
|
Welcome to ShortScience.org! |


|
- ShortScience.org is a platform for post-publication discussion aiming to improve accessibility and reproducibility of research ideas.
- The website has 1584 public summaries, mostly in machine learning, written by the community and organized by paper, conference, and year.
- Reading summaries of papers is useful to obtain the perspective and insight of another reader, why they liked or disliked it, and their attempt to demystify complicated sections.
- Also, writing summaries is a good exercise to understand the content of a paper because you are forced to challenge your assumptions when explaining it.
- Finally, you can keep up to date with the flood of research by reading the latest summaries on our Twitter and Facebook pages.
Learning to Execute
Zaremba, Wojciech and Sutskever, Ilya
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Zaremba, Wojciech and Sutskever, Ilya
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp













[link]
## Problem Statement
* Evaluating if LSTMs can express and learn short, simple programs (linear time, constant memory) in the sequence-to-sequence framework.
* [Link to paper](http://arxiv.org/pdf/1410.4615v3.pdf)
## Approach
* Formulate program evaluation task as a sequence-to-sequence learning problem using RNNs.
* Train on short programs that can be evaluated in linear time and constant memory - RNN can perform only a single pass over the data and its memory is limited.
* Two parameters to control the difficulty of the program:
* `length` : Number of digits in the integer that appears in the program.
* `nesting` : Number of times operations can be combined with each other.
* LSTM reads the input program, one character at a time and produces output, one character at a time.
### Additional Learning Tasks
* **Addition Task** - Given two numbers, the model learns to add them. This task becomes the baseline for comparing performance on other tasks.
* **Memorization Task** - Give a random number, the model memorizes it and outputs it. Following techniques enhance the accuracy of the model:
* **Input reversing** - Reversing the order of input, while keeping the output fixed introduces many short-term dependencies that help LSTM in learning the process.
* **Input doubling** - Presenting the same input to the network twice enhances the performance as the model gets to look at the input twice.
## Curriculum learning
Gradually increase the difficulty of the program fed to the system.
* **No Curriculum (baseline)** - Fixed `length` and fixed `nesting` programs are fed to the system.
* **Naive Curriculum** - Start with `length` = 1 and `nesting` = 1 and keep increasing the values iteratively.
* **Mix Strategy** - Randomly choose `length` and `nesting` to generate a mix of easy and difficult examples.
* **Combined Strategy** - Each training example is obtained either by Naive curriculum strategy or mix strategy.
## Network Architecture
* 2 layers, unrolled for 50 steps.
* 400 cells per layer.
* Parameters initialized uniformly in [-0.08, 0.08]
* minibatch size 100
* norm of gradient normalized to be less than 5
* start with learning rate = 0.5, further decreased by 0.8 after reaching target accuracy of 95%
## Observations
Teacher forcing technique used for computing accuracy ie when predicting the $i_{th}$ digit, the correct first i-1 digits of the output are provided as input to the LSTM.
The general trend is (combine, mix) > (naive, baseline).
In certain cases for program evaluation, baseline performs better than naive curriculum strategy. Intuitively, the model would use all its memory to store patterns for a given size input. Now when a higher size input is provided, the model would have to restructure its memory patterns to learn the output for this new class of inputs. The process of memory restructuring may be causing the degraded performance of the naive strategy. The combined strategy combines the naive and mix strategy and hence reduces the need to restructure the memory patterns.
While LSTMs can learn to map the character level representation of simple programs to their correct output, the idea can not extend to arbitrary programs due to the runtime limitations of conventional RNNs and LSTM. Moreover, while learning is essential, the optimal curriculum strategy needs to be understood further.
 |

The Unified Logging Infrastructure for Data Analytics at Twitter
Lee, George and Lin, Jimmy J. and Liu, Chuang and Lorek, Andrew and Ryaboy, Dmitriy V.
arXiv e-Print archive - 2012 via Local Bibsonomy
Keywords: dblp
Lee, George and Lin, Jimmy J. and Liu, Chuang and Lorek, Andrew and Ryaboy, Dmitriy V.
arXiv e-Print archive - 2012 via Local Bibsonomy
Keywords: dblp
|
[link]
The [paper](http://vldb.org/pvldb/vol5/p1771_georgelee_vldb2012.pdf) presents Twitter's logging infrastructure, how it evolved from application specific logging to a unified logging infrastructure and how session-sequences are used as a common case optimization for a large class of queries.
## Messaging Infrastructure
Twitter uses **Scribe** as its messaging infrastructure. A Scribe daemon runs on every production server and sends log data to a cluster of dedicated aggregators in the same data center. Scribe itself uses **Zookeeper** to discover the hostname of the aggregator. Each aggregator registers itself with Zookeeper. The Scribe daemon consults Zookeeper to find a live aggregator to which it can send the data. Colocated with the aggregators is the staging Hadoop cluster which merges the per-category stream from all the server daemons and writes the compressed results to HDFS. These logs are then moved into main Hadoop data warehouse and are deposited in per-category, per-hour directory (eg /logs/category/YYYY/MM/DD/HH). Within each directory, the messages are bundled in a small number of large files and are partially ordered by time.
Twitter uses **Thrift** as its data serialization framework, as it supports nested structures, and was already being used elsewhere within Twitter. A system called **Elephant Bird** is used to generate Hadoop record readers and writers for arbitrary thrift messages. Production jobs are written in **Pig(Latin)** and scheduled using **Oink**.
## Application Specific Logging
Initially, all applications defined their own custom formats for logging messages. While it made it easy to develop application logging, it had many downsides as well.
* Inconsistent naming conventions: eg uid vs userId vs user_Id
* Inconsistent semantics associated with each category name causing resource discovery problem.
* Inconsistent format of log messages.
All these issues make it difficult to reconstruct user session activity.
## Client Events
This is an effort within Twitter to develop a unified logging framework to get rid of all the issues discussed previously. A hierarchical, 6-level schema is imposed on all the events (as described in the table below).
| Component | Description | Example |
|-----------|------------------------------------|----------------------------------------------|
| client | client application | web, iPhone, android |
| page | page or functional grouping | home, profile, who_to_follow |
| section | tab or stream on a page | home, mentions, retweets, searches, suggestions |
| component | component object or objects | search_box, tweet |
| element | UI element within the component | button, avatar |
| action | actual user or application action | impression, click, hover |
**Table 1: Hierarchical decomposition of client event names.**
For example, the following event, `web:home:mentions:stream:avatar:profile_click` is logged whenever there is an image profile click on the avatar of a tweet in the mentions timeline for a user on twitter.com (read from right to left).
The alternate design was a tree based model for logging client events. That model allowed for arbitrarily deep event namespace with as fine-grained logging as required. But the client events model was chosen to make the top level aggregate queries easier.
A client event is a Thrift structure that contains the components given in the table below.
| Field | Description |
|-----------------|---------------------------------|
| event initiator | {client, server} × {user, app} |
| event_name | event name |
| user_id | user id |
| session_id | session id |
| ip | user’s IP address |
| timestamp | timestamp |
| event_details | event details |
**Table 2: Definition of a client event.**
The logging infrastructure is unified in two senses:
* All log messages share a common format with clear semantics.
* All log messages are stored in a single place.
## Session Sequences
A session sequence is a sequence of symbols *S = {s<sub>0</sub>, s<sub>1</sub>, s<sub>2</sub>...s<sub>n</sub>}* such that each symbol is drawn from a finite alphabet *Σ*. A bijective mapping is defined between Σ and universe of event names. Each symbol in Σ is represented by a valid Unicode point (frequent events are assigned shorter code prints) and each session sequence becomes a valid Unicode string. Once all logs have been imported to the main database, a histogram of event counts is created and is used to map event names to Unicode code points. The counts and samples of each event type are stored in a known location in HDFS. Session sequences are reconstructed from the raw client event logs via a *group-by* on *user_id* and *session_id*. Session sequences are materialized as it is difficult to work with raw client event logs for following reasons:
* A lot of brute force scans.
* Large group-by operations needed to reconstruct user session.
#### Alternate Designs Considered
* Reorganize complete Thrift messages by reconstructing user sessions - This solves the second problem but not the first.
* Use a columnar storage format - This addresses the first issue but it just reduces the time taken by mappers and not the number of mappers itself.
The materialized session sequences are much smaller than raw client event logs (around 50 times smaller) and address both the issues.
## Client Event Catalog
To enhance the accessibility of the client event logs, an automatically generated event data log is used along with a browsing interface to allow users to browse, search and access sample entries for the various client events. (These sample entries are the same entries that were mentioned in the previous section. The catalog is rebuilt every day and is always up to date.
## Applications
Client Event Logs and Session Sequences are used in following applications:
* Summary Statistics - Session sequences are used to compute various statistics about sessions.
* Event Counting - Used to understand what feature of users take advantage of a particular feature.
* Funnel Analytics - Used to focus on user attention in a multi-step process like signup process.
* User Modeling - Used to identify "interesting" user behavior. N-gram models (from NLP domain) can be extended to measure how important temporal signals are by modeling user behavior on the basis of last n actions. The paper also mentions the possibility of extracting "activity collocations" based on the notion of collocations.
## Possible Extensions
Session sequences are limited in the sense that they capture only event name and exclude other details. The solution adopted by Twitter is to use a generic indexing infrastructure that integrates with Hadoop at the level of InputFormats. The indexes reside with the data making it easier to reindex the data. An alternative would have been to use **Trojan layouts** which members indexing in HDFS block header but this means that indexing would require the data to be rewritten. Another possible extension would be to leverage more analogies from the field of Natural Language Processing. This would include the use of automatic grammar induction techniques to learn hierarchical decomposition of user activity. Another area of exploration is around leveraging advanced visualization techniques for exploring sessions and mapping interesting behavioral patterns into distinct visual patterns that can be easily recognized.
|
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Ren, Shaoqing and He, Kaiming and Girshick, Ross B. and Sun, Jian
Neural Information Processing Systems Conference - 2015 via Local Bibsonomy
Keywords: dblp
Ren, Shaoqing and He, Kaiming and Girshick, Ross B. and Sun, Jian
Neural Information Processing Systems Conference - 2015 via Local Bibsonomy
Keywords: dblp
|
[link]
**Object detection** is the task of drawing one bounding box around each instance of the type of object one wants to detect. Typically, image classification is done before object detection. With neural networks, the usual procedure for object detection is to train a classification network, replace the last layer with a regression layer which essentially predicts pixel-wise if the object is there or not. An bounding box inference algorithm is added at last to make a consistent prediction (see [Deep Neural Networks for Object Detection](http://papers.nips.cc/paper/5207-deep-neural-networks-for-object-detection.pdf)). The paper introduces RPNs (Region Proposal Networks). They are end-to-end trained to generate region proposals.They simoultaneously regress region bounds and bjectness scores at each location on a regular grid. RPNs are one type of fully convolutional networks. They take an image of any size as input and output a set of rectangular object proposals, each with an objectness score. ## See also * [R-CNN](http://www.shortscience.org/paper?bibtexKey=conf/iccv/Girshick15#joecohen) * [Fast R-CNN](http://www.shortscience.org/paper?bibtexKey=conf/iccv/Girshick15#joecohen) * [Faster R-CNN](http://www.shortscience.org/paper?bibtexKey=conf/nips/RenHGS15#martinthoma) * [Mask R-CNN](http://www.shortscience.org/paper?bibtexKey=journals/corr/HeGDG17) |

Value Iteration Networks
Tamar, Aviv and Levine, Sergey and Abbeel, Pieter
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
Tamar, Aviv and Levine, Sergey and Abbeel, Pieter
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
Originally posted on my Github repo [paper-notes](https://github.com/karpathy/paper-notes/blob/master/vin.md).
# Value Iteration Networks
By Berkeley group: Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel
This paper introduces a poliy network architecture for RL tasks that has an embedded differentiable *planning module*, trained end-to-end. It hence falls into a category of fun papers that take explicit algorithms, make them differentiable, embed them in a larger neural net, and train everything end-to-end.
**Observation**: in most RL approaches the policy is a "reactive" controller that internalizes into its weights actions that historically led to high rewards.
**Insight**: To improve the inductive bias of the model, embed a specifically-structured neural net planner into the policy. In particular, the planner runs the value Iteration algorithm, which can be implemented with a ConvNet. So this is kind of like a model-based approach trained with model-free RL, or something. Lol.
NOTE: This is very different from the more standard/obvious approach of learning a separate neural network environment dynamics model (e.g. with regression), fixing it, and then using a planning algorithm over this intermediate representation. This would not be end-to-end because we're not backpropagating the end objective through the full model but rely on auxiliary objectives (e.g. log prob of a state given previous state and action when training a dynamics model), and in practice also does not work well.
NOTE2: A recurrent agent (e.g. with an LSTM policy), or a feedforward agent with a sufficiently deep network trained in a model-free setting has some capacity to learn planning-like computation in its hidden states. However, this is nowhere near as explicit as in this paper, since here we're directly "baking" the planning compute into the architecture. It's exciting.
## Value Iteration
Value Iteration is an algorithm for computing the optimal value function/policy $V^*, \pi^*$ and involves turning the Bellman equation into a recurrence:
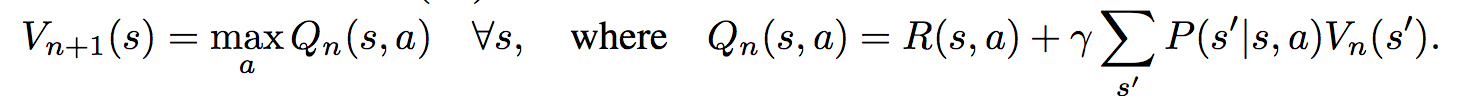
This iteration converges to $V^*$ as $n \rightarrow \infty$, which we can use to behave optimally (i.e. the optimal policy takes actions that lead to the most rewarding states, according to $V^*$).
## Grid-world domain
The paper ends up running the model on several domains, but for the sake of an effective example consider the grid-world task where the agent is at some particular position in a 2D grid and has to reach a specific goal state while also avoiding obstacles. Here is an example of the toy task:
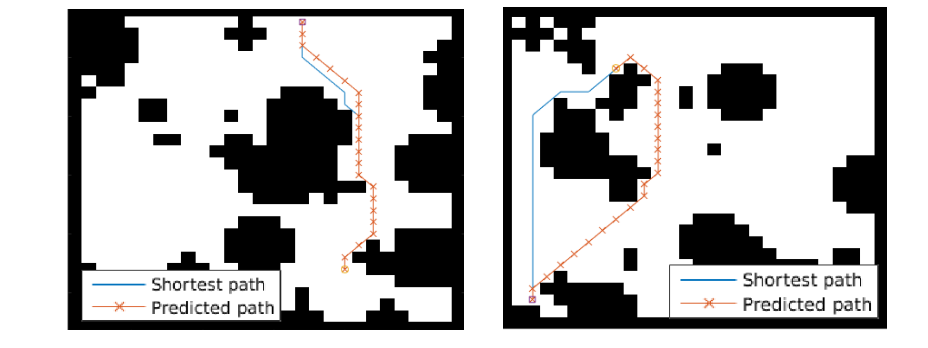
The agent gets a reward +1 in the goal state, -1 in obstacles (black), and -0.01 for each step (so that the shortest path to the goal is an optimal solution).
## VIN model
The agent is implemented in a very straight-forward manner as a single neural network trained with TRPO (Policy Gradients with a KL constraint on predictive action distributions over a batch of trajectories). So the only loss function used is to maximize expected reward, as is standard in model-free RL. However, the policy network of the agent has a very specific structure since it (internally) runs value iteration.
First, there's the core Value Iteration **(VI) Module** which runs the recurrence formula (reproducing again):
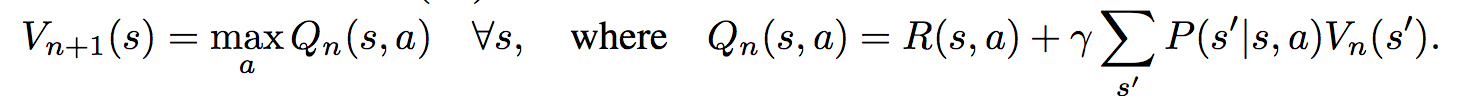
The input to this recurrence are the two arrays R (the reward array, reward for each state) and P (the dynamics array, the probabilities of transitioning to nearby states with each action), which are of course unknown to the agent, but can be predicted with neural networks as a function of the current state. This is a little funny because the networks take a _particular_ state **s** and are internally (during the forward pass) predicting the rewards and dynamics for all states and actions in the entire environment. Notice, extremely importantly and once again, that at no point are the reward and dynamics functions explicitly regressed to the observed transitions in the environment. They are just arrays of numbers that plug into value iteration recurrence module.
