
arXiv is an e-print service in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance and statistics.
- 1996 1
- 2010 1
- 2011 1
- 2012 8
- 2013 31
- 2014 43
- 2015 134
- 2016 231
- 2017 182
- 2018 141
- 2019 100
- 2020 33
- 2021 10
- 2022 7
- 2023 3
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Stephane Ross and J. Andrew Bagnell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2014/06/23 (10 years ago)
Abstract: Recent work has demonstrated that problems-- particularly imitation learning and structured prediction-- where a learner's predictions influence the input-distribution it is tested on can be naturally addressed by an interactive approach and analyzed using no-regret online learning. These approaches to imitation learning, however, neither require nor benefit from information about the cost of actions. We extend existing results in two directions: first, we develop an interactive imitation learning approach that leverages cost information; second, we extend the technique to address reinforcement learning. The results provide theoretical support to the commonly observed successes of online approximate policy iteration. Our approach suggests a broad new family of algorithms and provides a unifying view of existing techniques for imitation and reinforcement learning.
more
less
Stephane Ross and J. Andrew Bagnell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2014/06/23 (10 years ago)
Abstract: Recent work has demonstrated that problems-- particularly imitation learning and structured prediction-- where a learner's predictions influence the input-distribution it is tested on can be naturally addressed by an interactive approach and analyzed using no-regret online learning. These approaches to imitation learning, however, neither require nor benefit from information about the cost of actions. We extend existing results in two directions: first, we develop an interactive imitation learning approach that leverages cost information; second, we extend the technique to address reinforcement learning. The results provide theoretical support to the commonly observed successes of online approximate policy iteration. Our approach suggests a broad new family of algorithms and provides a unifying view of existing techniques for imitation and reinforcement learning.













[link]
## General Framework
Really **similar to DAgger** (see [summary](https://www.shortscience.org/paper?bibtexKey=journals/corr/1011.0686&a=muntermulehitch)) but considers **cost-sensitive classification** ("some mistakes are worst than others": you should be more careful in imitating that particular action of the expert if failing in doing so incurs a large cost-to-go). By doing so they improve from DAgger's bound of $\epsilon_{class}uT$ where $u$ is the difference in cost-to-go (between the expert and one error followed by expert policy) to $\epsilon_{class}T$ where $\epsilon_{class}$ is the error due to the lack of expressiveness of the policy class. In brief, by accounting for the effect of a mistake on the cost-to-go they remove the cost-to-go contribution to the bound (difference in the performance of the learned policy vs. expert policy) and thus have a tighter bound. In the paper they use the word "regret" for two distinct concepts which is confusing to me: one for the no-regret online learning meta-approach to IL (similar to DAgger) and another one because Aggrevate aims at minimizing the cost-to-go difference with the expert (cost-to-go difference: the sum of the cost I endured because I did not behave like the expert once = *regret*) compared to DAgger that aims at minimizing the error rate wrt. the expert.
Additionally, the paper extends the view of Imitation learning as an online learning procedure to Reinforcement Learning.
## Assumptions
**Interactive**: you can re-query the expert and thus reach $\epsilon T$ bounds instead of $\epsilon T^2$ like with non-interactive methods (Behavioral Cloning) due to compounding error.
Additionally, one also needs a **reward/cost** that **cannot** be defined relative to the expert (no 0-1 loss wrt expert for ex.) since the cost-to-go is computed under the expert policy (would always yield 0 cost).
## Other methods
**SEARN**: does also reason about **cost-to-go but under the current policy** instead of the expert's (even if you can use the expert's in practice and thus becomes really similar to Aggrevate). SEARN uses **stochastic policies** and can be seen as an Aggrevate variant where stochastic mixing is used to solve the online learning problem instead of **Regularized-Follow-The-Leader (R-FTL)**.
## Aggrevate - IL with cost-to-go

Pretty much like DAgger but one has to use a no-regret online learning algo to do **cost-sensitive** instead of regular classification. In the paper, they use the R-FTL algorithm and train the policy on all previous iterations. Indeed, using R-FTL with strongly convex loss (like the squared error) with stable batch leaner (like stochastic gradient descent) ensures the no-regret property.
In practice (to deal with infinite policy classes and knowing the cost of only a few actions per state) they reduce cost-sensitive classification to an **argmax regression problem** where they train a model to match the cost given state-action (and time if we want nonstationary policies) using the collected datapoints and the (strongly convex) squared error loss. Then, they argmin this model to know which action minimizes the cost-to-go (cost-sensitive classification). This is close to what we do for **Q-learning** (DQN or DDPG): fit a critic (Q-values) with the TD-error (instead of full rollouts cost-to-go of expert), argmax your critic to get your policy. Similarly to DQN, the way you explore the actions of which you compute the cost-to-go is important (in this paper they do uniform exploration).
**Limitations**
If the policy class is not expressive enough and cannot match the expert policy performance this algo may fail to learn a reasonable policy. Example: the task is to go for point A to point B, there exist a narrow shortcut and a safer but longer road. The expert can handle both roads so it prefers taking the shortcut. Even if the learned policy class can handle the safer road it will keep trying to use the narrow one and fail to reach the goal. This is because all the costs-to-go are computed under the expert's policy, thus ignoring the fact that they cannot be achieved by any policy of the learned policy class.
## RL via No-Regrety Policy Iteration -- NRPI

NRPI does not require an expert policy anymore but only a **state exploration distribution**. NRPI can also be preferred when no policy in the policy class can match the expert's since it allows for more exploration by considering the **cost-to-go of the current policy**.
Here, the argmax regression equivalent problem is really similar to Q-learning (where we use sampled cost-to-go from rollouts instead of Bellman errors) but where **the cost-to-go** of the aggregate dataset corresponds to **outdated policies!** (in contrast, DQN's data is comprised of rewards instead of costs-to-go).
Yet, since R-FTL is a no-regret online learning method, the learned policy performs well under all the costs-to-go of previous iterations and the policies as well as the costs-to-go converge.
The performance of NRPI is strongly limited to the quality of the exploration distribution. Yet if the exploration distribution is optimal, then NRPI is also optimal (the bound $T\epsilon_{regret} \rightarrow 0$ with enough online iterations). This may be a promising method for not interactive, state-only IL (if you have access to a reward).
## General limitations
Both methods are much less sample efficient than DAgger as they require costs-to-go: one full rollout for one data-point.
## Broad contribution
Seeing iterative learning methods such as Q-learning in the light of online learning methods is insightful and yields better bounds and understanding of why some methods might work. It presents a good tool to analyze the dynamics that interleaves learning and execution (optimizing and collecting data) for the purpose of generalization. For example, the bound for NRPI can seem quite counter-intuitive to someone familiar with on-policy/off-policy distinction, indeed NRPI optimizes a policy wrt to **costs-to-go of other policies**, yet R-FTL tells us that it converges towards what we want. Additionally, it may give a practical advantage for stability as the policy is optimized with larger batches and thus as to be good across many states and many cost-to-go formulations.
 |

Embedding Word Similarity with Neural Machine Translation
Felix Hill and Kyunghyun Cho and Sebastien Jean and Coline Devin and Yoshua Bengio
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL
First published: 2014/12/19 (9 years ago)
Abstract: Neural language models learn word representations, or embeddings, that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models, a recently-developed class of neural language model. We show that embeddings from translation models outperform those learned by monolingual models at tasks that require knowledge of both conceptual similarity and lexical-syntactic role. We further show that these effects hold when translating from both English to French and English to German, and argue that the desirable properties of translation embeddings should emerge largely independently of the source and target languages. Finally, we apply a new method for training neural translation models with very large vocabularies, and show that this vocabulary expansion algorithm results in minimal degradation of embedding quality. Our embedding spaces can be queried in an online demo and downloaded from our web page. Overall, our analyses indicate that translation-based embeddings should be used in applications that require concepts to be organised according to similarity and/or lexical function, while monolingual embeddings are better suited to modelling (nonspecific) inter-word relatedness.
more
less
Felix Hill and Kyunghyun Cho and Sebastien Jean and Coline Devin and Yoshua Bengio
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL
First published: 2014/12/19 (9 years ago)
Abstract: Neural language models learn word representations, or embeddings, that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models, a recently-developed class of neural language model. We show that embeddings from translation models outperform those learned by monolingual models at tasks that require knowledge of both conceptual similarity and lexical-syntactic role. We further show that these effects hold when translating from both English to French and English to German, and argue that the desirable properties of translation embeddings should emerge largely independently of the source and target languages. Finally, we apply a new method for training neural translation models with very large vocabularies, and show that this vocabulary expansion algorithm results in minimal degradation of embedding quality. Our embedding spaces can be queried in an online demo and downloaded from our web page. Overall, our analyses indicate that translation-based embeddings should be used in applications that require concepts to be organised according to similarity and/or lexical function, while monolingual embeddings are better suited to modelling (nonspecific) inter-word relatedness.
|
[link]
If you’ve been paying any attention to the world of machine learning in the last five years, you’ve likely seen everyone’s favorite example for how Word2Vec word embeddings work: king - man + woman = queen. Given the ubiquity of Word2Vec, and similar unsupervised embeddings, it can be easy to start thinking of them as the canonical definition of what a word embedding *is*. But that’s a little oversimplified. In the context of machine learning, an embedding layer simply means any layer structured in the form of a lookup table, where there is some pre-determined number of discrete objects (for example: a vocabulary of words), each of which corresponds to a d-dimensional vector in the lookup table (where d is the number of dimensions you as the model designer arbitrarily chose). These embeddings are initialized in some way, and trained jointly with the rest of the network, using some kind of objective function. Unsupervised, monolingual word embeddings are typically learned by giving a model as input a sample of words that come before and after a given target word in a sentence, and then asking it to predict the target word in the center. Conceptually, if there are words that appear in very similar contexts, they will tend to have similar word vectors. This happens because scores are calculated using the dot product of the target vector with each of the context words, and if two words are to both score highly in that context, the dot product with their common-context vectors must be high for both, which pushes them towards similar values. For the last 3-4 years, unsupervised word vectors like these - which were made widely available for download - became a canonical starting point for NLP problems; this starting representation of words made it easier to learn from smaller datasets, since knowledge about the relationships between words was being transferred from the larger original word embedding training set, through the embeddings themselves. This paper seeks to challenge the unitary dominance of monolingual embeddings, by examining the embeddings learned when the objective is, instead, machine translation, where given a sentence in one language, you must produce it in another. Remember: an embedding is just a lookup table of vectors, and you can use it as the beginning of a machine translation model just as you can the beginning of a monolingual model. In theory, if the embeddings learned by a machine translation model had desirable properties, they could also be widely shared and used for transfer learning, like Word2Vec embeddings often are. When the authors of the paper dive into comparing the embeddings from both of these two approaches, they find some interesting results, such as: while the monolingual embeddings do a better job at analogy-based tests, machine translation embeddings do better at having similarity, within their vector space, map to true similarity of concept. Put another way, while monolingual systems push together words that appear in similar contexts (Teacher, Student, Principal), machine translation systems push words together when they map to the same or similar words in the target language (Teacher, Professor). The attached image shows some examples of this effect; the first three columns are all monolingual approaches, the final two are machine translation ones. When it comes to analogies, machine translation embeddings perform less well at semantic analogies (Ottowa is to Canada as Paris is to France) but does better at syntactic analogies (fast is to fastest as heavier is to heaviest). While I don’t totally understand why monolingual would be better at semantic analogies, it does make sense that the machine translation model would do a better job of encoding syntactic information, since such information is necessarily to sensibly structure a sentence. |

Generative Adversarial Networks
Ian J. Goodfellow and Jean Pouget-Abadie and Mehdi Mirza and Bing Xu and David Warde-Farley and Sherjil Ozair and Aaron Courville and Yoshua Bengio
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2014/06/10 (10 years ago)
Abstract: We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
more
less
Ian J. Goodfellow and Jean Pouget-Abadie and Mehdi Mirza and Bing Xu and David Warde-Farley and Sherjil Ozair and Aaron Courville and Yoshua Bengio
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2014/06/10 (10 years ago)
Abstract: We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
|
[link]
GAN - derive backprop signals through a **competitive process** invovling a pair of networks; Aim: provide an overview of GANs for signal processing community, drawing on familiar analogies and concepts; point to remaining challenges in theory and applications. ## Introduction - How to achieve: implicitly modelling high-dimensional distributions of data - generator receives **no direct access to real images** but error signal from discriminator - discriminator receives both the synthetic samples and samples drawn from the real images - G: G(z) -> R^|x|, where z \in R^|z| is a sample from latent space, x \in R^|x| is an image - D: D(x) -> (0, 1). may not be trained in practice until the generator is optimal https://i.imgur.com/wOwSXhy.png ## Preliminaries - objective functions J_G(theta_G;theta_D) and J_D(theta_D;theta_G) are **co-dependent** as they are iteratively updated - difficulty: hard to construct likelihood functions for high-dimensional, real-world image data |

Recursive Neural Networks Can Learn Logical Semantics
Samuel R. Bowman and Christopher Potts and Christopher D. Manning
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL, cs.LG, cs.NE
First published: 2014/06/06 (10 years ago)
Abstract: Tree-structured recursive neural networks (TreeRNNs) for sentence meaning have been successful for many applications, but it remains an open question whether the fixed-length representations that they learn can support tasks as demanding as logical deduction. We pursue this question by evaluating whether two such models---plain TreeRNNs and tree-structured neural tensor networks (TreeRNTNs)---can correctly learn to identify logical relationships such as entailment and contradiction using these representations. In our first set of experiments, we generate artificial data from a logical grammar and use it to evaluate the models' ability to learn to handle basic relational reasoning, recursive structures, and quantification. We then evaluate the models on the more natural SICK challenge data. Both models perform competitively on the SICK data and generalize well in all three experiments on simulated data, suggesting that they can learn suitable representations for logical inference in natural language.
more
less
Samuel R. Bowman and Christopher Potts and Christopher D. Manning
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL, cs.LG, cs.NE
First published: 2014/06/06 (10 years ago)
Abstract: Tree-structured recursive neural networks (TreeRNNs) for sentence meaning have been successful for many applications, but it remains an open question whether the fixed-length representations that they learn can support tasks as demanding as logical deduction. We pursue this question by evaluating whether two such models---plain TreeRNNs and tree-structured neural tensor networks (TreeRNTNs)---can correctly learn to identify logical relationships such as entailment and contradiction using these representations. In our first set of experiments, we generate artificial data from a logical grammar and use it to evaluate the models' ability to learn to handle basic relational reasoning, recursive structures, and quantification. We then evaluate the models on the more natural SICK challenge data. Both models perform competitively on the SICK data and generalize well in all three experiments on simulated data, suggesting that they can learn suitable representations for logical inference in natural language.
|
[link]
The paper wished to see whether distributed word representations could be used in a machine learning setting to achieve good performance in the task of natural language inference (also called recognizing textual entailment).
## Summary
Paper investigates the use of two neural architectures for identifying the entailment and contradiction logical relationships. In particular, the paper uses tree-based recursive neural networks and tree-based recursive neural tensor networks relying on the notion of compositionality to codify natural language word order and semantic meaning. The models are first tested on a reduced artificial data set organized around a small boolean structure world model where the models are tasked with learning the propositional relationships. Afterwards these models are tested on another more complex artificial data set where simple propositions are converted into more complex formulas. Both models achieved solid performance on these datasets although in the latter data set the RNTN seemed to struggle when tested on larger-length expressions. The models were also tested on an artificial dataset where they were tasked with learning how to correctly interpret various quantifiers and negation in the context of natural logics. Finally, the models were tested on a freely available textual entailment dataset called SICK (that was supplemented with data from the Denotation Graph project). The models achieved reasonably good performance on the SICK challenge, showing that they have the potential to accurately learn distributed representations on noisy real-world data.
## Future Work
The neural models proposed seem to show particular promise for achieving good performance on very natural language logical semantics tasks. It is firmly believed that given enough data, the neural architectures proposed have the potential to perform even better on the proposed task. This makes acquisition of a more comprehensive and diverse dataset a natural next step in pursuing this modeling approach. Further even the more powerful RNTN seems to show rapidly declining performance on larger expressions which leaves the question of whether stronger models or learning techniques can be used to improve performance on considerably-sized expressions. In addition, there is still the question as to how these architectures actually encode the natural logics they are being asked to learn.
|

Training Deep Neural Networks on Noisy Labels with Bootstrapping
Reed, Scott E. and Lee, Honglak and Anguelov, Dragomir and Szegedy, Christian and Erhan, Dumitru and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Reed, Scott E. and Lee, Honglak and Anguelov, Dragomir and Szegedy, Christian and Erhan, Dumitru and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
_Objective:_ Design a loss to make deep network robust to label noise. _Dataset:_ [MNIST](yann.lecun.com/exdb/mnist/), Toroto Faces Database, [ILSVRC2014](http://www.image-net.org/challenges/LSVRC/2014/). #### Inner-workings: Three types of losses are presented: * reconstruciton loss: [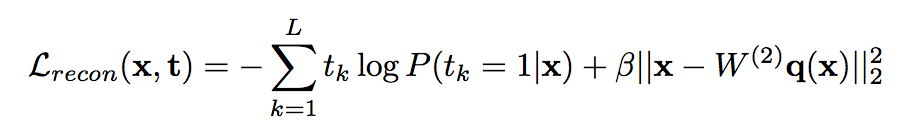](https://user-images.githubusercontent.com/17261080/27532200-bb42b8a6-5a5f-11e7-8c14-673958216bfc.png) * soft bootstrapping which uses the predicted labels by the network `qk` and the user-provided labels `tk`: [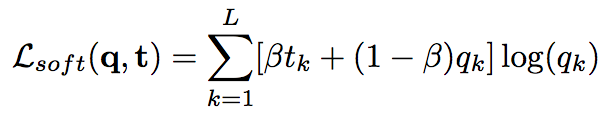](https://user-images.githubusercontent.com/17261080/27532296-1e01a420-5a60-11e7-9273-d1affb0d7c2e.png) * hard bootstrapping replaces the soft predicted labels by their binary version: [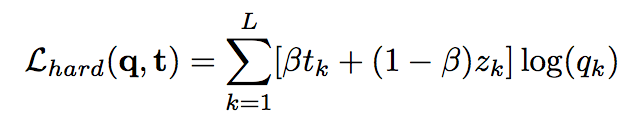](https://user-images.githubusercontent.com/17261080/27532439-a3f9dbd8-5a60-11e7-91a7-327efc748eae.png) [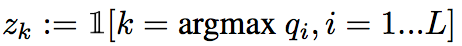](https://user-images.githubusercontent.com/17261080/27532463-b52f4ab4-5a60-11e7-9aed-615109b61bd8.png) #### Architecture: They test with Feed Forward Neural Networks only. #### Results: They use only permutation noise with a very high probability compared with what we might encounter in real-life. [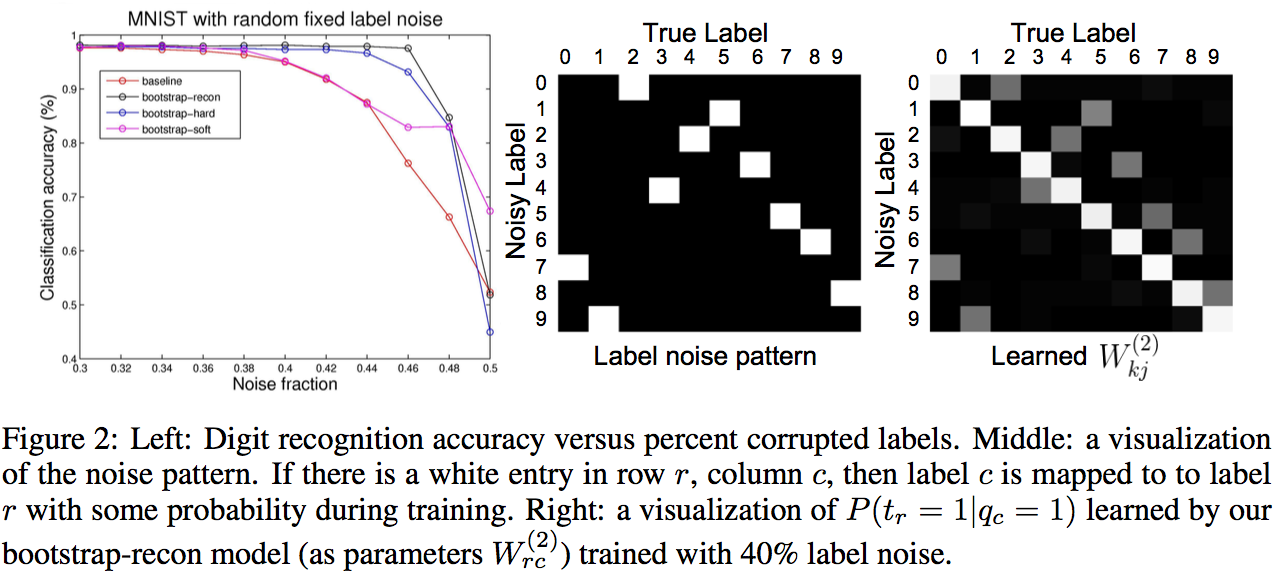](https://user-images.githubusercontent.com/17261080/27533105-b051d366-5a62-11e7-95f3-168d0d2d7841.png) The improvement for small noise probability (<10%) might not be that interesting. |

Ten Years of Pedestrian Detection, What Have We Learned?
Benenson, Rodrigo and Omran, Mohamed and Hosang, Jan Hendrik and Schiele, Bernt
European Conference on Computer Vision - 2014 via Local Bibsonomy
Keywords: dblp
Benenson, Rodrigo and Omran, Mohamed and Hosang, Jan Hendrik and Schiele, Bernt
European Conference on Computer Vision - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
* They compare the results of various models for pedestrian detection.
* The various models were developed over the course of ~10 years (2003-2014).
* They analyze which factors seemed to improve the results.
* They derive new models for pedestrian detection from that.
### Comparison: Datasets
* Available datasets
* INRIA: Small dataset. Diverse images.
* ETH: Video dataset. Stereo images.
* TUD-Brussels: Video dataset.
* Daimler: No color channel.
* Daimler stereo: Stereo images.
* Caltech-USA: Most often used. Large dataset.
* KITTI: Often used. Large dataset. Stereo images.
* All datasets except KITTI are part of the "unified evaluation toolbox" that allows authors to easily test on all of these datasets.
* The evaluation started initially with per-window (FPPW) and later changed to per-image (FPPI), because per-window skewed the results.
* Common evaluation metrics:
* MR: Log-average miss-rate (lower is better)
* AUC: Area under the precision-recall curve (higher is better)
### Comparison: Methods
* Families
* They identified three families of methods: Deformable Parts Models, Deep Neural Networks, Decision Forests.
* Decision Forests was the most popular family.
* No specific family seemed to perform better than other families.
* There was no evidence that non-linearity in kernels was needed (given sophisticated features).
* Additional data
* Adding (coarse) optical flow data to each image seemed to consistently improve results.
* There was some indication that adding stereo data to each image improves the results.
* Context
* For sliding window detectors, adding context from around the window seemed to improve the results.
* E.g. context can indicate whether there were detections next to the window as people tend to walk in groups.
* Deformable parts
* They saw no evidence that deformable part models outperformed other models.
* Multi-Scale models
* Training separate models for each sliding window scale seemed to improve results slightly.
* Deep architectures
* They saw no evidence that deep neural networks outperformed other models. (Note: Paper is from 2014, might have changed already?)
* Features
* Best performance was usually achieved with simple HOG+LUV features, i.e. by converting each window into:
* 6 channels of gradient orientations
* 1 channel of gradient magnitude
* 3 channels of LUV color space
* Some models use significantly more channels for gradient orientations, but there was no evidence that this was necessary to achieve good accuracy.
* However, using more different features (and more sophisticated ones) seemed to improve results.
### Their new model:
* They choose Decisions Forests as their model framework (2048 level-2 trees, i.e. 3 thresholds per tree).
* They use features from the [Integral Channels Features framework](http://pages.ucsd.edu/~ztu/publication/dollarBMVC09ChnFtrs_0.pdf). (Basically just a mixture of common/simple features per window.)
* They add optical flow as a feature.
* They add context around the window as a feature. (A second detector that detects windows containing two persons.)
* Their model significantly improves upon the state of the art (from 34 to 22% MR on Caltech dataset).
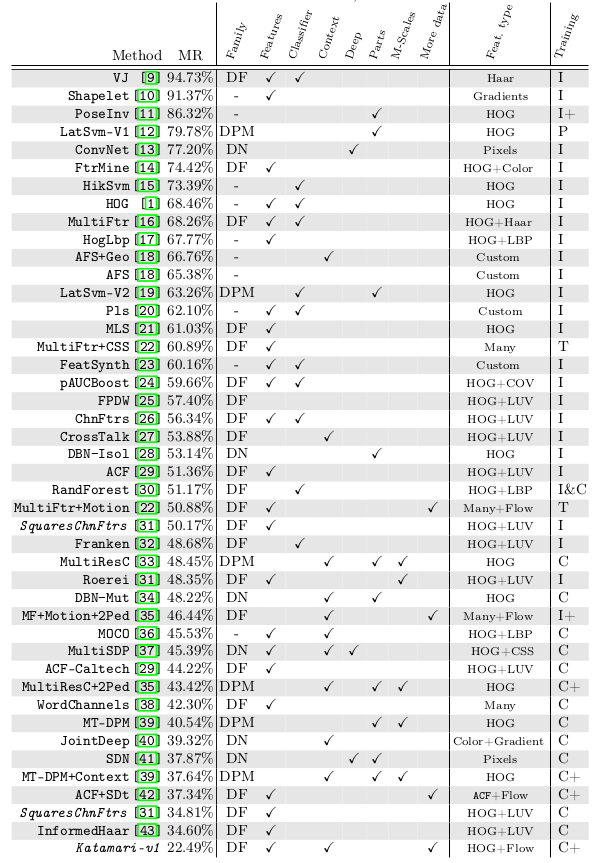
*Overview of models developed over the years, starting with Viola Jones (VJ) and ending with their suggested model (Katamari-v1). (DF = Decision Forest, DPM = Deformable Parts Model, DN = Deep Neural Network; I = Inria Dataset, C = Caltech Dataset)*
|

Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
Tompson, Jonathan J. and Jain, Arjun and LeCun, Yann and Bregler, Christoph
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Tompson, Jonathan J. and Jain, Arjun and LeCun, Yann and Bregler, Christoph
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
* They describe a model for human pose estimation, i.e. one that finds the joints ("skeleton") of a person in an image.
* They argue that part of their model resembles a Markov Random Field (but in reality its implemented as just one big neural network).
### How
* They have two components in their network:
* Part-Detector:
* Finds candidate locations for human joints in an image.
* Pretty standard ConvNet. A few convolutional layers with pooling and ReLUs.
* They use two branches: A fine and a coarse one. Both branches have practically the same architecture (convolutions, pooling etc.). The coarse one however receives the image downscaled by a factor of 2 (half width/height) and upscales it by a factor of 2 at the end of the branch.
* At the end they merge the results of both branches with more convolutions.
* The output of this model are 4 heatmaps (one per joint? unclear), each having lower resolution than the original image.
* Spatial-Model:
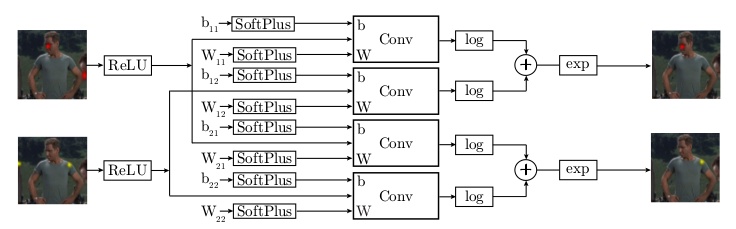
* Takes the results of the part detector and tries to remove all detections that were false positives.
* They derive their architecture from a fully connected Markov Random Field which would be solved with one step of belief propagation.
* They use large convolutions (128x128) to resemble the "fully connected" part.
* They initialize the weights of the convolutions with joint positions gathered from the training set.
* The convolutions are followed by log(), element-wise additions and exp() to resemble an energy function.
* The end result are the input heatmaps, but cleaned up.
### Results
* Beats all previous models (with and without spatial model).
* Accuracy seems to be around 90% (with enough (16px) tolerance in pixel distance from ground truth).
* Adding the spatial model adds a few percentage points of accuracy.
* Using two branches instead of one (in the part detector) adds a bit of accuracy. Adding a third branch adds a tiny bit more.
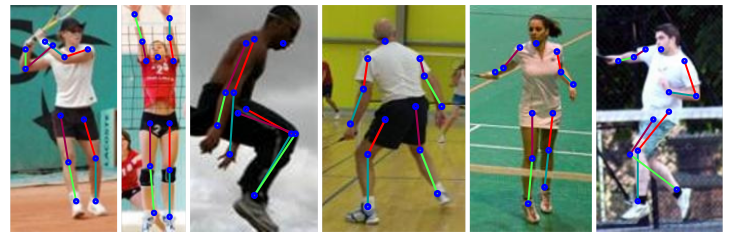
*Example results.*
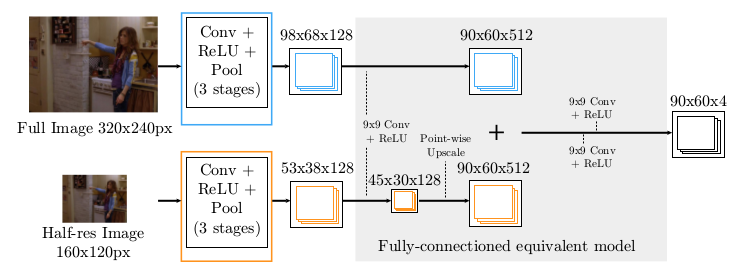
*Part Detector network.*
*Spatial Model (apparently only for two input heatmaps).*
-------------------------
# Rough chapter-wise notes
* (1) Introduction
* Human Pose Estimation (HPE) from RGB images is difficult due to the high dimensionality of the input.
* Approaches:
* Deformable-part models: Traditionally based on hand-crafted features.
* Deep-learning based disciminative models: Recently outperformed other models. However, it is hard to incorporate priors (e.g. possible joint- inter-connectivity) into the model.
* They combine:
* A part-detector (ConvNet, utilizes multi-resolution feature representation with overlapping receptive fields)
* Part-based Spatial-Model (approximates loopy belief propagation)
* They backpropagate through the spatial model and then the part-detector.
* (3) Model
* (3.1) Convolutional Network Part-Detector
* This model locates possible positions of human key joints in the image ("part detector").
* Input: RGB image.
* Output: 4 heatmaps, one per key joint (per pixel: likelihood).
* They use a fully convolutional network.
* They argue that applying convolutions to every pixel is similar to moving a sliding window over the image.
* They use two receptive field sizes for their "sliding window": A large but coarse/blurry one, a small but fine one.
* To implement that, they use two branches. Both branches are mostly identical (convolutions, poolings, ReLU). They simply feed a downscaled (half width/height) version of the input image into the coarser branch. At the end they upscale the coarser branch once and then merge both branches.
* After the merge they apply 9x9 convolutions and then 1x1 convolutions to get it down to 4xHxW (H=60, W=90 where expected input was H=320, W=240).
* (3.2) Higher-level Spatial-Model
* This model takes the detected joint positions (heatmaps) and tries to remove those that are probably false positives.
* It is a ConvNet, which tries to emulate (1) a Markov Random Field and (2) solving that MRF approximately via one step of belief propagation.
* The raw MRF formula would be something like `<likelihood of joint A per px> = normalize( <product over joint v from joints V> <probability of joint A per px given a> * <probability of joint v at px?> + someBiasTerm)`.
* They treat the probabilities as energies and remove from the formula the partition function (`normalize`) for various reasons (e.g. because they are only interested in the maximum value anyways).
* They use exp() in combination with log() to replace the product with a sum.
* They apply SoftPlus and ReLU so that the energies are always positive (and therefore play well with log).
* Apparently `<probability of joint v at px?>` are the input heatmaps of the part detector.
* Apparently `<probability of joint A per px given a>` is implemented as the weights of a convolution.
* Apparently `someBiasTerm` is implemented as the bias of a convolution.
* The convolutions that they use are large (128x128) to emulate a fully connected graph.
* They initialize the convolution weights based on histograms gathered from the dataset (empirical distribution of joint displacements).
* (3.3) Unified Models
* They combine the part-based model and the spatial model to a single one.
* They first train only the part-based model, then only the spatial model, then both.
* (4) Results
* Used datasets: FLIC (4k training images, 1k test, mostly front-facing and standing poses), FLIC-plus (17k, 1k ?), extended-LSP (10k, 1k).
* FLIC contains images showing multiple persons with only one being annotated. So for FLIC they add a heatmap of the annotated body torso to the input (i.e. the part-detector does not have to search for the person any more).
* The evaluation metric roughly measures, how often predicted joint positions are within a certain radius of the true joint positions.
* Their model performs significantly better than competing models (on both FLIC and LSP).
* Accuracy seems to be at around 80%-95% per joint (when choosing high enough evaluation tolerance, i.e. 10px+).
* Adding the spatial model to the part detector increases the accuracy by around 10-15 percentage points.
* Training the part detector and the spatial model jointly adds ~3 percentage points accuracy over training them separately.
* Adding the second filter bank (coarser branch in the part detector) adds around 5 percentage points accuracy. Adding a third filter bank adds a tiny bit more accuracy.
|
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2014/12/20 (9 years ago)
Abstract: Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks' vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.
more
less
Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2014/12/20 (9 years ago)
Abstract: Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks' vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.
|
[link]
#### Problem addressed:
A fast way of finding adversarial examples, and a hypothesis for the adversarial examples
#### Summary:
This paper tries to explain why adversarial examples exists, the adversarial example is defined in another paper \cite{arxiv.org/abs/1312.6199}. The adversarial example is kind of counter intuitive because they normally are visually indistinguishable from the original example, but leads to very different predictions for the classifier. For example, let sample $x$ be associated with the true class $t$. A classifier (in particular a well trained dnn) can correctly predict $x$ with high confidence, but with a small perturbation $r$, the same network will predict $x+r$ to a different incorrect class also with high confidence.
This paper explains that the exsistence of such adversarial examples is more because of low model capacity in high dimensional spaces rather than overfitting, and got some empirical support on that. It also shows a new method that can reliably generate adversarial examples really fast using `fast sign' method. Basically, one can generate an adversarial example by taking a small step toward the sign direction of the objective. They also showed that training along with adversarial examples helps the classifier to generalize.
#### Novelty:
A fast method to generate adversarial examples reliably, and a linear hypothesis for those examples.
#### Datasets:
MNIST
#### Resources:
Talk of the paper https://www.youtube.com/watch?v=Pq4A2mPCB0Y
#### Presenter:
Yingbo Zhou
|

A Deep and Tractable Density Estimator
Uria, Benigno and Murray, Iain and Larochelle, Hugo
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
Uria, Benigno and Murray, Iain and Larochelle, Hugo
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Problem addressed: Fully visible Bayesian network learning #### Summary: This work is an extension of the original NADE paper. As oppose to using a prefixed random fully visible connected Bayesian network (FVBN), they try to train a factorial number of all possible FVBN by optimizing a stochastic version of the objective, which is an unbiased estimator. The resultant model is very easy to do any type of inference, in addition, since it is trained on all orderings, the ensemble generation of NADE models are also very easy with no additional cost. The training is to mask out the variables that one wants to predict, and maximize the likelihood over training data for the prediction of those missing variables. The model is very similar to denoising autoencoder with Bernoulli type of noise on the input. One drawback of this masking is that the model has no distinction between a masked out variable and a variable that has value 0. To overcome this, they supply the mask as additional input to the network and showed that this is an important ingredient for the model to work. #### Novelty: Proposed order agnoistic NADE, which overcome several drawbacks of original NADE. #### Drawbacks: The inference at test time is a bit expensive. #### Datasets: UCI, binary MNIST #### Additional remarks: #### Resources: The first author provided the implementation on his website #### Presenter: Yingbo Zhou |
Learning Generative Models with Visual Attention
Tang, Yichuan and Srivastava, Nitish and Salakhutdinov, Ruslan
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Tang, Yichuan and Srivastava, Nitish and Salakhutdinov, Ruslan
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Problem addressed: Training specific generative model under milder unsupervised assumption #### Summary: This paper implemented an attention based scheme for learning generative models, which could make the unsupervised learning more applicable in practice. In common unsupervised settings, one would assume that the unsupervised data is already in the desired format that one could used directly, which could be a very strong assumption. In this work, the demonstrated a specific application of the idea for training face models. They use a canonical low resolution face model that model the object in mind, alone with a search scheme that resembles the attention to search the face region in a high resolution image. The whole scheme is formalized as a full probabilistic model, and the attention is thus implemented as a inference through the model. The probabilistic model is implemented using RBMs. For inference, they imployed hybrid Monte Carlo, as with all MCMC methods, it is hard for the sampling methods to go between modes that are separated by low density areas. To overcome this, they instead used convnet to propose the moves and used hmc with the convnet initilized states so that the full system is still probabilistic. The result demonstrated are pretty interesting. #### Novelty: The application of visual attention using RBM with probabilistic inference. #### Drawbacks: The inference do need a good convnet for initilization, and it seems the mixing of Markov chain is a big problem. #### Datasets: Caltech and CMU face dataset #### Resources: A neurobiological model of visual attention and invariant pattern recognition based on dynamic routing of information, is the paper of visual attention #### Presenter: Yingbo Zhou |
Object Detectors Emerge in Deep Scene CNNs
Bolei Zhou and Aditya Khosla and Agata Lapedriza and Aude Oliva and Antonio Torralba
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV, cs.NE
First published: 2014/12/22 (9 years ago)
Abstract: With the success of new computational architectures for visual processing, such as convolutional neural networks (CNN) and access to image databases with millions of labeled examples (e.g., ImageNet, Places), the state of the art in computer vision is advancing rapidly. One important factor for continued progress is to understand the representations that are learned by the inner layers of these deep architectures. Here we show that object detectors emerge from training CNNs to perform scene classification. As scenes are composed of objects, the CNN for scene classification automatically discovers meaningful objects detectors, representative of the learned scene categories. With object detectors emerging as a result of learning to recognize scenes, our work demonstrates that the same network can perform both scene recognition and object localization in a single forward-pass, without ever having been explicitly taught the notion of objects.
more
less
Bolei Zhou and Aditya Khosla and Agata Lapedriza and Aude Oliva and Antonio Torralba
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV, cs.NE
First published: 2014/12/22 (9 years ago)
Abstract: With the success of new computational architectures for visual processing, such as convolutional neural networks (CNN) and access to image databases with millions of labeled examples (e.g., ImageNet, Places), the state of the art in computer vision is advancing rapidly. One important factor for continued progress is to understand the representations that are learned by the inner layers of these deep architectures. Here we show that object detectors emerge from training CNNs to perform scene classification. As scenes are composed of objects, the CNN for scene classification automatically discovers meaningful objects detectors, representative of the learned scene categories. With object detectors emerging as a result of learning to recognize scenes, our work demonstrates that the same network can perform both scene recognition and object localization in a single forward-pass, without ever having been explicitly taught the notion of objects.
|
[link]
This paper hypothesizes that a CNN trained for scene classification automatically
discovers meaningful object detectors, representative of the scene categories,
without any explicit object-level supervision. This claim is backed by well-designed
experiments which are a natural extension of the primary insight that since scenes
are composed of objects (a typical bedroom would have a bed, lamp; art gallery would
have paintings, etc), a CNN that performs reasonable well on scene recognition
must be localizing objects in intermediate layers.
## Strengths
- Demonstrates the difference in learned representations in Places-CNN and ImageNet-CNN.
- The top 100 images that have the largest average activation per layer are picked and it's shown that earlier layers such as pool1 prefer similar images for both networks while deeper layers tend to be more specialized to the specific task of scene or object categorization i.e. ~75% of the top 100 images that show high activations for fc7 belong to ImageNet for ImageNet-CNN and Places for Places-CNN.
- Simplifies input images to identify salient regions for classification.
- The input image is simplified by iteratively removing segments that cause the least decrease in classification score until the image is incorrectly classified. This leads them to the minimal image representation (sufficient and necessary) that is needed by the network to correctly recognize scenes, and many of these contain objects that provide discriminative information for scene classification.
- Visualizes the 'empirical receptive fields' of units.
- The top K images with highest activations for a given unit are identified. To identify which regions of the image lead to high unit activations, the image is replicated with occluders at different regions. The occluded images are passed through the network and large changes in activation indicate important regions. This leads them to generate feature maps and finally to empirical receptive fields after appropriate centre-calibration, which are more localized and smaller than the theoretical size.
- Studies the visual concepts / semantics captured by units.
- AMT workers are surveyed on the segments that maximally activate units. They're asked to tag the visual concept, mark negative samples and provide the level of abstraction (from simple elements and colors to objects and scenes). Plot of distribution of semantic categories at each layer shows that deeper layers do capture higher levels of abstraction and Places-CNN units indeed discover more objects than ImageNet-CNN units.
## Weaknesses / Notes
- Unclear as to how they obtain soft, grayed out images from the iterative segmentation methodology in the first approach where they generate minimal image representations needed for accurate classification. I would assume these regions to be segmentations with black backgrounds and hard boundaries. Perez et al. (2013) might have details regarding this.
|

