Doctor AI: Predicting Clinical Events via Recurrent Neural Networks
Choi, Edward and Bahadori, Mohammad Taha and Sun, Jimeng
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp
Choi, Edward and Bahadori, Mohammad Taha and Sun, Jimeng
arXiv e-Print archive - 2015 via Local Bibsonomy
Keywords: dblp













[link]
#### Goal:
+ Diagnostic and drug code prediction on a subsequent visit using diagnostic codes, medications, procedures and date of previous visits.
+ Predict when the next visit to the doctor will happen.
#### Dataset:
+ Sutter Health Palo Alto Medical Foundation - primary care - case-control study for heart failure.
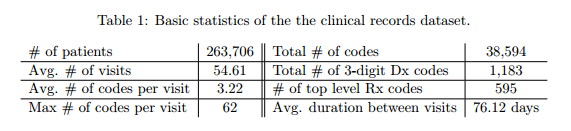
+ Patients with fewer than two visits were excluded.
+ Inputs:
+ ICD-9 codes,
+ GPI drug codes
+ codes for CPT procedures
+ Records are time-stamped with the patient's visiting time.
+ If a patient receives multiple codes on the same visit, they all receive the same timestamp.
+ Granularity of codes - group subcategories:
+ ICD-9 3 digits: 1183 unique codes
+ GPI Drug class: 595 single groups
+ Target: y = [diagnosis, drug] - vector of 1183 + 595 = 1778 dimensions.
#### Architecture:
+ Gated Recurrent Units (GRU)
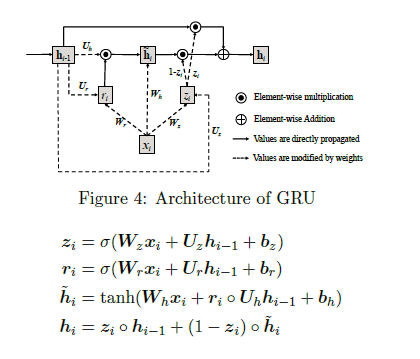")
+ The input vector x is one-hot encoded and has a dimension of 40000. The first layer tries to reduce dimensionality.
+ Two approaches to dimensionality reduction (embedding matrix W_emb)
+ W_emb is learned together with the model.
+ W_emb is pre-trained using techniques such as word2vec.
+ Loss function: cross entropy for codes + quadratic error for forecasting visits.
+ Prediction layer codes: Softmax / Prediction layer of the next time visit: ReLu.
#### Experiments and Results:
+ Code available on GitHub: https://github.com/mp2893/doctorai
+ Implementation in Theano - Training with 2 Nvidia Tesla K80 GPUs
*Methodology*:
+ Dataset split: 85% training, 15% test.
+ RNN trained for 20 epochs.
+ L2 regularization for both the vector of coefficients of the codes and for the vector of coefficients of the next visit (lambda = 0.001) - Dropout between GRU and prediction layer (and between GRU layers if there are more than 1).
+ 2000 neurons in the hidden layer
*Baselines*:
+ Frequency: The codes from the previous visit are repeated on the new visit. Good baseline for the case of patients whose condition tends to stabilize over time.
+ Top k most frequent codes from the previous visit.
+ Logistic Regression and Multilayer Perceptron. Uses the last 5 visits to predict the next.
*Metrics*:
+ top-k recall emulates the behavior of physicians when making a differential diagnosis
top-k recall = # of true positives in the top k predictions / number of true positives
+ R^2 used to evaluate the performance of the next visit prediction.
+ Predict logarithm of time duration between visits to reduce the impact of very long intervals.
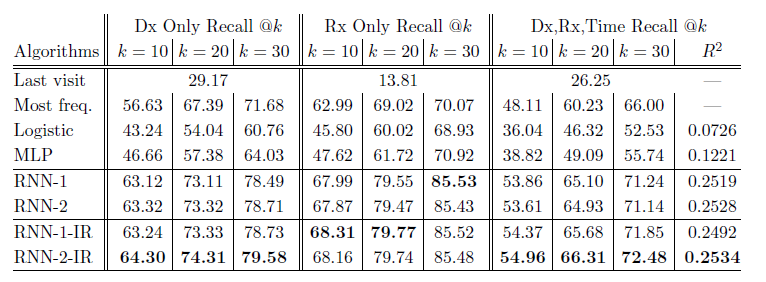
*Results Table*:
+ RNN-1: RNN with a single hidden layer initialized with a random orthogonal matrix for W_emb.
+ RNN-2: RNN with two hidden layers initialized with a random orthogonal matrix for W_emb.
+ RNN-1-IR: RNN using a single hidden layer initialized embedding matrix w emb with the Skip-gram vectors trained on the entire dataset.
+ RNN-2-IR: RNN with two hidden layers initialized embedding matrix W_emb with the Skip-gram vectors trained on the entire dataset.
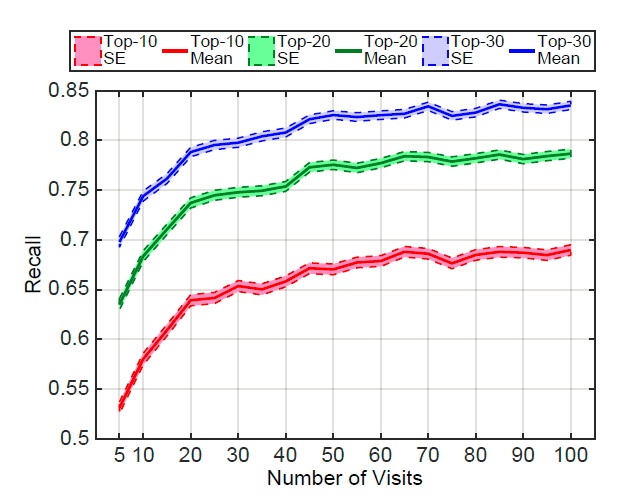
+ Performance varies according to the number of patient visits:
+ Networks learn best when they observe more records.
+ Patients with frequent visits are sicker patients. In a way, it is easier to predict the future in these cases.
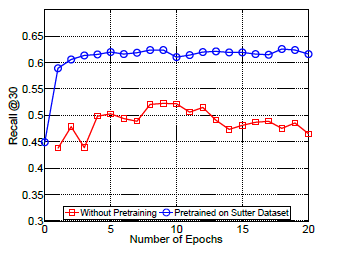
+ Performance of Doctor AI in other datasets:
+ Potential to transfer knowledge accross hospitals. Pre-train Doctor AI on Sutter Health dataset and fine-tuned in MIMIC II dataset.
#### Extras
+ There is an interview about the paper at the [Data Skeptic](https://dataskeptic.com/blog/episodes/2017/doctor-ai) podcast.

Your comment:
|

|
[link]
This paper presents an applications of RNNs to predict "clinical events", such as disease diagnosis and medication prescription and their timing. The paper proposes/suggests: 1. Applying an RNN to disease diagnosis, medication prescription and timing prediction. 2. "Initializing" the neural net with skipgrams instead of one-hot vectors. However, it seems from the description that the authors are not "initializing", rather just feeding a different feature vector into the RNN. 3. Initializing a model that is to be trained on a small corpus from a model trained on a large corpus works. Concludes: information can be transferred between models (read across hospitals).
Your comment:
You must log in before you can post this comment!
|


You must log in before you can submit this summary! Your draft will not be saved!
Preview:
