
|
Welcome to ShortScience.org! |


|
- ShortScience.org is a platform for post-publication discussion aiming to improve accessibility and reproducibility of research ideas.
- The website has 1584 public summaries, mostly in machine learning, written by the community and organized by paper, conference, and year.
- Reading summaries of papers is useful to obtain the perspective and insight of another reader, why they liked or disliked it, and their attempt to demystify complicated sections.
- Also, writing summaries is a good exercise to understand the content of a paper because you are forced to challenge your assumptions when explaining it.
- Finally, you can keep up to date with the flood of research by reading the latest summaries on our Twitter and Facebook pages.
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih and Koray Kavukcuoglu and David Silver and Alex Graves and Ioannis Antonoglou and Daan Wierstra and Martin Riedmiller
arXiv e-Print archive - 2013 via Local arXiv
Keywords: cs.LG
First published: 2013/12/19 (12 years ago)
Abstract: We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.
more
less
Volodymyr Mnih and Koray Kavukcuoglu and David Silver and Alex Graves and Ioannis Antonoglou and Daan Wierstra and Martin Riedmiller
arXiv e-Print archive - 2013 via Local arXiv
Keywords: cs.LG
First published: 2013/12/19 (12 years ago)
Abstract: We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.













[link]
* They use an implementation of Q-learning (i.e. reinforcement learning) with CNNs to automatically play Atari games.
* The algorithm receives the raw pixels as its input and has to choose buttons to press as its output. No hand-engineered features are used. So the model "sees" the game and "uses" the controller, just like a human player would.
* The model achieves good results on various games, beating all previous techniques and sometimes even surpassing human players.
### How
* Deep Q Learning
* *This is yet another explanation of deep Q learning, see also [this blog post](http://www.nervanasys.com/demystifying-deep-reinforcement-learning/) for longer explanation.*
* While playing, sequences of the form (`state1`, `action1`, `reward`, `state2`) are generated.
* `state1` is the current game state. The agent only sees the pixels of that state. (Example: Screen shows enemy.)
* `action1` is an action that the agent chooses. (Example: Shoot!)
* `reward` is the direct reward received for picking `action1` in `state1`. (Example: +1 for a kill.)
* `state2` is the next game state, after the action was chosen in `state1`. (Example: Screen shows dead enemy.)
* One can pick actions at random for some time to generate lots of such tuples. That leads to a replay memory.
* Direct reward
* After playing randomly for some time, one can train a model to predict the direct reward given a screen (we don't want to use the whole state, just the pixels) and an action, i.e. `Q(screen, action) -> direct reward`.
* That function would need a forward pass for each possible action that we could take. So for e.g. 8 buttons that would be 8 forward passes. To make things more efficient, we can let the model directly predict the direct reward for each available action, e.g. for 3 buttons `Q(screen) -> (direct reward of action1, direct reward of action2, direct reward of action3)`.
* We can then sample examples from our replay memory. The input per example is the screen. The output is the reward as a tuple. E.g. if we picked button 1 of 3 in one example and received a reward of +1 then our output/label for that example would be `(1, 0, 0)`.
* We can then train the model by playing completely randomly for some time, then sample some batches and train using a mean squared error. Then play a bit less randomly, i.e. start to use the action which the network thinks would generate the highest reward. Then train again, and so on.
* Indirect reward
* Doing the previous steps, the model will learn to anticipate the *direct* reward correctly. However, we also want it to predict indirect rewards. Otherwise, the model e.g. would never learn to shoot rockets at enemies, because the reward from killing an enemy would come many frames later.
* To learn the indirect reward, one simply adds the reward value of highest reward action according to `Q(state2)` to the direct reward.
* I.e. if we have a tuple (`state1`, `action1`, `reward`, `state2`), we would not add (`state1`, `action1`, `reward`) to the replay memory, but instead (`state1`, `action1`, `reward + highestReward(Q(screen2))`). (Where `highestReward()` returns the reward of the action with the highest reward according to Q().)
* By training to predict `reward + highestReward(Q(screen2))` the network learns to anticipate the direct reward *and* the indirect reward. It takes a leap of faith to accept that this will ever converge to a good solution, but it does.
* We then add `gamma` to the equation: `reward + gamma*highestReward(Q(screen2))`. `gamma` may be set to 0.9. It is a discount factor that devalues future states, e.g. because the world is not deterministic and therefore we can't exactly predict what's going to happen. Note that Q will automatically learn to stack it, e.g. `state3` will be discounted to `gamma^2` at `state1`.
* This paper
* They use the mentioned Deep Q Learning to train their model Q.
* They use a k-th frame technique, i.e. they let the model decide upon an action at (here) every 4th frame.
* Q is implemented via a neural net. It receives 84x84x4 grayscale pixels that show the game and projects that onto the rewards of 4 to 18 actions.
* The input is HxWx4 because they actually feed the last 4 frames into the network, instead of just 1 frame. So the network knows more about what things are moving how.
* The network architecture is:
* 84x84x4 (input)
* 16 convs, 8x8, stride 4, ReLU
* 32 convs, 4x4, stride 2, ReLU
* 256 fully connected neurons, ReLU
* <N_actions> fully connected neurons, linear
* They use a replay memory of 1 million frames.
### Results
* They ran experiments on the Atari games Beam Rider, Breakout, Enduro, Pong, Qbert, Seaquest and Space Invaders.
* Same architecture and hyperparameters for all games.
* Rewards were based on score changes in the games, i.e. they used +1 (score increases) and -1 (score decreased).
* Optimizer: RMSProp, Batch Size: 32.
* Trained for 10 million examples/frames per game.
* They had no problems with instability and their average Q value per game increased smoothly.
* Their method beats all other state of the art methods.
* They managed to beat a human player in games that required not so much "long" term strategies (the less frames the better).
* Video: starts at 46:05.
https://youtu.be/dV80NAlEins?t=46m05s

*The original full algorithm, as shown in the paper.*
--------------------
### Rough chapter-wise notes
* (1) Introduction
* Problems when using neural nets in reinforcement learning (RL):
* Reward signal is often sparse, noise and delayed.
* Often assumption that data samples are independent, while they are correlated in RL.
* Data distribution can change when the algorithm learns new behaviours.
* They use Q-learning with a CNN and stochastic gradient descent.
* They use an experience replay mechanism (i.e. memory) from which they can sample previous transitions (for training).
* They apply their method to Atari 2600 games in the Arcade Learning Environment (ALE).
* They use only the visible pixels as input to the network, i.e. no manual feature extraction.
* (2) Background
* blablabla, standard deep q learning explanation
* (3) Related Work
* TD-Backgammon: "Solved" backgammon. Worked similarly to Q-learning and used a multi-layer perceptron.
* Attempts to copy TD-Backgammon to other games failed.
* Research was focused on linear function approximators as there were problems with non-linear ones diverging.
* Recently again interest in using neural nets for reinforcement learning. Some attempts to fix divergence problems with gradient temporal-difference methods.
* NFQ is a very similar method (to the one in this paper), but worked on the whole batch instead of minibatches, making it slow. It also first applied dimensionality reduction via autoencoders on the images instead of training on them end-to-end.
* HyperNEAT was applied to Atari games and evolved a neural net for each game. The networks learned to exploit design flaws.
* (4) Deep Reinforcement Learning
* They want to connect a reinforcement learning algorithm with a deep neural network, e.g. to get rid of handcrafted features.
* The network is supposes to run on the raw RGB images.
* They use experience replay, i.e. store tuples of (pixels, chosen action, received reward) in a memory and use that during training.
* They use Q-learning.
* They use an epsilon-greedy policy.
* Advantages from using experience replay instead of learning "live" during game playing:
* Experiences can be reused many times (more efficient).
* Samples are less correlated.
* Learned parameters from one batch don't determine as much the distributions of the examples in the next batch.
* They save the last N experiences and sample uniformly from them during training.
* (4.1) Preprocessing and Model Architecture
* Raw Atari images are 210x160 pixels with 128 possible colors.
* They downsample them to 110x84 pixels and then crop the 84x84 playing area out of them.
* They also convert the images to grayscale.
* They use the last 4 frames as input and stack them.
* So their network input has shape 84x84x4.
* They use one output neuron per possible action. So they can compute the Q-value (expected reward) of each action with one forward pass.
* Architecture: 84x84x4 (input) => 16 8x8 convs, stride 4, ReLU => 32 4x4 convs stride 2 ReLU => fc 256, ReLU => fc N actions, linear
* 4 to 18 actions/outputs (depends on the game).
* Aside from the outputs, the architecture is the same for all games.
* (5) Experiments
* Games that they played: Beam Rider, Breakout, Enduro, Pong, Qbert, Seaquest, Space Invaders
* They use the same architecture und hyperparameters for all games.
* They give a reward of +1 whenever the in-game score increases and -1 whenever it decreases.
* They use RMSProp.
* Mini batch size was 32.
* They train for 10 million frames/examples.
* They initialize epsilon (in their epsilon greedy strategy) to 1.0 and decrease it linearly to 0.1 at one million frames.
* They let the agent decide upon an action at every 4th in-game frame (3rd in space invaders).
* (5.1) Training and stability
* They plot the average reward und Q-value per N games to evaluate the agent's training progress,
* The average reward increases in a noisy way.
* The average Q value increases smoothly.
* They did not experience any divergence issues during their training.
* (5.2) Visualizating the Value Function
* The agent learns to predict the value function accurately, even for rather long sequences (here: ~25 frames).
* (5.3) Main Evaluation
* They compare to three other methods that use hand-engineered features and/or use the pixel data combined with significant prior knownledge.
* They mostly outperform the other methods.
* They managed to beat a human player in three games. The ones where the human won seemed to require strategies that stretched over longer time frames.
 |

Noisy Activation Functions
Gülçehre, Çaglar and Moczulski, Marcin and Denil, Misha and Bengio, Yoshua
International Conference on Machine Learning - 2016 via Local Bibsonomy
Keywords: dblp
Gülçehre, Çaglar and Moczulski, Marcin and Denil, Misha and Bengio, Yoshua
International Conference on Machine Learning - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
* Certain activation functions, mainly sigmoid, tanh, hard-sigmoid and hard-tanh can saturate.
* That means that their gradient is either flat 0 after threshold values (e.g. -1 and +1) or that it approaches zero for high/low values.
* If there's no gradient, training becomes slow or stops completely.
* That's a problem, because sigmoid, tanh, hard-sigmoid and hard-tanh are still often used in some models, like LSTMs, GRUs or Neural Turing Machines.
* To fix the saturation problem, they add noise to the output of the activation functions.
* The noise increases as the unit saturates.
* Intuitively, once the unit is saturating, it will occasionally "test" an activation in the non-saturating regime to see if that output performs better.
### How
* The basic formula is: `phi(x,z) = alpha*h(x) + (1-alpha)u(x) + d(x)std(x)epsilon`
* Variables in that formula:
* Non-linear part `alpha*h(x)`:
* `alpha`: A constant hyperparameter that determines the "direction" of the noise and the slope. Values below 1.0 let the noise point away from the unsaturated regime. Values <=1.0 let it point towards the unsaturated regime (higher alpha = stronger noise).
* `h(x)`: The original activation function.
* Linear part `(1-alpha)u(x)`:
* `u(x)`: First-order Taylor expansion of h(x).
* For sigmoid: `u(x) = 0.25x + 0.5`
* For tanh: `u(x) = x`
* For hard-sigmoid: `u(x) = max(min(0.25x+0.5, 1), 0)`
* For hard-tanh: `u(x) = max(min(x, 1), -1)`
* Noise/Stochastic part `d(x)std(x)epsilon`:
* `d(x) = -sgn(x)sgn(1-alpha)`: Changes the "direction" of the noise.
* `std(x) = c(sigmoid(p*v(x))-0.5)^2 = c(sigmoid(p*(h(x)-u(x)))-0.5)^2`
* `c` is a hyperparameter that controls the scale of the standard deviation of the noise.
* `p` controls the magnitude of the noise. Due to the `sigmoid(y)-0.5` this can influence the sign. `p` is learned.
* `epsilon`: A noise creating random variable. Usually either a Gaussian or the positive half of a Gaussian (i.e. `z` or `|z|`).
* The hyperparameter `c` can be initialized at a high value and then gradually decreased over time. That would be comparable to simulated annealing.
* Noise could also be applied to the input, i.e. `h(x)` becomes `h(x + noise)`.
### Results
* They replaced sigmoid/tanh/hard-sigmoid/hard-tanh units in various experiments (without further optimizations).
* The experiments were:
* Learn to execute source code (LSTM?)
* Language model from Penntreebank (2-layer LSTM)
* Neural Machine Translation engine trained on Europarl (LSTM?)
* Image caption generation with soft attention trained on Flickr8k (LSTM)
* Counting unique integers in a sequence of integers (LSTM)
* Associative recall (Neural Turing Machine)
* Noisy activations practically always led to a small or moderate improvement in resulting accuracy/NLL/BLEU.
* In one experiment annealed noise significantly outperformed unannealed noise, even beating careful curriculum learning. (Somehow there are not more experiments about that.)
* The Neural Turing Machine learned far faster with noisy activations and also converged to a much better solution.

*Hard-tanh with noise for various alphas. Noise increases in different ways in the saturing regimes.*

*Performance during training of a Neural Turing Machine with and without noisy activation units.*
--------------------
# Rough chapter-wise notes
* (1) Introduction
* ReLU and Maxout activation functions have improved the capabilities of training deep networks.
* Previously, tanh and sigmoid were used, which were only suited for shallow networks, because they saturate, which kills the gradient.
* They suggest a different avenue: Use saturating nonlinearities, but inject noise when they start to saturate (and let the network learn how much noise is "good").
* The noise allows to train deep networks with saturating activation functions.
* Many current architectures (LSTMs, GRUs, Neural Turing Machines, ...) require "hard" decisions (yes/no). But they use "soft" activation functions to implement those, because hard functions lack gradient.
* The soft activation functions can still saturate (no more gradient) and don't match the nature of the binary decision problem. So it would be good to replace them with something better.
* They instead use hard activation functions and compensate for the lack of gradient by using noise (during training).
* Networks with hard activation functions outperform those with soft ones.
* (2) Saturating Activation Functions
* Activation Function = A function that maps a real value to a new real value and is differentiable almost everywhere.
* Right saturation = The gradient of an activation function becomes 0 if the input value goes towards infinity.
* Left saturation = The gradient of an activation function becomes 0 if the input value goes towards -infinity.
* Saturation = A activation function saturates if it right-saturates and left-saturates.
* Hard saturation = If there is a constant c for which for which the gradient becomes 0.
* Soft saturation = If there is no constant, i.e. the input value must become +/- infinity.
* Soft saturating activation functions can be converted to hard saturating ones by using a first-order Taylor expansion and then clipping the values to the required range (e.g. 0 to 1).
* A hard activating tanh is just `f(x) = x`. With clipping to [-1, 1]: `max(min(f(x), 1), -1)`.
* The gradient for hard activation functions is 0 above/below certain constants, which will make training significantly more challenging.
* hard-sigmoid, sigmoid and tanh are contractive mappings, hard-tanh for some reason only when it's greater than the threshold.
* The fixed-point for tanh is 0, for the others !=0. That can have influences on the training performance.
* (3) Annealing with Noisy Activation Functions
* Suppose that there is an activation function like hard-sigmoid or hard-tanh with additional noise (iid, mean=0, variance=std^2).
* If the noise's `std` is 0 then the activation function is the original, deterministic one.
* If the noise's `std` is very high then the derivatives and gradient become high too. The noise then "drowns" signal and the optimizer just moves randomly through the parameter space.
* Let the signal to noise ratio be `SNR = std_signal / std_noise`. So if SNR is low then noise drowns the signal and exploration is random.
* By letting SNR grow (i.e. decreaseing `std_noise`) we switch the model to fine tuning mode (less coarse exploration).
* That is similar to simulated annealing, where noise is also gradually decreased to focus on better and better regions of the parameter space.
* (4) Adding Noise when the Unit Saturate
* This approach does not always add the same noise. Instead, noise is added proportinally to the saturation magnitude. More saturation, more noise.
* That results in a clean signal in "good" regimes (non-saturation, strong gradients) and a noisy signal in "bad" regimes (saturation).
* Basic activation function with noise: `phi(x, z) = h(x) + (mu + std(x)*z)`, where `h(x)` is the saturating activation function, `mu` is the mean of the noise, `std` is the standard deviation of the noise and `z` is a random variable.
* Ideally the noise is unbiased so that the expectation values of `phi(x,z)` and `h(x)` are the same.
* `std(x)` should take higher values as h(x) enters the saturating regime.
* To calculate how "saturating" a activation function is, one can `v(x) = h(x) - u(x)`, where `u(x)` is the first-order Taylor expansion of `h(x)`.
* Empirically they found that a good choice is `std(x) = c(sigmoid(p*v(x)) - 0.5)^2` where `c` is a hyperparameter and `p` is learned.
* (4.1) Derivatives in the Saturated Regime
* For values below the threshold, the gradient of the noisy activation function is identical to the normal activation function.
* For values above the threshold, the gradient of the noisy activation function is `phi'(x,z) = std'(x)*z`. (Assuming that z is unbiased so that mu=0.)
* (4.2) Pushing Activations towards the Linear Regime
* In saturated regimes, one would like to have more of the noise point towards the unsaturated regimes than away from them (i.e. let the model try often whether the unsaturated regimes might be better).
* To achieve this they use the formula `phi(x,z) = alpha*h(x) + (1-alpha)u(x) + d(x)std(x)epsilon`
* `alpha`: A constant hyperparameter that determines the "direction" of the noise and the slope. Values below 1.0 let the noise point away from the unsaturated regime. Values <=1.0 let it point towards the unsaturated regime (higher alpha = stronger noise).
* `h(x)`: The original activation function.
* `u(x)`: First-order Taylor expansion of h(x).
* `d(x) = -sgn(x)sgn(1-alpha)`: Changes the "direction" of the noise.
* `std(x) = c(sigmoid(p*v(x))-0.5)^2 = c(sigmoid(p*(h(x)-u(x)))-0.5)^2` with `c` being a hyperparameter and `p` learned.
* `epsilon`: Either `z` or `|z|`. If `z` is a Gaussian, then `|z|` is called "half-normal" while just `z` is called "normal". Half-normal lets the noise only point towards one "direction" (towards the unsaturated regime or away from it), while normal noise lets it point in both directions (with the slope being influenced by `alpha`).
* The formula can be split into three parts:
* `alpha*h(x)`: Nonlinear part.
* `(1-alpha)u(x)`: Linear part.
* `d(x)std(x)epsilon`: Stochastic part.
* Each of these parts resembles a path along which gradient can flow through the network.
* During test time the activation function is made deterministic by using its expectation value: `E[phi(x,z)] = alpha*h(x) + (1-alpha)u(x) + d(x)std(x)E[epsilon]`.
* If `z` is half-normal then `E[epsilon] = sqrt(2/pi)`. If `z` is normal then `E[epsilon] = 0`.
* (5) Adding Noise to Input of the Function
* Noise can also be added to the input of an activation function, i.e. `h(x)` becomes `h(x + noise)`.
* The noise can either always be applied or only once the input passes a threshold.
* (6) Experimental Results
* They applied noise only during training.
* They used existing setups and just changed the activation functions to noisy ones. No further optimizations.
* `p` was initialized uniformly to [-1,1].
* Basic experiment settings:
* NAN: Normal noise applied to the outputs.
* NAH: Half-normal noise, i.e. `|z|`, i.e. noise is "directed" towards the unsaturated or satured regime.
* NANI: Normal noise applied to the *input*, i.e. `h(x+noise)`.
* NANIL: Normal noise applied to the input with learned variance.
* NANIS: Normal noise applied to the input, but only if the unit saturates (i.e. above/below thresholds).
* (6.1) Exploratory analysis
* A very simple MNIST network performed slightly better with noisy activations than without. But comparison was only to tanh and hard-tanh, not ReLU or similar.
* In an experiment with a simple GRU, NANI (noisy input) and NAN (noisy output) performed practically identical. NANIS (noisy input, only when saturated) performed significantly worse.
* (6.2) Learning to Execute
* Problem setting: Predict the output of some lines of code.
* They replaced sigmoids and tanhs with their noisy counterparts (NAH, i.e. half-normal noise on output). The model learned faster.
* (6.3) Penntreebank Experiments
* They trained a standard 2-layer LSTM language model on Penntreebank.
* Their model used noisy activations, as opposed to the usually non-noisy ones.
* They could improve upon the previously best value. Normal noise and half-normal noise performed roughly the same.
* (6.4) Neural Machine Translation Experiments
* They replaced all sigmoids and tanh units in the Neural Attention Model with noisy ones. Then they trained on the Europarl corpus.
* They improved upon the previously best score.
* (6.5) Image Caption Generation Experiments
* They train a network with soft attention to generate captions for the Flickr8k dataset.
* Using noisy activation units improved the result over normal sigmoids and tanhs.
* (6.6) Experiments with Continuation
* They build an LSTM and train it to predict how many unique integers there are in a sequence of random integers.
* Instead of using a constant value for hyperparameter `c` of the noisy activations (scale of the standard deviation of the noise), they start at `c=30` and anneal down to `c=0.5`.
* Annealed noise performed significantly better then unannealed noise.
* Noise applied to the output (NAN) significantly beat noise applied to the input (NANIL).
* In a second experiment they trained a Neural Turing Machine on the associative recall task.
* Again they used annealed noise.
* The NTM with annealed noise learned by far faster than the one without annealed noise and converged to a perfect solution.
|
Artistic style transfer for videos
Manuel Ruder and Alexey Dosovitskiy and Thomas Brox
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CV
First published: 2016/04/28 (10 years ago)
Abstract: In the past, manually re-drawing an image in a certain artistic style required a professional artist and a long time. Doing this for a video sequence single-handed was beyond imagination. Nowadays computers provide new possibilities. We present an approach that transfers the style from one image (for example, a painting) to a whole video sequence. We make use of recent advances in style transfer in still images and propose new initializations and loss functions applicable to videos. This allows us to generate consistent and stable stylized video sequences, even in cases with large motion and strong occlusion. We show that the proposed method clearly outperforms simpler baselines both qualitatively and quantitatively.
more
less
Manuel Ruder and Alexey Dosovitskiy and Thomas Brox
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CV
First published: 2016/04/28 (10 years ago)
Abstract: In the past, manually re-drawing an image in a certain artistic style required a professional artist and a long time. Doing this for a video sequence single-handed was beyond imagination. Nowadays computers provide new possibilities. We present an approach that transfers the style from one image (for example, a painting) to a whole video sequence. We make use of recent advances in style transfer in still images and propose new initializations and loss functions applicable to videos. This allows us to generate consistent and stable stylized video sequences, even in cases with large motion and strong occlusion. We show that the proposed method clearly outperforms simpler baselines both qualitatively and quantitatively.
|
[link]
https://www.youtube.com/watch?v=vQk_Sfl7kSc&feature=youtu.be
* The paper describes a method to transfer the style (e.g. choice of colors, structure of brush strokes) of an image to a whole video.
* The method is designed so that the transfered style is consistent over many frames.
* Examples for such consistency:
* No flickering of style between frames. So the next frame has always roughly the same style in the same locations.
* No artefacts at the boundaries of objects, even if they are moving.
* If an area gets occluded and then unoccluded a few frames later, the style of that area is still the same as before the occlusion.
### How
* Assume that we have a frame to stylize $x$ and an image from which to extract the style $a$.
* The basic process is the same as in the original Artistic Style Transfer paper, they just add a bit on top of that.
* They start with a gaussian noise image $x'$ and change it gradually so that a loss function gets minimized.
* The loss function has the following components:
* Content loss *(old, same as in the Artistic Style Transfer paper)*
* This loss makes sure that the content in the generated/stylized image still matches the content of the original image.
* $x$ and $x'$ are fed forward through a pretrained network (VGG in their case).
* Then the generated representations of the intermediate layers of the network are extracted/read.
* One or more layers are picked and the difference between those layers for $x$ and $x'$ is measured via a MSE.
* E.g. if we used only the representations of the layer conv5 then we would get something like `(conv5(x) - conv5(x'))^2` per example. (Where conv5() also executes all previous layers.)
* Style loss *(old)*
* This loss makes sure that the style of the generated/stylized image matches the style source $a$.
* $x'$ and $a$ are fed forward through a pretrained network (VGG in their case).
* Then the generated representations of the intermediate layers of the network are extracted/read.
* One or more layers are picked and the Gram Matrices of those layers are calculated.
* Then the difference between those matrices is measured via a MSE.
* Temporal loss *(new)*
* This loss enforces consistency in style between a pair of frames.
* The main sources of inconsistency are boundaries of moving objects and areas that get unonccluded.
* They use the optical flow to detect motion.
* Applying an optical flow method to two frames $(i, i+1)$ returns per pixel the movement of that pixel, i.e. if the pixel at $(x=1, y=2)$ moved to $(x=2, y=4)$ the optical flow at that pixel would be $(u=1, v=2)$.
* The optical flow can be split into the forward flow (here `fw`) and the backward flow (here `bw`). The forward flow is the flow from frame i to i+1 (as described in the previous point). The backward flow is the flow from frame $i+1$ to $i$ (reverse direction in time).
* Boundaries
* At boundaries of objects the derivative of the flow is high, i.e. the flow "suddenly" changes significantly from one pixel to the other.
* So to detect boundaries they use (per pixel) roughly the equation `gradient(u)^2 + gradient(v)^2 > length((u,v))`.
* Occlusions and disocclusions
* If a pixel does not get occluded/disoccluded between frames, the optical flow method should be able to correctly estimate the motion of that pixel between the frames. The forward and backward flows then should be roughly equal, just in opposing directions.
* If a pixel does get occluded/disoccluded between frames, it will not be visible in one the two frames and therefore the optical flow method cannot reliably estimate the motion for that pixel. It is then expected that the forward and backward flow are unequal.
* To measure that effect they roughly use (per pixel) a formula matching `length(fw + bw)^2 > length(fw)^2 + length(bw)^2`.
* Mask $c$
* They create a mask $c$ with the size of the frame.
* For every pixel they estimate whether the boundary-equation *or* the disocclusion-equation is true.
* If either of them is true, they add a 0 to the mask, otherwise a 1. So the mask is 1 wherever there is *no* disocclusion or motion boundary.
* Combination
* The final temporal loss is the mean (over all pixels) of $c*(x-w)^2$.
* $x$ is the frame to stylize.
* $w$ is the previous *stylized* frame (frame i-1), warped according to the optical flow between frame i-1 and i.
* `c` is the mask value at the pixel.
* By using the difference `x-w` they ensure that the difference in styles between two frames is low.
* By adding `c` they ensure the style-consistency only at pixels that probably should have a consistent style.
* Long-term loss *(new)*
* This loss enforces consistency in style between pairs of frames that are longer apart from each other.
* It is a simple extension of the temporal (short-term) loss.
* The temporal loss was computed for frames (i-1, i). The long-term loss is the sum of the temporal losses for the frame pairs {(i-4,i), (i-2,i), (i-1,i)}.
* The $c$ mask is recomputed for every pair and 1 if there are no boundaries/disocclusions detected, but only if there is not a 1 for the same pixel in a later mask. The additional condition is intended to associate pixels with their closest neighbours in time to minimize possible errors.
* Note that the long-term loss can completely replace the temporal loss as the latter one is contained in the former one.
* Multi-pass approach *(new)*
* They had problems with contrast around the boundaries of the frames.
* To combat that, they use a multi-pass method in which they seem to calculate the optical flow in multiple forward and backward passes? (Not very clear here what they do and why it would help.)
* Initialization with previous frame *(new)*
* Instead of starting at a gaussian noise image every time, they instead use the previous stylized frame.
* That immediately leads to more similarity between the frames.
|
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification
Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa
ACM Transactions on Graphics (Proc. of SIGGRAPH 2016) - 2016 via Local
Keywords:
Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa
ACM Transactions on Graphics (Proc. of SIGGRAPH 2016) - 2016 via Local
Keywords:
|
[link]
* They present a model which adds color to grayscale images (e.g. to old black and white images).
* It works best with 224x224 images, but can handle other sizes too.
### How
* Their model has three feature extraction components:
* Low level features:
* Receives 1xHxW images and outputs 512xH/8xW/8 matrices.
* Uses 6 convolutional layers (3x3, strided, ReLU) for that.
* Global features:
* Receives the low level features and converts them to 256 dimensional vectors.
* Uses 4 convolutional layers (3x3, strided, ReLU) and 3 fully connected layers (1024 -> 512 -> 256; ReLU) for that.
* Mid-level features:
* Receives the low level features and converts them to 256xH/8xW/8 matrices.
* Uses 2 convolutional layers (3x3, ReLU) for that.
* The global and mid-level features are then merged with a Fusion Layer.
* The Fusion Layer is basically an extended convolutional layer.
* It takes the mid-level features (256xH/8xW/8) and the global features (256) as input and outputs a matrix of shape 256xH/8xW/8.
* It mostly operates like a normal convolutional layer on the mid-level features. However, its weight matrix is extended to also include weights for the global features (which will be added at every pixel).
* So they use something like `fusion at pixel u,v = sigmoid(bias + weights * [global features, mid-level features at pixel u,v])` - and that with 256 different weight matrices and biases for 256 filters.
* After the Fusion Layer they use another network to create the coloring:
* This network receives 256xH/8xW/8 matrices (merge of global and mid-level features) and generates 2xHxW outputs (color in L\*a\*b\* color space).
* It uses a few convolutional layers combined with layers that do nearest neighbour upsampling.
* The loss for the colorization network is a MSE based on the true coloring.
* They train the global feature extraction also on the true class labels of the used images.
* Their model can handle any sized image. If the image doesn't have a size of 224x224, it must be resized to 224x224 for the gobal feature extraction. The mid-level feature extraction only uses convolutions, therefore it can work with any image size.
### Results
* The training set that they use is the "Places scene dataset".
* After cleanup the dataset contains 2.3M training images (205 different classes) and 19k validation images.
* Users rate images colored by their method in 92.6% of all cases as real-looking (ground truth: 97.2%).
* If they exclude global features from their method, they only achieve 70% real-looking images.
* They can also extract the global features from image A and then use them on image B. That transfers the style from A to B. But it only works well on semantically similar images.
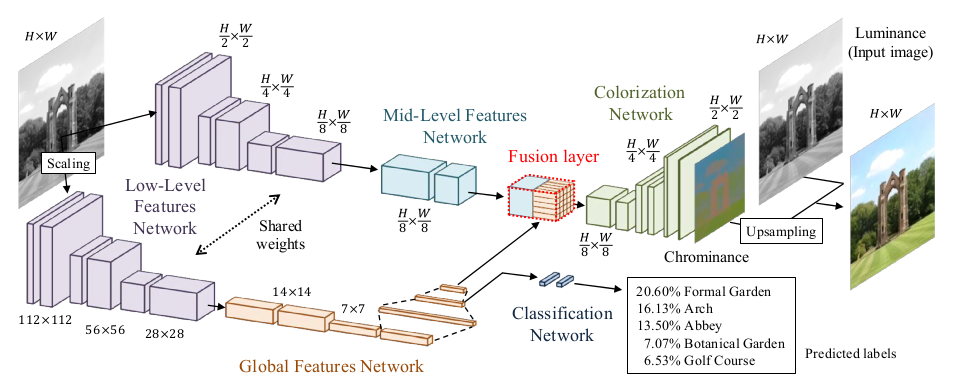
*Architecture of their model.*

*Their model applied to old images.*
--------------------
# Rough chapter-wise notes
* (1) Introduction
* They use a CNN to color images.
* Their network extracts global priors and local features from grayscale images.
* Global priors:
* Extracted from the whole image (e.g. time of day, indoor or outdoors, ...).
* They use class labels of images to train those. (Not needed during test.)
* Local features: Extracted from small patches (e.g. texture).
* They don't generate a full RGB image, instead they generate the chrominance map using the CIE L\*a\*b\* colorspace.
* Components of the model:
* Low level features network: Generated first.
* Mid level features network: Generated based on the low level features.
* Global features network: Generated based on the low level features.
* Colorization network: Receives mid level and global features, which were merged in a fusion layer.
* Their network can process images of arbitrary size.
* Global features can be generated based on another image to change the style of colorization, e.g. to change the seasonal colors from spring to summer.
* (3) Joint Global and Local Model
* <repetition of parts of the introduction>
* They mostly use ReLUs.
* (3.1) Deep Networks
* <standard neural net introduction>
* (3.2) Fusing Global and Local Features for Colorization
* Global features are used as priors for local features.
* (3.2.1) Shared Low-Level Features
* The low level features are which's (low level) features are fed into the networks of both the global and the medium level features extractors.
* They generate them from the input image using a ConvNet with 6 layers (3x3, 1x1 padding, strided/no pooling, ends in 512xH/8xW/8).
* (3.2.2) Global Image Features
* They process the low level features via another network into global features.
* That network has 4 conv-layers (3x3, 2 strided layers, all 512 filters), followed by 3 fully connected layers (1024, 512, 256).
* Input size (of low level features) is expected to be 224x224.
* (3.2.3) Mid-Level Features
* Takes the low level features (512xH/8xW/8) and uses 2 conv layers (3x3) to transform them to 256xH/8xW/8.
* (3.2.4) Fusing Global and Local Features
* The Fusion Layer is basically an extended convolutional layer.
* It takes the mid-level features (256xH/8xW/8) and the global features (256) as input and outputs a matrix of shape 256xH/8xW/8.
* It mostly operates like a normal convolutional layer on the mid-level features. However, its weight matrix is extended to also include weights for the global features (which will be added at every pixel).
* So they use something like `fusion at pixel u,v = sigmoid(bias + weights * [global features, mid-level features at pixel u,v])` - and that with 256 different weight matrices and biases for 256 filters.
* (3.2.5) Colorization Network
* The colorization network receives the 256xH/8xW/8 matrix from the fusion layer and transforms it to the 2xHxW chrominance map.
* It basically uses two upsampling blocks, each starting with a nearest neighbour upsampling layer, followed by 2 3x3 convs.
* The last layer uses a sigmoid activation.
* The network ends in a MSE.
* (3.3) Colorization with Classification
* To make training more effective, they train parts of the global features network via image class labels.
* I.e. they take the output of the 2nd fully connected layer (at the end of the global network), add one small hidden layer after it, followed by a sigmoid output layer (size equals number of class labels).
* They train that with cross entropy. So their global loss becomes something like `L = MSE(color accuracy) + alpha*CrossEntropy(class labels accuracy)`.
* (3.4) Optimization and Learning
* Low level feature extraction uses only convs, so they can be extracted from any image size.
* Global feature extraction uses fc layers, so they can only be extracted from 224x224 images.
* If an image has a size unequal to 224x224, it must be (1) resized to 224x224, fed through low level feature extraction, then fed through the global feature extraction and (2) separately (without resize) fed through the low level feature extraction and then fed through the mid-level feature extraction.
* However, they only trained on 224x224 images (for efficiency).
* Augmentation: 224x224 crops from 256x256 images; random horizontal flips.
* They use Adadelta, because they don't want to set learning rates. (Why not adagrad/adam/...?)
* (4) Experimental Results and Discussion
* They set the alpha in their loss to `1/300`.
* They use the "Places scene dataset". They filter images with low color variance (including grayscale images). They end up with 2.3M training images and 19k validation images. They have 205 classes.
* Batch size: 128.
* They train for about 11 epochs.
* (4.1) Colorization results
* Good looking colorization results on the Places scene dataset.
* (4.2) Comparison with State of the Art
* Their method succeeds where other methods fail.
* Their method can handle very different kinds of images.
* (4.3) User study
* When rated by users, 92.6% think that their coloring is real (ground truth: 97.2%).
* Note: Users were told to only look briefly at the images.
* (4.4) Importance of Global Features
* Their model *without* global features only achieves 70% user rating.
* There are too many ambiguities on the local level.
* (4.5) Style Transfer through Global Features
* They can perform style transfer by extracting the global features of image B and using them for image A.
* (4.6) Colorizing the past
* Their model performs well on old images despite the artifacts commonly found on those.
* (4.7) Classification Results
* Their method achieves nearly as high classification accuracy as VGG (see classification loss for global features).
* (4.8) Comparison of Color Spaces
* L\*a\*b\* color space performs slightly better than RGB and YUV, so they picked that color space.
* (4.9) Computation Time
* One image is usually processed within seconds.
* CPU takes roughly 5x longer.
* (4.10) Limitations and Discussion
* Their approach is data driven, i.e. can only deal well with types of images that appeared in the dataset.
* Style transfer works only really well for semantically similar images.
* Style transfer cannot necessarily transfer specific colors, because the whole model only sees the grayscale version of the image.
* Their model tends to strongly prefer the most common color for objects (e.g. grass always green).
|
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
Tejas D. Kulkarni and Karthik R. Narasimhan and Ardavan Saeedi and Joshua B. Tenenbaum
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.NE, stat.ML
First published: 2016/04/20 (10 years ago)
Abstract: Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. The primary difficulty arises due to insufficient exploration, resulting in an agent being unable to learn robust value functions. Intrinsically motivated agents can explore new behavior for its own sake rather than to directly solve problems. Such intrinsic behaviors could eventually help the agent solve tasks posed by the environment. We present hierarchical-DQN (h-DQN), a framework to integrate hierarchical value functions, operating at different temporal scales, with intrinsically motivated deep reinforcement learning. A top-level value function learns a policy over intrinsic goals, and a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations. This provides an efficient space for exploration in complicated environments. We demonstrate the strength of our approach on two problems with very sparse, delayed feedback: (1) a complex discrete stochastic decision process, and (2) the classic ATARI game `Montezuma's Revenge'.
more
less
Tejas D. Kulkarni and Karthik R. Narasimhan and Ardavan Saeedi and Joshua B. Tenenbaum
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.NE, stat.ML
First published: 2016/04/20 (10 years ago)
Abstract: Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. The primary difficulty arises due to insufficient exploration, resulting in an agent being unable to learn robust value functions. Intrinsically motivated agents can explore new behavior for its own sake rather than to directly solve problems. Such intrinsic behaviors could eventually help the agent solve tasks posed by the environment. We present hierarchical-DQN (h-DQN), a framework to integrate hierarchical value functions, operating at different temporal scales, with intrinsically motivated deep reinforcement learning. A top-level value function learns a policy over intrinsic goals, and a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations. This provides an efficient space for exploration in complicated environments. We demonstrate the strength of our approach on two problems with very sparse, delayed feedback: (1) a complex discrete stochastic decision process, and (2) the classic ATARI game `Montezuma's Revenge'.
|
[link]
* They present a hierarchical method for reinforcement learning.
* The method combines "long"-term goals with short-term action choices.
### How
* They have two components:
* Meta-Controller:
* Responsible for the "long"-term goals.
* Is trained to pick goals (based on the current state) that maximize (extrinsic) rewards, just like you would usually optimize to maximize rewards by picking good actions.
* The Meta-Controller only picks goals when the Controller terminates or achieved the goal.
* Controller:
* Receives the current state and the current goal.
* Has to pick a reward maximizing action based on those, just as the agent would usually do (only the goal is added here).
* The reward is intrinsic. It comes from the Critic. The Critic gives reward whenever the current goal is reached.
* For Montezuma's Revenge:
* A goal is to reach a specific object.
* The goal is encoded via a bitmask (as big as the game screen). The mask contains 1s wherever the object is.
* They hand-extract the location of a few specific objects.
* So basically:
* The Meta-Controller picks the next object to reach via a Q-value function.
* It receives extrinsic reward when objects have been reached in a specific sequence.
* The Controller picks actions that lead to reaching the object based on a Q-value function. It iterates action-choosing until it terminates or reached the goal-object.
* The Critic awards intrinsic reward to the Controller whenever the goal-object was reached.
* They use CNNs for the Meta-Controller and the Controller, similar in architecture to the Atari-DQN paper (shallow CNNs).
* They use two replay memories, one for the Meta-Controller (size 40k) and one for the Controller (size 1M).
* Both follow an epsilon-greedy policy (for picking goals/actions). Epsilon starts at 1.0 and is annealed down to 0.1.
* They use a discount factor / gamma of 0.9.
* They train with SGD.
### Results
* Learns to play Montezuma's Revenge.
* Learns to act well in a more abstract MDP with delayed rewards and where simple Q-learning failed.
--------------------
# Rough chapter-wise notes
* (1) Introduction
* Basic problem: Learn goal directed behaviour from sparse feedbacks.
* Challenges:
* Explore state space efficiently
* Create multiple levels of spatio-temporal abstractions
* Their method: Combines deep reinforcement learning with hierarchical value functions.
* Their agent is motivated to solve specific intrinsic goals.
* Goals are defined in the space of entities and relations, which constraints the search space.
* They define their value function as V(s, g) where s is the state and g is a goal.
* First, their agent learns to solve intrinsically generated goals. Then it learns to chain these goals together.
* Their model has two hiearchy levels:
* Meta-Controller: Selects the current goal based on the current state.
* Controller: Takes state s and goal g, then selects a good action based on s and g. The controller operates until g is achieved, then the meta-controller picks the next goal.
* Meta-Controller gets extrinsic rewards, controller gets intrinsic rewards.
* They use SGD to optimize the whole system (with respect to reward maximization).
* (3) Model
* Basic setting: Action a out of all actions A, state s out of S, transition function T(s,a)->s', reward by state F(s)->R.
* epsilon-greedy is good for local exploration, but it's not good at exploring very different areas of the state space.
* They use intrinsically motivated goals to better explore the state space.
* Sequences of goals are arranged to maximize the received extrinsic reward.
* The agent learns one policy per goal.
* Meta-Controller: Receives current state, chooses goal.
* Controller: Receives current state and current goal, chooses action. Keeps choosing actions until goal is achieved or a terminal state is reached. Has the optimization target of maximizing cumulative reward.
* Critic: Checks if current goal is achieved and if so provides intrinsic reward.
* They use deep Q learning to train their model.
* There are two Q-value functions. One for the controller and one for the meta-controller.
* Both formulas are extended by the last chosen goal g.
* The Q-value function of the meta-controller does not depend on the chosen action.
* The Q-value function of the controller receives only intrinsic direct reward, not extrinsic direct reward.
* Both Q-value functions are reprsented with DQNs.
* Both are optimized to minimize MSE losses.
* They use separate replay memories for the controller and meta-controller.
* A memory is added for the meta-controller whenever the controller terminates.
* Each new goal is picked by the meta-controller epsilon-greedy (based on the current state).
* The controller picks actions epsilon-greedy (based on the current state and goal).
* Both epsilons are annealed down.
* (4) Experiments
* (4.1) Discrete MDP with delayed rewards
* Basic MDP setting, following roughly: Several states (s1 to s6) organized in a chain. The agent can move left or right. It gets high reward if it moves to state s6 and then back to s1, otherwise it gets small reward per reached state.
* They use their hierarchical method, but without neural nets.
* Baseline is Q-learning without a hierarchy/intrinsic rewards.
* Their method performs significantly better than the baseline.
* (4.2) ATARI game with delayed rewards
* They play Montezuma's Revenge with their method, because that game has very delayed rewards.
* They use CNNs for the controller and meta-controller (architecture similar to the Atari-DQN paper).
* The critic reacts to (entity1, relation, entity2) relationships. The entities are just objects visible in the game. The relation is (apparently ?) always "reached", i.e. whether object1 arrived at object2.
* They extract the objects manually, i.e. assume the existance of a perfect unsupervised object detector.
* They encode the goals apparently not as vectors, but instead just use a bitmask (game screen heightand width), which has 1s at the pixels that show the object.
* Replay memory sizes: 1M for controller, 50k for meta-controller.
* gamma=0.99
* They first only train the controller (i.e. meta-controller completely random) and only then train both jointly.
* Their method successfully learns to perform actions which lead to rewards with long delays.
* It starts with easier goals and then learns harder goals.
|