How transferable are features in deep neural networks?
Yosinski, Jason and Clune, Jeff and Bengio, Yoshua and Lipson, Hod
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Yosinski, Jason and Clune, Jeff and Bengio, Yoshua and Lipson, Hod
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper studies the transferability of features learnt at different layers
of a convolutional neural network. Typically, initial layers of a CNN learn
features that resemble Gabor filter or color blobs, and are fairly general, while
the later layers are more task-specific. Main contributions:
- They create two splits of the ImageNet dataset (A/B) and explore how performance
varies for various network design choices such as
- Base: CNN trained on A or B.
- Selffer: first n layers are copied from a base network, and the rest of the
network is randomly initialized and trained on the same task.
- Transfer: first n layers are copied from a base network, and the rest of the
network is trained on a different task.
- Each of these 'copied' layers can either be fine-tuned or kept frozen.
- Selffer networks without fine-tuning don't perform well when the split is somewhere
in the middle of the network (n = 3-6). This is because neurons in these layers co-adapt
to each other's activations in complex ways, which get broken up when split.
- As we approach final layers, there is lesser for the network to learn and so these
layers can be trained independently.
- Fine-tuning a selffer network gives it the chance to re-learn co-adaptations.
- Transfer networks transferred at lower n perform better than larger n, indicating
that features get more task-specific as we move to higher layers.
- Fine-tuning transfer networks, however, results in better performance. They argue
that better generalization is due to the effect of having seen the base dataset,
even after considerable fine-tuning.
- Fine-tuning works much better than using random features.
- Features are more transferable across related tasks than unrelated tasks.
- They study transferability by taking two random data splits, and splits of
man-made v/s natural data.
## Strengths
- Experiments are thorough, and the results are intuitive and insightful.
## Weaknesses / Notes
- This paper only analyzes transferability across different splits of ImageNet
(as similar/dissimilar tasks). They should have reported results on transferability
from one task to another (classification/detection) or from one dataset to another
(ImageNet/MSCOCO).
- It would be interesting to study the role of dropout in preventing co-adaptations
while transferring features.
|
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, Karen and Zisserman, Andrew
- 2014 via Local Bibsonomy
Keywords: deep-learning, VGG
Simonyan, Karen and Zisserman, Andrew
- 2014 via Local Bibsonomy
Keywords: deep-learning, VGG
|
[link]
This paper proposes a modified convolutional network architecture
by increasing the depth, using smaller filters, data augmentation
and a bunch of engineering tricks, an ensemble of which
achieves second place in the classification task and first place
in the localization task at ILSVRC2014.
Main contributions:
- Experiments with architectures with different depths from 11 to
19 weight layers.
- Changes in architecture
- Smaller convolution filters
- 1x1 convolutions: linear transformation of input channels
followed by a non-linearity, increases discriminative capability
of decision function.
- Varying image scales
- During training, the image is rescaled to set the length of the shortest side
to S and then 224x224 crops are taken.
- Fixed S; S=256 and S=384
- Multi-scale; Randomly sampled S from [256,512]
- This can be interpreted as a kind of data augmentation by scale jittering,
where a single model is trained to recognize objects over a wide range of scales.
- Single scale evaluation: At test time, Q=S for fixed S and Q=0.5(S_min + S_max)
for jittered S.
- Multi-scale evaluation: At test time, Q={S-32,S,S+32} for fixed S and Q={S_min,
0.5(S_min + S_max), S_max} for jittered S. Resulting class posteriors are averaged.
This performs the best.
- Dense v/s multi-crop evaluation
- In dense evaluation, the fully connected layers are converted to convolutional
layers at test time, and the uncropped image is passed through the fully convolutional net
to get dense class scores. Scores are averaged for the uncropped image and its
flip to obtain the final fixed-width class posteriors.
- This is compared against taking multiple crops of the test image and averaging scores
obtained by passing each of these through the CNN.
- Multi-crop evaluation works slightly better than dense evaluation, but the methods
are somewhat complementary as averaging scores from both did better than each of them
individually. The authors hypothesize that this is probably because of the different
boundary conditions: when applying a ConvNet to a crop, the convolved feature maps are padded with zeros, while in the case of dense evaluation the padding for the same crop naturally comes from the neighbouring parts of an image (due to both the convolutions and spatial pooling), which substantially increases the overall network receptive field, so more context is captured.
## Strengths
- Thoughtful design of network architectures and experiments to study the effect of
depth, LRN, 1x1 convolutions, pre-initialization of weights, image scales,
and dense v/s multi-crop evaluations.
## Weaknesses / Notes
- No analysis of how much time these networks take to train.
- It is interesting how the authors trained a deeper model (D,E)
by initializing initial and final layer parameters with those from
a shallower model (A).
- It would be interesting to visualize and see the representations
learnt by three stacked 3x3 conv layers and one 7x7 conv layer, and
maybe compare their receptive fields.
- They mention that performance saturates with depth while going
from D to E, but there should have been a more formal characterization
of why that happens (deeper is usually better, yes? no?).
- The ensemble consists of just 2 nets, yet performs really well.
|
Neural Machine Translation by Jointly Learning to Align and Translate
Bahdanau, Dzmitry and Cho, Kyunghyun and Bengio, Yoshua
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Bahdanau, Dzmitry and Cho, Kyunghyun and Bengio, Yoshua
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
One core aspect of this attention approach is that it provides the ability to debug the learned representation by visualizing the softmax output (later called $\alpha_{ij}$) over the input words for each output word as shown below.
https://i.imgur.com/Kb7bk3e.png
In this approach each unit in the RNN they attend over the previous states, unitwise so the length can vary, and then apply a softmax and use the resulting probabilities to multiply and sum each state. This forms the memory used by each state to make a prediction. This bypasses the need for the network to encode everything in the state passed between units.
Each hidden unit is computed as:
$$s_i = f(s_{i−1}, y_{i−1}, c_i).$$
Where $s_{i−1}$ is the previous state and $y_{i−1}$ is the previous target word. Their contribution is $c_i$. This is the context vector which contains the memory of the input phrase.
$$c_i = \sum_{j=1} \alpha_{ij} h_j$$
Here $\alpha_{ij}$ is the output of a softmax for the $j$th element of the input sequence. $h_j$ is the hidden state at the point the RNN was processing the input sequence.
|

Unsupervised Domain Adaptation by Backpropagation
Yaroslav Ganin and Victor Lempitsky
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG, cs.NE
First published: 2014/09/26 (9 years ago)
Abstract: Top-performing deep architectures are trained on massive amounts of labeled data. In the absence of labeled data for a certain task, domain adaptation often provides an attractive option given that labeled data of similar nature but from a different domain (e.g. synthetic images) are available. Here, we propose a new approach to domain adaptation in deep architectures that can be trained on large amount of labeled data from the source domain and large amount of unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of "deep" features that are (i) discriminative for the main learning task on the source domain and (ii) invariant with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a simple new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation. Overall, the approach can be implemented with little effort using any of the deep-learning packages. The method performs very well in a series of image classification experiments, achieving adaptation effect in the presence of big domain shifts and outperforming previous state-of-the-art on Office datasets.
more
less
Yaroslav Ganin and Victor Lempitsky
arXiv e-Print archive - 2014 via Local arXiv
Keywords: stat.ML, cs.LG, cs.NE
First published: 2014/09/26 (9 years ago)
Abstract: Top-performing deep architectures are trained on massive amounts of labeled data. In the absence of labeled data for a certain task, domain adaptation often provides an attractive option given that labeled data of similar nature but from a different domain (e.g. synthetic images) are available. Here, we propose a new approach to domain adaptation in deep architectures that can be trained on large amount of labeled data from the source domain and large amount of unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of "deep" features that are (i) discriminative for the main learning task on the source domain and (ii) invariant with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a simple new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation. Overall, the approach can be implemented with little effort using any of the deep-learning packages. The method performs very well in a series of image classification experiments, achieving adaptation effect in the presence of big domain shifts and outperforming previous state-of-the-art on Office datasets.
|
[link]
The goal of this method is to create a feature representation $f$ of an input $x$ that is domain invariant over some domain $d$. The feature vector $f$ is obtained from $x$ using an encoder network (e.g. $f = G_f(x)$).
The reason this is an issue is that the input $x$ is correlated with $d$ and this can confuse the model to extract features that capture differences in domains instead of differences in classes. Here I will recast the problem differently from in the paper:
**Problem:** Given a conditional probability $p(x|d=0)$ that may be different from $p(x|d=1)$:
$$p(x|d=0) \stackrel{?}{\ne} p(x|d=1)$$
we would like it to be the case that these distributions are equal.
$$p(G_f(x) |d=0) = p(G_f(x)|d=1)$$
aka:
$$p(f|d=0) = p(f|d=1)$$
Of course this is an issue if some class label $y$ is correlated with $d$ meaning that we may hurt the performance of a classifier that now may not be able to predict $y$ as well as before.
https://i.imgur.com/WR2ujRl.png
The paper proposes adding a domain classifier network to the feature vector using a reverse gradient layer. This layer simply flips the sign on the gradient. Here is an example in [Theano](https://github.com/Theano/Theano):
```
class ReverseGradient(theano.gof.Op):
...
def grad(self, input, output_gradients):
return [-output_gradients[0]]
```
You then train this domain network as if you want it to correctly predict the domain (appending it's error to your loss function). As the domain network learns new ways to correctly predict an output these gradients will be flipped and the information in feature vector $f$ will be removed.
There are two major hyper parameters of the method. The number of dimensions at the bottleneck is one but it is linked to your network. The second is a scalar on the gradient so you can increase or decrease the effect of the gradient on the embedding.
1 Comments
 |
Conditional Generative Adversarial Nets
Mirza, Mehdi and Osindero, Simon
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Mirza, Mehdi and Osindero, Simon
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
# Conditional Generative Adversarial Nets
## Introduction
* Conditional version of [Generative Adversarial Nets (GAN)](https://gist.github.com/shagunsodhani/1f9dc0444142be8bd8a7404a226880eb) where both generator and discriminator are conditioned on some data **y** (class label or data from some other modality).
* [Link to the paper](https://arxiv.org/abs/1411.1784)
## Architecture
* Feed **y** into both the generator and discriminator as additional input layers such that **y** and input are combined in a joint hidden representation.
## Experiment
### Unimodal Setting
* Conditioning MNIST images on class labels.
* *z* (random noise) and **y** mapped to hidden layers with ReLu with layer sizes of 200 and 1000 respectively and are combined to obtain ReLu layer of dimensionality 1200.
* Discriminator maps *x* (input) and **y** to maxout layers and the joint maxout layer is fed to sigmoid layer.
* Results do not outperform the state-of-the-art results but do provide a proof-of-the-concept.
### Multimodal Setting
* Map images (from Flickr) to labels (or user tags) to obtain the one-to-many mapping.
* Extract image and text features using convolutional and language model.
* Generative Model
* Map noise and convolutional features to a single 200 dimensional representation.
* Discriminator Model
* Combine the representation of word vectors (corresponding to tags) and images.
## Future Work
* While the results are not so good, they do show the potential of Conditional GANs, especially in the multimodal setting.
|

Visualizing and Comparing Convolutional Neural Networks
Yu, Wei and Yang, Kuiyuan and Bai, Yalong and Yao, Hongxun and Rui, Yong
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Yu, Wei and Yang, Kuiyuan and Bai, Yalong and Yao, Hongxun and Rui, Yong
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper is about the analysis of CNNs. It seems to be extremely similar to what Zeiler & Fergus did. I can't see the contribution. Only cited 7 times, although it is from December 2014 -> I suggest to read the Zeiler & Fergus paper instead. ## Related * 2013, Zeiler & Fergus: [Visualizing and Understanding Convolutional Networks ](http://www.shortscience.org/paper?bibtexKey=journals/corr/ZeilerF13#martinthoma) ## Errors * " Section ?? provides" |

Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/06/18 (10 years ago)
Abstract: Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, "spatial pyramid pooling", to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning. The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102x faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007. In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
more
less
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/06/18 (10 years ago)
Abstract: Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, "spatial pyramid pooling", to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning. The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102x faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007. In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
|
[link]
Spatial Pyramid Pooling (SPP) is a technique which allows Convolutional Neural Networks (CNNs) to use input images of any size, not only $224\text{px} \times 224\text{px}$ as most architectures do. (However, there is a lower bound for the size of the input image).
## Idea
* Convolutional layers operate on any size, but fully connected layers need fixed-size inputs
* Solution:
* Add a new SPP layer on top of the last convolutional layer, before the fully connected layer
* Use an approach similar to bag of words (BoW), but maintain the spatial information. The BoW approach is used for text classification, where the order of the words is discarded and only the number of occurences is kept.
* The SPP layer operates on each feature map independently.
* The output of the SPP layer is of dimension $k \cdot M$, where $k$ is the number of feature maps the SPP layer got as input and $M$ is the number of bins.
Example: We could use spatial pyramid pooling with 21 bins:
* 1 bin which is the max of the complete feature map
* 4 bins which divide the image into 4 regions of equal size (depending on the input size) and rectangular shape. Each bin gets the max of its region.
* 16 bins which divide the image into 4 regions of equal size (depending on the input size) and rectangular shape. Each bin gets the max of its region.
## Evaluation
* Pascal VOC 2007, Caltech101: state-of-the-art, without finetuning
* ImageNet 2012: Boosts accuracy for various CNN architectures
* ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014: Rank #2
## Code
The paper claims that the code is [here](http://research.microsoft.com/en-us/um/people/kahe/), but this seems not to be the case any more.
People have tried to implement it with Tensorflow ([1](http://stackoverflow.com/q/40913794/562769), [2](https://github.com/fchollet/keras/issues/2080), [3](https://github.com/tensorflow/tensorflow/issues/6011)), but by now no public working implementation is available.
## Related papers
* [Atrous Convolution](https://arxiv.org/abs/1606.00915)
1 Comments
 |
Striving for Simplicity: The All Convolutional Net
Jost Tobias Springenberg and Alexey Dosovitskiy and Thomas Brox and Martin Riedmiller
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.LG, cs.CV, cs.NE
First published: 2014/12/21 (9 years ago)
Abstract: Most modern convolutional neural networks (CNNs) used for object recognition are built using the same principles: Alternating convolution and max-pooling layers followed by a small number of fully connected layers. We re-evaluate the state of the art for object recognition from small images with convolutional networks, questioning the necessity of different components in the pipeline. We find that max-pooling can simply be replaced by a convolutional layer with increased stride without loss in accuracy on several image recognition benchmarks. Following this finding -- and building on other recent work for finding simple network structures -- we propose a new architecture that consists solely of convolutional layers and yields competitive or state of the art performance on several object recognition datasets (CIFAR-10, CIFAR-100, ImageNet). To analyze the network we introduce a new variant of the "deconvolution approach" for visualizing features learned by CNNs, which can be applied to a broader range of network structures than existing approaches.
more
less
Jost Tobias Springenberg and Alexey Dosovitskiy and Thomas Brox and Martin Riedmiller
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.LG, cs.CV, cs.NE
First published: 2014/12/21 (9 years ago)
Abstract: Most modern convolutional neural networks (CNNs) used for object recognition are built using the same principles: Alternating convolution and max-pooling layers followed by a small number of fully connected layers. We re-evaluate the state of the art for object recognition from small images with convolutional networks, questioning the necessity of different components in the pipeline. We find that max-pooling can simply be replaced by a convolutional layer with increased stride without loss in accuracy on several image recognition benchmarks. Following this finding -- and building on other recent work for finding simple network structures -- we propose a new architecture that consists solely of convolutional layers and yields competitive or state of the art performance on several object recognition datasets (CIFAR-10, CIFAR-100, ImageNet). To analyze the network we introduce a new variant of the "deconvolution approach" for visualizing features learned by CNNs, which can be applied to a broader range of network structures than existing approaches.
|
[link]
A paper in the intersection for Computer Vision and Machine Learning. They simplify networks by replacing max-pooling by convolutions with higher stride. * introduce a new variant of the "deconvolution approach" for visualizing features learned by CNNs, which can be applied to a broader range of network structures than existing approaches ## Datasets competitive or state of the art performance on several object recognition datasets (CIFAR-10, CIFAR-100, ImageNet) |
Question Answering with Subgraph Embeddings
Antoine Bordes and Sumit Chopra and Jason Weston
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL
First published: 2014/06/14 (10 years ago)
Abstract: This paper presents a system which learns to answer questions on a broad range of topics from a knowledge base using few hand-crafted features. Our model learns low-dimensional embeddings of words and knowledge base constituents; these representations are used to score natural language questions against candidate answers. Training our system using pairs of questions and structured representations of their answers, and pairs of question paraphrases, yields competitive results on a competitive benchmark of the literature.
more
less
Antoine Bordes and Sumit Chopra and Jason Weston
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CL
First published: 2014/06/14 (10 years ago)
Abstract: This paper presents a system which learns to answer questions on a broad range of topics from a knowledge base using few hand-crafted features. Our model learns low-dimensional embeddings of words and knowledge base constituents; these representations are used to score natural language questions against candidate answers. Training our system using pairs of questions and structured representations of their answers, and pairs of question paraphrases, yields competitive results on a competitive benchmark of the literature.
|
[link]
#### Introduction
* Open-domain Question Answering (Open QA) - efficiently querying large-scale knowledge base(KB) using natural language.
* Two main approaches:
* Information Retrieval
* Transform question (in natural language) into a valid query(in terms of KB) to get a broad set of candidate answers.
* Perform fine-grained detection on candidate answers.
* Semantic Parsing
* Interpret the correct meaning of the question and convert it into an exact query.
* Limitations:
* Human intervention to create lexicon, grammar, and schema.
* This work builds upon the previous work where an embedding model learns low dimensional vector representation of words and symbols.
* [Link](https://arxiv.org/abs/1406.3676) to the paper.
#### Task Definition
* Input - Training set of questions (paired with answers).
* KB providing a structure among the answers.
* Answers are entities in KB and questions are strings with one identified KB entity.
* The paper has used FREEBASE as the KB.
* Datasets
* WebQuestions - Built using FREEBASE, Google Suggest API, and Mechanical Turk.
* FREEBASE triplets transformed into questions.
* Clue Web Extractions dataset with entities linked with FREEBASE triplets.
* Dataset of paraphrased questions using WIKIANSWERS.
#### Embedding Questions and Answers
* Model learns low-dimensional vector embeddings of words in question entities and relation types of FREEBASE such that questions and their answers are represented close to each other in the joint embedding space.
* Scoring function $S(q, a)$, where $q$ is a question and $a$ is an answer, generates high score if $a$ answers $q$.
* $S(q, a) = f(q)^{T} . g(a)$
* $f(q)$ maps question to embedding space.
* $f(q) = W \phi (q)$
* $W$ is a matrix of dimension $K * N$
* $K$ - dimension of embedding space (hyper parameter).
* $N$ - total number of words/entities/relation types.
* $\psi(q)$ - Sparse Vector encoding the number of times a word appears in $q$.
* Similarly, $g(a) = W \psi (a)$ maps answer to embedding space.
* $\psi(a)$ gives answer representation, as discussed below.
#### Possible Representations of Candidate Answers
* Answer represented as a **single entity** from FREEBASE and TBD is a one-of-N encoded vector.
* Answer represented as a **path** from question to answer. The paper considers only one or two hop paths resulting in 3-of-N or 4-of-N encoded vectors(middle entities are not recorded).
* Encode the above two representations using **subgraph representation** which represents both the path and the entire subgraph of entities connected to answer entity as a subgraph. Two embedding representations are used to differentiate between entities in path and entities in the subgraph.
* SubGraph approach is based on the hypothesis that including more information about the answers would improve results.
#### Training and Loss Function
* Minimize margin based ranking loss to learn matrix $W$.
* Stochastic Gradient Descent, multi-threaded with Hogwild.
#### Multitask Training of Embeddings
* To account for a large number of synthetically generated questions, the paper also multi-tasks the training of model with paraphrased prediction.
* Scoring function $S_{prp} (q1, q2) = f(q1)^{T} f(q2)$, where $f$ uses the same weight matrix $W$ as before.
* High score is assigned if $q1$ and $q2$ belong to same paraphrase cluster.
* Additionally, the model multitasks the task of mapping embeddings of FREEBASE entities (mids) to actual words.
#### Inference
* For each question, a candidate set is generated.
* The answer (from candidate set) with the highest set is reported as the correct answer.
* Candidate set generation strategy
* $C_1$ - All KB triplets containing the KB entity from the question forms a candidate set. Answers would be limited to 1-hop paths.
* $C_2$ - Rank all relation types and keep top 10 types and add only those 2-hop candidates where the selected relations appear in the path.
#### Results
* $C_2$ strategy outperforms $C_1$ approach supporting the hypothesis that a richer representation for answers can store more information.
* Proposed approach outperforms the baseline methods but is outperformed by an ensemble of proposed approach with semantic parsing via paraphrasing model.
|
Convolutional Neural Networks for Sentence Classification
Kim, Yoon
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Kim, Yoon
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
#### Introduction
* The paper demonstrates how simple CNNs, built on top of word embeddings, can be used for sentence classification tasks.
* [Link to the paper](https://arxiv.org/abs/1408.5882)
* [Implementation](https://github.com/shagunsodhani/CNN-Sentence-Classifier)
#### Architecture
* Pad input sentences so that they are of the same length.
* Map words in the padded sentence using word embeddings (which may be either initialized as zero vectors or initialized as word2vec embeddings) to obtain a matrix corresponding to the sentence.
* Apply convolution layer with multiple filter widths and feature maps.
* Apply max-over-time pooling operation over the feature map.
* Concatenate the pooling results from different layers and feed to a fully-connected layer with softmax activation.
* Softmax outputs probabilistic distribution over the labels.
* Use dropout for regularisation.
#### Hyperparameters
* RELU activation for convolution layers
* Filter window of 3, 4, 5 with 100 feature maps each.
* Dropout - 0.5
* Gradient clipping at 3
* Batch size - 50
* Adadelta update rule.
#### Variants
* CNN-rand
* Randomly initialized word vectors.
* CNN-static
* Uses pre-trained vectors from word2vec and does not update the word vectors.
* CNN-non-static
* Same as CNN-static but updates word vectors during training.
* CNN-multichannel
* Uses two set of word vectors (channels).
* One set is updated and other is not updated.
#### Datasets
* Sentiment analysis datasets for Movie Reviews, Customer Reviews etc.
* Classification data for questions.
* Maximum number of classes for any dataset - 6
#### Strengths
* Good results on benchmarks despite being a simple architecture.
* Word vectors obtained by non-static channel have more meaningful representation.
#### Weakness
* Small data with few labels.
* Results are not very detailed or exhaustive.
|
GraphX: Unifying Data-Parallel and Graph-Parallel Analytics
Xin, Reynold S. and Crankshaw, Daniel and Dave, Ankur and Gonzalez, Joseph E. and Franklin, Michael J. and Stoica, Ion
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Xin, Reynold S. and Crankshaw, Daniel and Dave, Ankur and Gonzalez, Joseph E. and Franklin, Michael J. and Stoica, Ion
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This week I read upon [GraphX](https://amplab.cs.berkeley.edu/wp-content/uploads/2014/02/graphx.pdf), a distributed graph computation framework that unifies graph-parallel and data-parallel computation. Graph-parallel systems efficiently express iterative algorithms (by exploiting the static graph structure) but do not perform well on operations that require a more general view of the graph like operations that move data out of the graph. Data-parallel systems perform well on such tasks but directly implementing graph algorithms on data-parallel systems is inefficient due to complex joins and excessive data movement. This is the gap that GraphX fills in by allowing the same data to be viewed and operated upon both as a graph and as a table.
### Preliminaries
Let $G = (V, E)$ be a graph where $V = \{1, ..., n\}$ is the set of vertices and $E$ is the set of $m$ directed edges. Each directed edge is a tuple of the form $(i, j) \in E$ where $i \in V$ is the source vertex and $j \in V$ is the target vertex. The vertex properties are represented as $P_V(i)$ where $i \in V$ and edge properties as $P_E (i, j)$ for edge $(i, j) \in E$. The collection of all the properties is $P = (P_V, P_E)$. The combination of graph structure and properties defines a property graph $G(P) = (V, E, P)$.
Graph-Parallel Systems consist of a property graph $G = (V, E, P)$ and a vertex-program $Q$ that is instantiated simultaneously on all the vertices. The execution on vertex $v$, called $Q(v)$, interacts with execution on the adjacent vertices by message passing or shared state and can read/modify properties on the vertex, edges and adjacent vertices. $Q$ can run in two different modes:
* **bulk-synchronous mode** - all vertex programs run concurrently in a sequence of super-steps.
* **asynchronous mode** - vertex programs run as and when resources are available and impose constraints on whether neighbouring vertex-programs can run concurrently.
**Gather-Apply-Scatter (GAS)** decomposition model breaks down a vertex-program into purely edge-parallel and vertex-parallel stages. The associative *gather* function collects the inbound messages on the vertices, the *apply* function operates only on the vertices and updates its value and the *scatter* function computes the message to be sent along each edge and can be safely executed in parallel.
GrapX uses bulk-synchronous model and adopts the GAS decomposition model.
### GraphX Data Model
The GraphX Data Model consists of immutable collections and property graphs. Collections consist of unordered tuples (key-value pairs) and are used to represent unstructured data. The property graph combines the structural information (in the form of collections of vertices and edges) with properties describing this structure. Properties are just collections of form $(i, P_V (i))$ and $((i, j), P_E (i, j))$. The collection of vertices and edges are represented using RDDs (Resilient Distributed Datasets). Edges can be partitioned as per a user defined function. Within a partition, edges are clustered by source vertex id and there is an unclustered index on target vertex id. The vertices are hash partitioned by id and stored in a hash index within a partition. Each vertex partition contains a bitmask which allows for set intersection and filtering. It also contains a routing table that logically maps a vertex id to set of edge partitions containing the adjacent edges. This table is used when constructing triplets and is stored as a compressed bitmap.
### Operators
Other than standard data-parallel operators like `filter`, `map`, `leftJoin`, and `reduceByKey`, GraphX supports following graph-parallel operators:
* `graph` - constructs property graph given a collection of edges and vertices.
* `vertices`, `edges` - decompose the graph into a collection of vertices or edges by extracting vertex or edge RDDs.
* `mapV`, `mapE` - transform the vertex or edge collection.
* `triplets` -returns collection of form $((i, j), (P_V (i), P_E (i, j), P_V (j)))$. The operator essentially requires a multiway join between vertex and edge RDD. This operation is optimized by shifting the site of joins to edges, using the routing table, so that only vertex data needs to be shuffled.
* `leftJoin` - given a collection of vertices and a graph, returns a new graph which incorporates the property of matching vertices from the given collection into the given graph without changing the underlying graph structure.
* `subgraph` - returns a subgraph of the original graph by applying predicates on edges and vertices
* `mrTriplets` (MapReduce triplet) - logical composition of triplets followed by map and reduceByKey. It is the building block of graph-parallel algorithms.
All these operators can be expressed in terms on relational operators and can be composed together to express different graph-parallel abstractions. The paper shows how these operators can be used to construct a enhanced version of Pregel based on GAS. It also shows how to express connected components algorithm and `coarsen` operator.
### Structural Index Reuse
Collections and graphs, being immutable, share the structural indexes associated within each vertex and edge partition to both reduce memory overhead and accelerate local graph operations. Most of the operators preserve the structural indexes to reuse them. For operators like subgraph which restrict the graph, the bitmask is used to construct the restricted view.
### Distributed Join Optimization
##### Incremental View Maintenance
The number of vertices that change between different steps of iterative graph algorithms decreases as the computation converges. After each operation, GraphX tracks which vertices have been changed by maintaining a bit mask. When materializing a vertex view, it uses values from the previous view for vertices which have not changed and ships only those vertices which are changed. This also allows for another optimization when using the `mrTriplets` operation: `mrTriplets` support an optional argument called *skipStale*. when this option is enabled, the `mrTriplets` function does not apply on edges origination from vertices that have not changed since its last iteration. This optimization uses the same bitmask that incremental views were using.
##### Automatic Join elimination
GraphX has implemented a JVM bytecode analyzer that determines whether source/target vertex attributes are referenced in a mrTriplet UDF (for map) or not. Since edges already contain the vertex ids, a 3-way join can be brought down to 2-way join if only source/target vertex attributes are needed (as in PageRank algorithm) or the join can be completely eliminated if none of the vertex attributes are referenced.
### Sequential Scan vs Index Scan
Using structural indices, while reduces computation cost in iterative algorithms, prevents physical data from shrinking. To counter this issue, GraphX switches from sequential scan to bitmap index scan when the fraction of active vertices drops below 0.8. Since edges are clustered by source vertex id, bitmap index scan can efficiently join edges and vertexes together.
### Other Optimizations
* Though GraphX uses Spark's shuffle mechanism, it materializes shuffled data in memory itself, unlike Spark which materializes shuffle data in disk and relies on OS buffer cache to cache the data. The rationale behind this modification is that graph algorithms tend to be communication intensive and inability to control when buffers are flushed can lead to additional overhead.
* When implementing join step, vertices routed to the same target are batched, converted from row-orientation to column-orientation and compressed by LZF algorithm and then sent to their destination.
* During shuffling, integers are encoded using a variable encoding scheme where for each byte, the first 7 bits encode the value, and the highest order bit indicates if another byte is needed for encoding the value. So smaller integers can be encoded with fewer bytes and since, in most cases, vertex ids are smaller than 64 bits, the technique helps to reduce an amount of data to be moved.
### System Evaluation
GraphX was evaluated against graph algorithms implemented over Spark 0.8.1, Giraph 1.0 and GraphLab 2.2 for both graph-parallel computation tasks and end-to-end graph analytic pipelines. Key observations:
* GraphLab benefits from its native runtime and performs best among all the implementations for both PageRank and Connected Components algorithm.
* For connected components algorithm, Giraph benefits from using edge cuts but suffers from Hadoop overhead.
* GraphX outperforms idiomatic implementation of PageRank on Spark, benefitting from various optimizations discussed earlier.
* As more machines are added, GraphX does not scale linearly but it still outperforms the speedup achieved by GraphLab (for PageRank).
* GraphX outperforms Giraph and GraphLab for a multi-step, end-to-end graph analytics pipeline that parses Wikipedia articles to make a link graph, runs PageRank on the link graph and joins top 20 articles with their text.
GraphX provides a small set of core graph-processing operators, implemented on top of relational operators, by efficiently encoding graphs as a collection of edges and vertices with two indexing data structures. While it does lag behind specialised systems like Giraph and GraphLab in terms of graph-parallel computation tasks, GraphX does not aim at speeding up such tasks. It instead aims to provide an efficient workflow in end-to-end graph analytics system by combining data-parallel and graph-parallel computations in the same framework. Given that it does outperform all the specialised systems in terms of end-to-end runtime for graph pipelines and makes the development process easier by eliminating the need to learn and maintain multiple systems, it does seem to be a promising candidate for the use case it is attempting to solve.
|
Fractional Max-Pooling
Benjamin Graham
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/12/18 (9 years ago)
Abstract: Convolutional networks almost always incorporate some form of spatial pooling, and very often it is alpha times alpha max-pooling with alpha=2. Max-pooling act on the hidden layers of the network, reducing their size by an integer multiplicative factor alpha. The amazing by-product of discarding 75% of your data is that you build into the network a degree of invariance with respect to translations and elastic distortions. However, if you simply alternate convolutional layers with max-pooling layers, performance is limited due to the rapid reduction in spatial size, and the disjoint nature of the pooling regions. We have formulated a fractional version of max-pooling where alpha is allowed to take non-integer values. Our version of max-pooling is stochastic as there are lots of different ways of constructing suitable pooling regions. We find that our form of fractional max-pooling reduces overfitting on a variety of datasets: for instance, we improve on the state-of-the art for CIFAR-100 without even using dropout.
more
less
Benjamin Graham
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/12/18 (9 years ago)
Abstract: Convolutional networks almost always incorporate some form of spatial pooling, and very often it is alpha times alpha max-pooling with alpha=2. Max-pooling act on the hidden layers of the network, reducing their size by an integer multiplicative factor alpha. The amazing by-product of discarding 75% of your data is that you build into the network a degree of invariance with respect to translations and elastic distortions. However, if you simply alternate convolutional layers with max-pooling layers, performance is limited due to the rapid reduction in spatial size, and the disjoint nature of the pooling regions. We have formulated a fractional version of max-pooling where alpha is allowed to take non-integer values. Our version of max-pooling is stochastic as there are lots of different ways of constructing suitable pooling regions. We find that our form of fractional max-pooling reduces overfitting on a variety of datasets: for instance, we improve on the state-of-the art for CIFAR-100 without even using dropout.
|
[link]
## Introduction
* [Link to Paper](http://arxiv.org/pdf/1412.6071v4.pdf)
* Spatial pooling layers are building blocks for Convolutional Neural Networks (CNNs).
* Input to pooling operation is a $N_{in}$ x $N_{in}$ matrix and output is a smaller matrix $N_{out}$ x $N_{out}$.
* Pooling operation divides $N_{in}$ x $N_{in}$ square into $N^2_{out}$ pooling regions $P_{i, j}$.
* $P_{i, j}$ ⊂ $\{1, 2, . . . , N_{in}\}$ $\forall$ $(i, j) \in \{1, . . . , N_{out} \}^2$
## MP2
* Refers to 2x2 max-pooling layer.
* Popular choice for max-pooling operation.
### Advantages of MP2
* Fast.
* Quickly reduces the size of the hidden layer.
* Encodes a degree of invariance with respect to translations and elastic distortions.
### Issues with MP2
* Disjoint nature of pooling regions.
* Since size decreases rapidly, stacks of back-to-back CNNs are needed to build deep networks.
## FMP
* Reduces the spatial size of the image by a factor of *α*, where *α ∈ (1, 2)*.
* Introduces randomness in terms of choice of pooling region.
* Pooling regions can be chosen in a *random* or *pseudorandom* manner.
* Pooling regions can be *disjoint* or *overlapping*.
## Generating Pooling Regions
* Let $a_i$ and $b_i$ be 2 increasing sequences of integers, starting at 1 and ending at $N_{in}$.
* Increments are either 1 or 2.
* For *disjoint regions, $P = [a_{i−1}, a_{i − 1}] × [b_{j−1}, b_{j − 1}]$
* For *overlapping regions, $P = [a_{i−1}, a_i] × [b_{j−1}, b_j 1]$
* Pooling regions can be generated *randomly* by choosing the increment randomly at each step.
* To generate pooling regions in a *peusdorandom* manner, choose $a_i$ = ceil($\alpha | (i+u))$, where $\alpha \in (1, 2)$ with some $u \in (0, 1)$.
* Each FMP layer uses a different pair of sequence.
* An FMP network can be thought of as an ensemble of similar networks, with each different pooling-region configuration defining a different member of the ensemble.
## Observations
* *Random* FMP is good on its own but may underfit when combined with dropout or training data augmentation.
* *Pseudorandom* approach generates more stable pooling regions.
* *Overlapping* FMP performs better than *disjoint* FMP.
## Weakness
* No justification is provided for the observations mentioned above.
* It needs to be seen how performance is affected if the pooling layer in architectures like GoogLeNet.
|
Hypercolumns for Object Segmentation and Fine-grained Localization
Bharath Hariharan and Pablo Arbeláez and Ross Girshick and Jitendra Malik
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/21 (9 years ago)
Abstract: Recognition algorithms based on convolutional networks (CNNs) typically use the output of the last layer as feature representation. However, the information in this layer may be too coarse to allow precise localization. On the contrary, earlier layers may be precise in localization but will not capture semantics. To get the best of both worlds, we define the hypercolumn at a pixel as the vector of activations of all CNN units above that pixel. Using hypercolumns as pixel descriptors, we show results on three fine-grained localization tasks: simultaneous detection and segmentation[22], where we improve state-of-the-art from 49.7[22] mean AP^r to 60.0, keypoint localization, where we get a 3.3 point boost over[20] and part labeling, where we show a 6.6 point gain over a strong baseline.
more
less
Bharath Hariharan and Pablo Arbeláez and Ross Girshick and Jitendra Malik
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/21 (9 years ago)
Abstract: Recognition algorithms based on convolutional networks (CNNs) typically use the output of the last layer as feature representation. However, the information in this layer may be too coarse to allow precise localization. On the contrary, earlier layers may be precise in localization but will not capture semantics. To get the best of both worlds, we define the hypercolumn at a pixel as the vector of activations of all CNN units above that pixel. Using hypercolumns as pixel descriptors, we show results on three fine-grained localization tasks: simultaneous detection and segmentation[22], where we improve state-of-the-art from 49.7[22] mean AP^r to 60.0, keypoint localization, where we get a 3.3 point boost over[20] and part labeling, where we show a 6.6 point gain over a strong baseline.
|
[link]
So the hypervector is just a big vector created from a network:
`"We concatenate features from some or all of the feature
maps in the network into one long vector for every location
which we call the hypercolumn at that location. As an
example, using pool2 (256 channels), conv4 (384 channels)
and fc7 (4096 channels) from the architecture of [28] would
lead to a 4736 dimensional vector."`
So how exactly do we construct the vector?

