* Model Architecture and Training
* Datasets: CIFAR-10 (32x32, 100k images), STL (96x96, 100k), LSUN (64x64, 10M)
* They use a uniform distribution of [-1, 1] for their noise vectors.
* For the upscaling Generators they add the noise as a fourth plane (to the RGB image).
* CIFAR-10: 8->14->28 (height/width), STL: 8->16->32->64->96, LSUN: 4->8->16->32->64
* CIFAR-10: G=3 layers, D=2 layers, STL: G=3 layers, D=2 layers, LSUN: G=5 layers, D=3 layers.
* Experiments
* Evaluation methods:
* Computation of log-likelihood on a held out image set
* They use a Gaussian window based Parzen estimation to approximate the probability of an image (note: not very accurate).
* They adapt their estimation method to the special case of the laplacian pyramid.
* Their laplacian pyramid model seems to perform significantly better than ordinary GANs.
* Subjective evaluation of generated images
* Their model seems to learn the rough structure and color correlations of images to generate.
* They add class conditional information to G and D. G indeed learns to generate different classes of images.
* All images still have noticeable distortions.
* Subjective evaluation of generated images by other people
* 15 volunteers.
* They show generated or real images in an interface for 50-2000ms. Volunteer then has to decide whether the image is fake or real.
* 10k ratings were collected.
* At 2000ms, around 50% of the generated images were considered real, ~90 of the true real ones and <10% of the images generated by an ordinary GAN.

Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
