Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp













[link]
#### Goal:
+ Reformulate neural network architecture to address the degratation problem due to the very large number of layers.
#### Motivation:
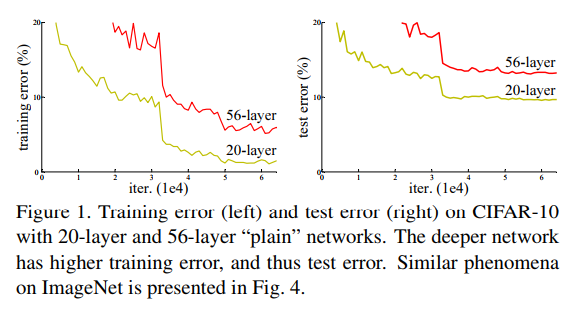
+ Degradation problem:
+ Increasing the depth of the network: accuracy gets saturated and then starts degrading.
+ As number of layers increase: higher training error.
+ In theory, such problem should not occur. Given a neural network, one can add new layers with identity mappings. In reality, optimization algorithms probably have difficulties to find (in feasible time)these solutions.
#### Residual Block:
+ Layers are reformulated as learning residual functions with reference to the layer inputs.

+ Residual Mapping.
+ Neural networks with shortcut connections to perform identity mappings.
+ Identity shortcut connections do no add extra parameters or complexity to the network.
+ The problem can be seen as follows. Given the activation of layer L of a neural net, a[L], one can write the activation at layer L+2 as follows.
a[L+2] = ReLu(W[L+2] * a[L+1] + b[L+2] + a[L])
where W[L+2] is the weight matrix and b[L+2] is the bias vector at layer L+2.
+ The problem of learning an identity mapping is easier in this case, if weight decay is applied, W[L+2] goes to zero, as well as b[L+2]. The activation function at layer a[L+2] = ReLu(a[L]) = a[L].
+ One should take take to match the dimensions. A linear projection of the previous activation function could be used before the sum.
#### Datasets:
+ For the image classification task, two datasets were used: ImageNet and CIFAR-10
|ImageNet|CIFAR-10
----|-----|-----
Training images | 1.2M | 50K
Validation images| 50K | (*)
Testing images | 100K | 10K
Number of classes | 1000 | 10
(*) in the experiments with CIFAR-10, the training images are split into 45K/5K training/validation sets.
#### Experiments and Results
**ImageNet Dataset**
+ Input images:
+ Scale jittering as in [Simonyan2015](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/Very_Deep_Convolutional_Networks_for_Large_Scale_Image_Recognition.md). Image is resized with shorter size sampled to be in between [256, 480].
+ 224x224 crop from image is used.
+ Data augmentation following [Krizhevsky2012](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/ImageNet_Classification_with_Deep_Convolutional_Neural_Networks.md) methodology: image flips, change RGB levels.
+ Training
+ Weight initialization: follows previous work by the authors.
+ Gradient descent with batch normalization, weight decay = 0.0001, momentum = 0.9
+ Mini-batch size = 256
+ Learning rate starts at 0.1 and is divided by 10 when accuracy stop increasing at the validation set.
+ Dropout is not employed
+ Testing
+ Multi-crop procedure from [Krizhevsky2012](https://github.com/tiagotvv/ml-papers/blob/master/convolutional/ImageNet_Classification_with_Deep_Convolutional_Neural_Networks.md) is employed: 10 crops.
+ Fully connected layers are converted into convolutional layers.
+ Average of scores at multiple scales is employed. Testing scales used: {224, 256, 384, 480, 640}.
+ Configurations tested on ImageNet dataset
+ Single Model Results (validation set):
Architecture | top-1 error (%) | top-5 error (%)
----|:-----:|:-----:
VGG (ILSVRC'14) | - | 8.43
GoogLeNet (ILSVRC'14) |- | 7.89
VGG (v5) | 24.4 | 7.1
PReLU-net | 21.59 | 5.71
BN-inception | 21.99 | 5.81
ResNet-34 B (projections + identitites) | 21.84 | 5.71
ResNet-34 (projections) | 21.53 | 5.60
ResNet-50 | 20.74 | 5.25
ResNet-101| 19.87 | 4.60
ResNet-152 | **19.38** | **4.49**
+ Ensemble Models Results (test set):
Architecture | top-5 error (%)
----|:-----:|
VGG (ILSVRC'14) | 7.32
GoogLeNet (ILSVRC'14) | 6.66
VGG (v5) | 6.8
PReLU-net | 4.94
BN-Inception | 4.82
ResNet (ILSVRC'15) | **3.57**
**CIFAR-10 Dataset**
+ Input images:
+ Inputs: 32x32 images
+ Configurations tested on this dataset:
output map size | 32x32 | 16x16 | 8x8
----------------|-------|-------|----
num. layers | 1+2n | 2n | 2n
num. filters | 16 | 32 | 64
+ Shortcuts connected to pairs of 3x3 layers (3n shortcuts)
+ Training
+ Weight initialization: follows previous work by the authors.
+ Gradient descent with batch normalization, weight decay = 0.0001, momentum = 0.9
+ Mini-batch size = 128, 2 GPUs.
+ Learning rate starts at 0.1 and is divided by 10 at 32k and 48k iterations. Stopped at 64k iterations.
+ Dropout is not employed
+ Testing
+ Single 32x32 image
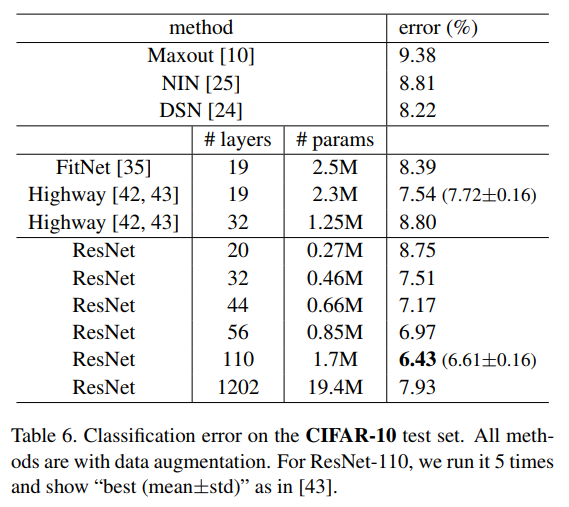
+ Results

Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