Each activation map results in a single element of the resulting hypervector. The corresponding pixel location in each activation map is used as if the activation maps were all scaled to the size of the original image.
The paper shows the below formula for the calculation. Here $\mathbf{f}_i$ is the value of the pixel in the scaled space and each $\mathbf{F}_{k}$ are points in the activation map. $\alpha_{ik}$ scales the known values to produce the midway points.
$$\mathbf{f}_i = \sum_k \alpha_{ik} \mathbf{F}_{k}$$
Then the fully connected layers are simply appended to complete the vector.
So this gives us a representation for each pixel but is it a good one? The later layers will have the input pixel in their receptive field. After the first few layers it is expected that the spatial constraint is not strong.
|
Fully Convolutional Networks for Semantic Segmentation
Jonathan Long and Evan Shelhamer and Trevor Darrell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/14 (9 years ago)
Abstract: Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
more
less
Jonathan Long and Evan Shelhamer and Trevor Darrell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/14 (9 years ago)
Abstract: Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
|
[link]
## Terms
* Semantic Segmentation: Traditional segmentation divides the image in visually similar patches. Semantic segmentation on the other hand divides the image in semantically meaningful patches. This usually means to classify each pixel (e.g.: This pixel belongs to a cat, that pixel belongs to a dog, the other pixel is background).
## Main ideas
* Complete neural networks which were trained for image classification can be used as a convolution. Those networks can be trained on Image Net (e.g. VGG, AlexNet, GoogLeNet)
* Use upsampling to (1) reduce training and prediction time (2) improve consistency of output. (See [What are deconvolutional layers?](http://datascience.stackexchange.com/a/12110/8820) for an explanation.)
## How FCNs work
1. Train a neural network for image classification which is trained on input images of a fixed size ($d \times w \times h$)
2. Interpret the network as a single convolutional filter for each output neuron (so $k$ output neurons means you have $k$ filters) over the complete image area on which the original network was trained.
3. Run the network as a CNN over an image of any size (but at least $d \times w \times h$) with a stride $s \in \mathbb{N}_{\geq 1}$
4. If $s > 1$, then you need an upsampling layer (deconvolutional layer) to convert the coarse output into a dense output.
## Nice properties
* FCNs take images of arbitrary size and produce an image of the same output size.
* Computationally efficient
## See also:
https://www.quora.com/What-are-the-benefits-of-converting-a-fully-connected-layer-in-a-deep-neural-network-to-an-equivalent-convolutional-layer
> They allow you to treat the convolutional neural network as one giant filter. You can then spatially apply the neural net as a convolution to images larger than the original training image size, getting a spatially dense output.
>
> Let's say you train a neural net (with some loss function) with a convolutional layer (3 x 3, stride of 2), pooling layer (3 x 3, stride of 2), and a fully connected layer with 10 units, using 25 x 25 images. Note that the receptive field size of each max pooling unit is 7 x 7, so the pooling output is 5 x 5. You can convert the fully connected layer to to a set of 10 5 x 5 convolutional filters (unit strides). If you do that, the entire net can be treated as a filter with receptive field size 35 x 35 and stride of 4. You can then take that net and apply it to a 50 x 50 image, and you'd get a 3 x 3 x 10 spatially dense output.
1 Comments
 |
Deep Visual-Semantic Alignments for Generating Image Descriptions
Karpathy, Andrej and Li, Fei-Fei
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Karpathy, Andrej and Li, Fei-Fei
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
https://www.youtube.com/watch?v=e-WB4lfg30M This technique is a combination of two powerful machine learning algorithms: - convolutional neural networks are excellent at image classification, i.e., finding out what is seen on an input image, - recurrent neural networks that are capable of processing a sequence of inputs and outputs, therefore it can create sentences of what is seen on the image. Combining these two techniques makes it possible for a computer to describe in a sentence what is seen on an input image. |

