Active Learning Literature Survey
Settles, Burr
- 2009 via Local Bibsonomy
Keywords: machine_learning, active_learning, survey
Settles, Burr
- 2009 via Local Bibsonomy
Keywords: machine_learning, active_learning, survey













[link]
Very good introduction to active learning. #### Scenarios There are three mains scenari: * Pool-based: a large amount of unlabeled data is available and we need to chose which one to annotate next. * Stream-based: same as above except example come one after the other. * Membership query synthesis: we can generate the point to label. #### Query Strategy Frameworks 2.1. Uncertainty Sampling Basically how to evaluate the informativeness of unlabeled instances and then select the most informative. 2.1.1. Least Confident Query the instances about which the algorithm is least certain how to label. [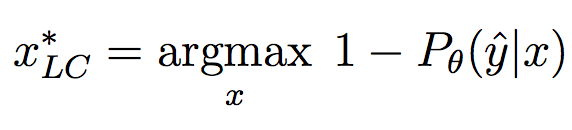](https://user-images.githubusercontent.com/17261080/27139765-281f1374-5124-11e7-9418-fb458be0bfc3.png) [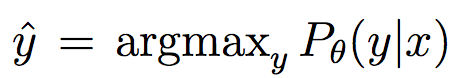](https://user-images.githubusercontent.com/17261080/27139841-5636458e-5124-11e7-95c4-ea586deb853a.png) Most used by discard information on all other labels. 2.1.2. Margin Sampling Use the first two labels and chose the instance for which the different between the two is the smallest. [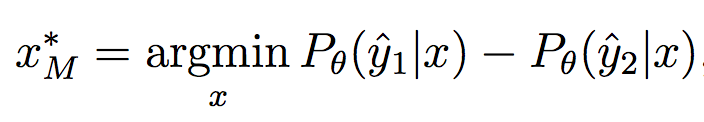](https://user-images.githubusercontent.com/17261080/27139968-aabebe6a-5124-11e7-879b-f518e2279eba.png) 2.1.3. Entropy Instead of using the two first labels, why not use all of them? [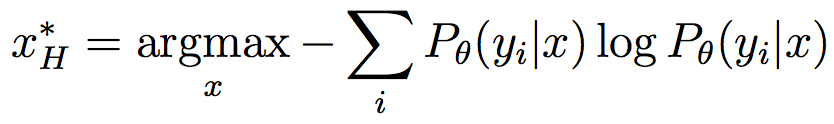](https://user-images.githubusercontent.com/17261080/27140049-e33ea25a-5124-11e7-84ea-adab87d29174.png) #### Query-By-Committee A committee of different models is trained. They then vote on which instance to label and the one for which they most disagree is chosen. To measure the level of disagreement, one can either use: * Vote entropy: [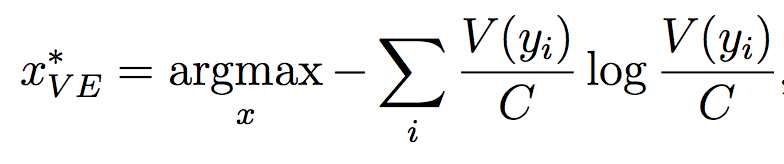](https://user-images.githubusercontent.com/17261080/27140436-d12d330a-5125-11e7-8f40-7be3bbc83987.png) * Kullback-Leibler divergence: [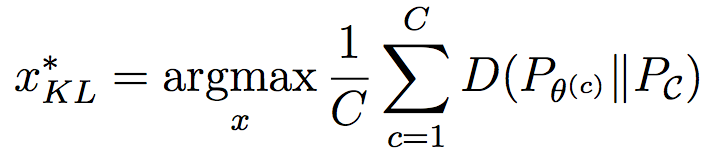](https://user-images.githubusercontent.com/17261080/27140492-f45be722-5125-11e7-9b42-204aaf4bdd92.png) [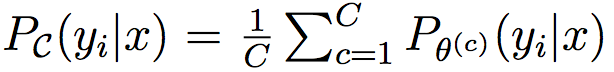](https://user-images.githubusercontent.com/17261080/27140537-12289cd2-5126-11e7-8e1d-62158576cd95.png) #### Expected Model Change Selects the instance that would impart the greatest change to the current model if we knew its label. * Expected Gradient Length: compute the gradient for all instances and find the one with the largest magnitude on average for all labels. [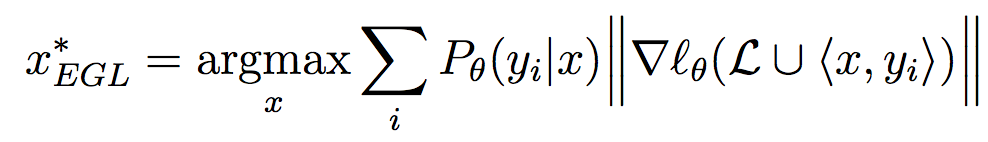](https://user-images.githubusercontent.com/17261080/27140694-79cc6e4a-5126-11e7-9314-e837a1e0eba2.png) #### Expected Error Reduction Measure not how much the model is likely to change, but how much its generalization error is likely to be reduced. Either by measuring: * Expected 0/1 loss: to reduce the expected total number of incorrect predictions. A new model needs to be trained for every label and instance, very greedy. [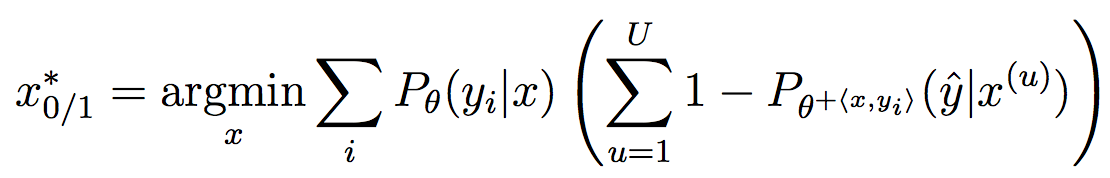](https://user-images.githubusercontent.com/17261080/27140912-08d7410a-5127-11e7-9d53-33f2044692a2.png) * Expected Log-Loss: maximizing the expected information gain of the query. Still very greedy in computation! Not really usable except if the model can be analytically resolved instead of re-trained. [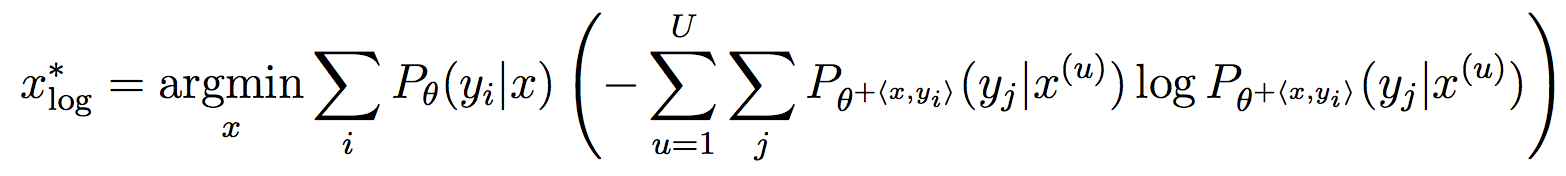](https://user-images.githubusercontent.com/17261080/27140970-3e117516-5127-11e7-9936-671fea5d94dd.png) #### Variance Reduction Reduce generalization error indirectly by minimizing the output variance. [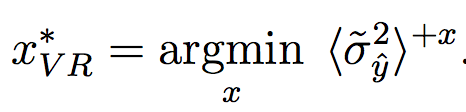](https://user-images.githubusercontent.com/17261080/27141417-6507b71a-5128-11e7-81ca-ab227836098f.png) #### Density-Weighted Methods [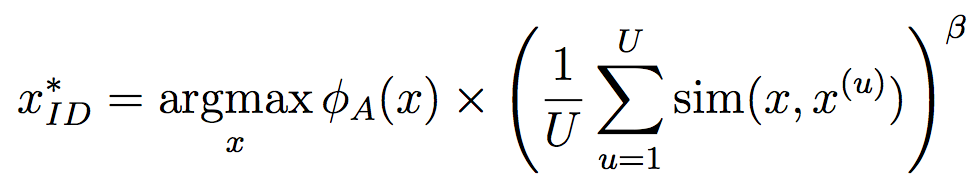](https://user-images.githubusercontent.com/17261080/27141501-a920bd34-5128-11e7-8e9d-0870da365633.png) With the left function is the informativeness of x and the right function represents average similarity to all other instances in the input distribution 
Your comment:
|

You must log in before you can submit this summary! Your draft will not be saved!
Preview:
