[link]
Summary by Alexander Jung 8 years ago
* They describe an architecture for deep CNNs that contains short and long paths. (Short = few convolutions between input and output, long = many convolutions between input and output)
* They achieve comparable accuracy to residual networks, without using residuals.
### How
* Basic principle:
* They start with two branches. The left branch contains one convolutional layer, the right branch contains a subnetwork.
* That subnetwork again contains a left branch (one convolutional layer) and a right branch (a subnetwork).
* This creates a recursion.
* At the last step of the recursion they simply insert two convolutional layers as the subnetwork.
* Each pair of branches (left and right) is merged using a pair-wise mean. (Result: One of the branches can be skipped or removed and the result after the merge will still be sound.)
* Their recursive expansion rule (left) and architecture (middle and right) visualized:

* Blocks:
* Each of the recursively generated networks is one block.
* They chain five blocks in total to create the network that they use for their experiments.
* After each block they add a max pooling layer.
* Their first block uses 64 filters per convolutional layer, the second one 128, followed by 256, 512 and again 512.
* Drop-path:
* They randomly dropout whole convolutional layers between merge-layers.
* They define two methods for that:
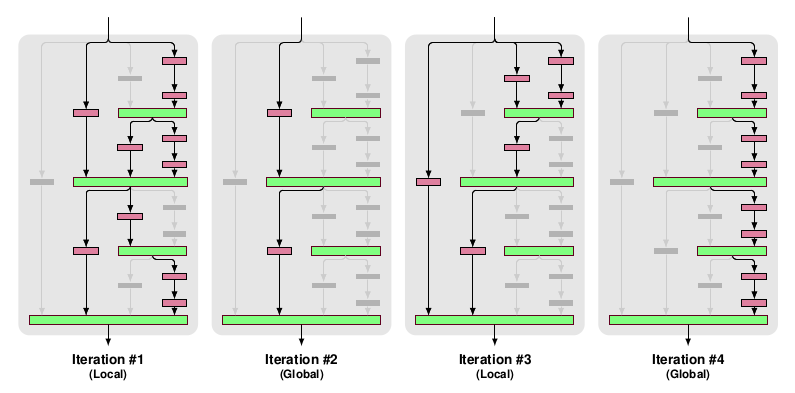
* Local drop-path: Drops each input to each merge layer with a fixed probability, but at least one always survives. (See image, first three examples.)
* Global drop-path: Drops convolutional layers so that only a single columns (and thereby path) in the whole network survives. (See image, right.)
* Visualization:
### Results
* They test on CIFAR-10, CIFAR-100 and SVHN with no or mild (crops, flips) augmentation.
* They add dropout at the start of each block (probabilities: 0%, 10%, 20%, 30%, 40%).
* They use for 50% of the batches local drop-path at 15% and for the other 50% global drop-path.
* They achieve comparable accuracy to ResNets (a bit behind them actually).
* Note: The best ResNet that they compare to is "ResNet with Identity Mappings". They don't compare to Wide ResNets, even though they perform best.
* If they use image augmentations, dropout and drop-path don't seem to provide much benefit (only small improvement).
* If they extract the deepest column and test on that one alone, they achieve nearly the same performance as with the whole network.
* They derive from that, that their fractal architecture is actually only really used to help that deepest column to learn anything. (Without shorter paths it would just learn nothing due to vanishing gradients.)