But anyway, once we have **R,P** arrays, in the Grid-world above due to the local connectivity, value iteration can be implemented with a repeated application of convolving **P** over **R**, as these filters effectively *diffuse* the estimated reward function (**R**) through the dynamics model (**P**), followed by max pooling across the actions. If **P** is a not a function of the state, it would simply be the filters in the Conv layer. Notice that posing this as convolution also assumes that the env dynamics are position-invariant. See the diagram below on the right: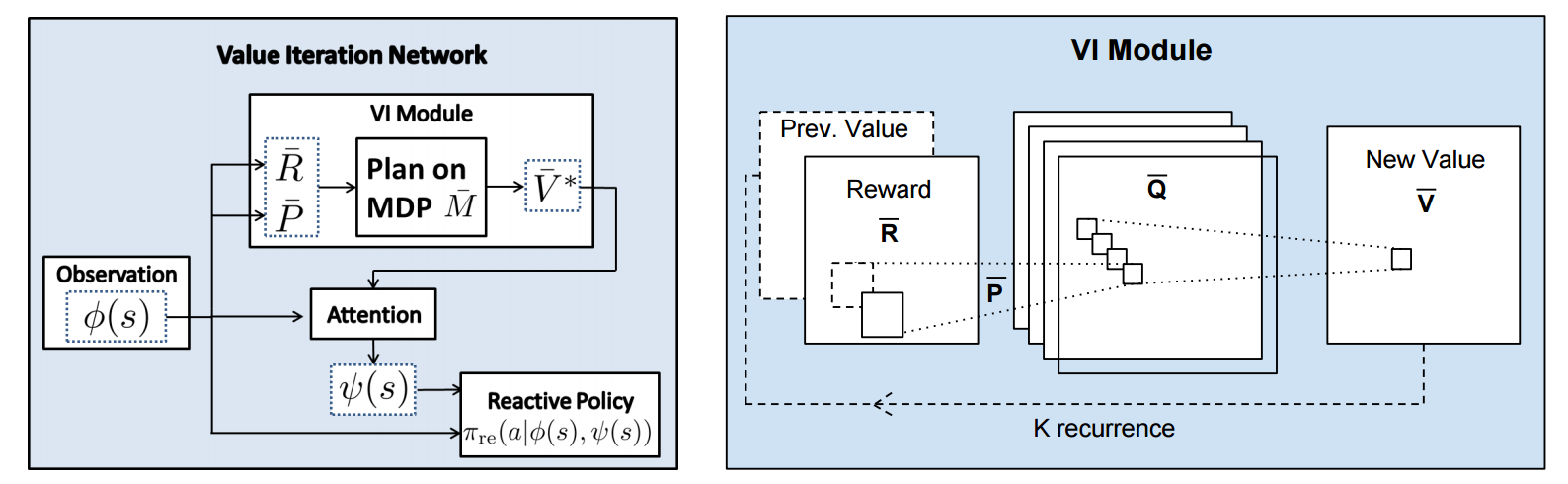
Once the array of numbers that we interpret as holding the estimated $V^*$ is computed after running **K** steps of the recurrence (K is fixed beforehand. For example for a 16x16 map it is 20, since that's a bit more than the amount of steps needed to diffuse rewards across the entire map), we "pluck out" the state-action values $Q(s,.)$ at the state the agent happens to currently be in (by an "attention" operator $\psi$), and (optionally) append these Q values to the feedforward representation of the current state $\phi(s)$, and finally predicting the action distribution.
## Experiments
**Baseline 1**: A vanilla ConvNet policy trained with TRPO. [(50 3x3 filters)\*2, 2x2 max pool, (100 3x3 filters)\*3, 2x2 max pool, FC(100), FC(4), Softmax].
**Baseline 2**: A fully convolutional network (FCN), 3 layers (with a filter that spans the whole image), of 150, 100, 10 filters. i.e. slightly different and perhaps a bit more domain-appropriate ConvNet architecture.
**Curriculum** is used during training where easier environments are trained on first. This is claimed to work better but not quantified in tables. Models are trained with TRPO, RMSProp, implemented in Theano.
Results when training on **5000** random grid-world instances (hey isn't that quite a bit low?):
TLDR VIN generalizes better.
The authors also run the model on the **Mars Rover Navigation** dataset (wait what?), a **Continuous Control** 2D path planning dataset, and the **WebNav Challenge**, a language-based search task on a graph (of a subset of Wikipedia). Skipping these because they don't add _too_ much to the core cool idea of the paper.
## Misc
**The good**: I really like this paper because the core idea is cute (the planner is *embedded* in the policy and trained end-to-end), novel (I don't think I saw this idea executed on so far elsewhere), the paper is well-written and clear, and the supplementary materials are thorough.
**On the approach**: Significant challenges remain to make this approach more practicaly viable, but it also seems that much more exciting followup work can be done in this framework. I wish the authors discussed this more in the conclusion. In particular, it seems that one has to explicitly encode the environment connectivity structure in the internal model $\bar{M}$. How much of a problem is this and what could be done about it? Or how could we do the planning in more higher-level abstract spaces instead of the actual low-level state space of the problem? Also, it seems that a potentially nice feature of this approach is that the agent could dynamically "decide" on a reward function at runtime, and the VI module can diffuse it through the dynamics and hence do the planning. A potentially interesting outcome is that the agent could utilize this kind of computation so that an LSTM controller could learn to "emit" reward function subgoals and the VI planner computes how to meet them. A nice/clean division of labor one could hope for in principle.
**The experiments**. Unfortunately, I'm not sure why the authors preferred breadth of experiments and sacrificed depth of experiments. I would have much preferred a more in-depth analysis of the gridworld environment. For instance:
- Only 5,000 training examples are used for training, which seems very little. Presumable, the baselines get stronger as you increase the number of training examples?
- Lack of visualizations: Does the model actually learn the "correct" rewards **R** and dynamics **P**? The authors could inspect these manually and correlate them to the actual model. This would have been reaaaallllyy cool. I also wouldn't expect the model to exactly learn these, but who knows.
- How does the model compare to the baselines in the number of parameters? or FLOPS? It seems that doing VI for 30 steps at each single iteration of the algorithm should be quite expensive.
- The authors should study the performance as a function of the number of recurrences **K**. A particularly funny experiment would be K = 1, where the model would be effectively predicting **V*** directly, without planning. What happens?
- If the output of VI $\psi(s)$ is concatenated to the state parameters, are these Q values actually used? What if all the weights to these numbers are zero in the trained models?
- Why do the authors only evaluate success rate when the training criterion is expected reward?
Overall a very cute idea, well executed as a first step and well explained, with a bit of unsatisfying lack of depth in the experiments in favor of breadth that doesn't add all that much.
2 Comments
  |

FaceNet: A Unified Embedding for Face Recognition and Clustering
Florian Schroff and Dmitry Kalenichenko and James Philbin
arXiv e-Print archive - 2015 via Local arXiv
Keywords: cs.CV
First published: 2015/03/12 (10 years ago)
Abstract: Despite significant recent advances in the field of face recognition, implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors. Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face. On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result by 30% on both datasets. We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.
more
less
Florian Schroff and Dmitry Kalenichenko and James Philbin
arXiv e-Print archive - 2015 via Local arXiv
Keywords: cs.CV
First published: 2015/03/12 (10 years ago)
Abstract: Despite significant recent advances in the field of face recognition, implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors. Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face. On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result by 30% on both datasets. We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.
|
[link]
FaceNet directly maps face images to $\mathbb{R}^{128}$ where distances directly correspond to a measure of face similarity. They use a triplet loss function. The triplet is (face of person A, other face of person A, face of person which is not A). Later, this is called (anchor, positive, negative).
The loss function is learned and inspired by LMNN. The idea is to minimize the distance between the two images of the same person and maximize the distance to the other persons image.
## LMNN
Large Margin Nearest Neighbor (LMNN) is learning a pseudo-metric
$$d(x, y) = (x -y) M (x -y)^T$$
where $M$ is a positive-definite matrix. The only difference between a pseudo-metric and a metric is that $d(x, y) = 0 \Leftrightarrow x = y$ does not hold.
## Curriculum Learning: Triplet selection
Show simple examples first, then increase the difficulty. This is done by selecting the triplets.
They use the triplets which are *hard*. For the positive example, this means the distance between the anchor and the positive example is high. For the negative example this means the distance between the anchor and the negative example is low.
They want to have
$$||f(x_i^a) - f(x_i^p)||_2^2 + \alpha < ||f(x_i^a) - f(x_i^n)||_2^2$$
where $\alpha$ is a margin and $x_i^a$ is the anchor, $x_i^p$ is the positive face example and $x_i^n$ is the negative example. They increase $\alpha$ over time. It is crucial that $f$ maps the images not in the complete $\mathbb{R}^{128}$, but on the unit sphere. Otherwise one could double $\alpha$ by simply making $f' = 2 \cdot f$.
## Tasks
* **Face verification**: Is this the same person?
* **Face recognition**: Who is this person?
## Datasets
* 99.63% accuracy on Labeled FAces in the Wild (LFW)
* 95.12% accuracy on YouTube Faces DB
## Network
Two models are evaluated: The [Zeiler & Fergus model](http://www.shortscience.org/paper?bibtexKey=journals/corr/ZeilerF13) and an architecture based on the [Inception model](http://www.shortscience.org/paper?bibtexKey=journals/corr/SzegedyLJSRAEVR14).
## See also
* [DeepFace](http://www.shortscience.org/paper?bibtexKey=conf/cvpr/TaigmanYRW14#martinthoma)
|