Cost-Effective Active Learning for Deep Image Classification
Wang, Keze and Zhang, Dongyu and Li, Ya and Zhang, Ruimao and Lin, Liang
IEEE Trans. Circuits Syst. Video Techn. - 2017 via Local Bibsonomy
Keywords: dblp
Wang, Keze and Zhang, Dongyu and Li, Ya and Zhang, Ruimao and Lin, Liang
IEEE Trans. Circuits Syst. Video Techn. - 2017 via Local Bibsonomy
Keywords: dblp













[link]
_Objective:_ Specifically adapt Active Learning to Image Classification with deep learning _Dataset:_ [CARC](https://bcsiriuschen.github.io/CARC/) and [Caltech-256](http://authors.library.caltech.edu/7694/) ## Inner-workings: They labels from two sources: * The most informative/uncertain samples are manually labeled using Least confidence, margin sampling and entropy, see [Active Learning Literature Survey](https://github.com/Deepomatic/papers/issues/192). * The other kind is the samples with high prediction confidence that are automatically labelled. They represent the majority of samples. ## Architecture: [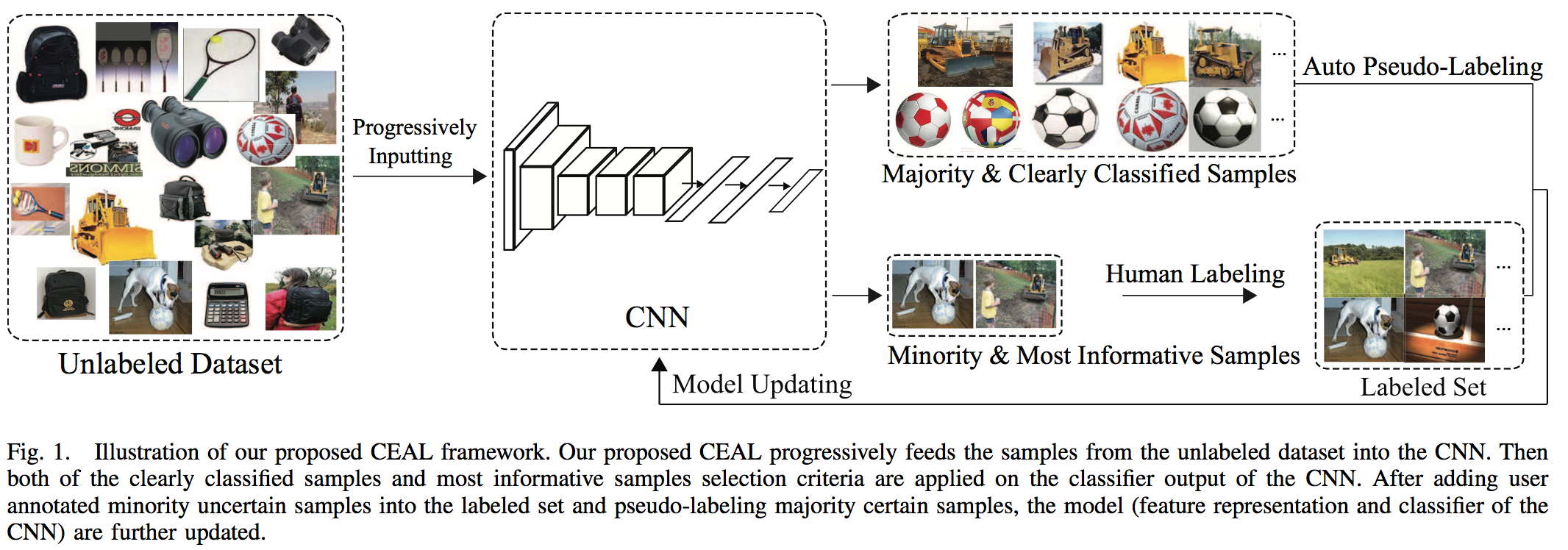](https://user-images.githubusercontent.com/17261080/27691277-d4547196-5ce3-11e7-849c-aadd30d71d68.png) They proceed with the following steps: 1. Initialization: they manually annotate a given number of images for each class in order to pre-trained the network. 2. Complementary sample selection: they fix the network, identity the most uncertain label for manual annotation and automatically annotate the most certain one if their entropy is higher than a given threshold. 3. CNN fine-tuning: they train the network using the whole pool of already labeled data and pseudo-labeled. Then they put all the automatically labeled images back into the unlabelled pool. 4. Threshold updating: as the network gets more and more confident the threshold for auto-labelling is linearly reducing. The idea is that the network gets a more reliable representation and its trustability increases. ## Results: Roughly divide by 2 the number of annotation needed. ⚠️ I don't feel like this paper can be trusted 100% ⚠️ 
Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