Distributed Representations of Sentences and Documents
Le, Quoc V. and Mikolov, Tomas
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
Le, Quoc V. and Mikolov, Tomas
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors present Paragraph Vector, which learns fixed-length, semantically meaningful vector representations for text of any length (sentences, paragraphs, documents, etc). The algorithm works by training a word vector model with an additional paragraph embedding vector as an input. This paragraph embedding is fixed for each paragraph, but varies across paragraphs. Similar to word2vec, PV comes in 2 flavors: - A Distributed Memory Model (PV-DM) that predicts the next word based on the paragraph and preceding words - A BoW model (PW-BoW) that predicts context words for a given paragraph A notable property of PV is that during inference (when you see a new paragraph) it requires training of a new vector, which can be slow. The learned embeddings can used as the input to other models. In their experiments the authors train both variants and concatenate the results. The authors evaluate PV on Classification and Information Retrieval Tasks and achieve new state-of-the-art. #### Data Sets / Results Stanford Sentiment Treebank Polar error: 12.2% Stanford Sentiment Treebank Fine-Grained error: 51.3% IMDB Polar error: 7.42% Query-based search result retrieval (internal) error: 3.82% #### Key Points - Authors use 400-dimensional PV and word embeddings. The window size is a hyperparameter chosen on the validation set, values from 5-12 seem to work well. In IMDB, window size resulted in error fluctuation of ~0.7%. - PV-DM performs well on its own, but concatenating PV-DM and PV-BoW consistently leads to (small) improvements. - When training the PV-DM model, use concatenation instead of averaging to combine words and paragraph vectors (this preserves ordering information) - Hierarchical Softmax is used to deal with large vocabularies. - For final classification, authors use LR or MLP, depending on the task (see below) - IMDB Training (25k documents, 230 average length) takes 30min on 16 core machine, CPU I assume. #### Notes / Question - How did the authors choose the final classification model? Did they cross-validate this? The authors mention that NN performs better than LR for the IMDB data, but they don't show how large the gap is. Does PV maybe perform significantly worse with a simpler model? - I wonder if we can train hierarchical representations of words, sentences, paragraphs, documents, keep the vectors of each one fixed at each layer, and predicting sequences using RNNs. - I wonder how PV compares to an attention-based RNN autoencoder approach. When training PV you are in a way attending to specific parts of the paragraph to predict the missing parts. |

Grammar as a Foreign Language
Vinyals, Oriol and Kaiser, Lukasz and Koo, Terry and Petrov, Slav and Sutskever, Ilya and Hinton, Geoffrey E.
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Vinyals, Oriol and Kaiser, Lukasz and Koo, Terry and Petrov, Slav and Sutskever, Ilya and Hinton, Geoffrey E.
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; Authors apply 3-layer seq2seq LSTM with 256 units and attention mechanism to consituency parsing task and achieve new state of the art. Attention made a huge difference for a small dataset (40k examples), but less so for a noisy large dataset (~11M examples). #### Data Sets and model performance - WSJ (40k examples): 90.5 - Large distantly supervised corpus (90k gold examples, 11M noisy examples): 92.8 #### Key Takeaways - The authors use existing parsers to label a large dataset to be used for training. The trained model then outperforms the "teacher" parsers. A possible explanation is that errors of supervising parsers look like noise to the more powerful LSTM model. These results are extremely valuable, as data is typically the limiting factor, but existing models almost always exist. - Attention mechanism can lead to huge improvements on small data sets. - All of the learned LSTM models were able to deal with long (~70 tokens) sentences without a significant impact of performance. - Reversing the input in seq2seq tasks is common. However, reversing resulted in only a 0.2 point bump in accuracy. - Pre-trained word vectors bumped scores by 0.4 (92.9 -> 94.3) only. #### Notes/Questions - How much does the ouput data representation matter? The authors linearized the parse tree using depth-first traversal and parentheses. Are there more efficient representations that may lead to better results? - How much does the noise in the auto-labeled training data matter when compared to the data size? Are there systematic errors in the auto-labeled data that put a ceiling on model performance? - Bidirectional LSTM? |
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Cho, Kyunghyun and van Merrienboer, Bart and Gülçehre, Çaglar and Bahdanau, Dzmitry and Bougares, Fethi and Schwenk, Holger and Bengio, Yoshua
Empirical Methods on Natural Language Processing (EMNLP) - 2014 via Local Bibsonomy
Keywords: dblp
Cho, Kyunghyun and van Merrienboer, Bart and Gülçehre, Çaglar and Bahdanau, Dzmitry and Bougares, Fethi and Schwenk, Holger and Bengio, Yoshua
Empirical Methods on Natural Language Processing (EMNLP) - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors propose a novel encoder-decoder neural network architecture. The encoder RNN encodes a sequence into a fixed length vector representation and the decoder generates a new variable-length sequence based on this representation. The authors also introduce a new cell type (now called GRU) to be used with this network architecture. The model is evaluated on a statistical machine translation task where it is fed as an additional feature to a log-linear model. It leads to improved BLEU scores. The authors also find that the model learns syntactically and semantically meaningful representations of both words and phrases. #### Key Points: - New encoder-decoder architecture, seq2seq. Decoder conditioned on thought vector. - Architecture can be used for both scoring or generation - New hidden unit type, now called GRU. Simplified LSTM. - Could replace whole pipeline with this architecture, but this paper doesn't - 15k vocabulary (93% of dataset cover). 100d embeddings, 500 maxout units in final affine layer, batch size of 64, adagrad, 384M words, 3 days training time. - Architecture is trained without frequency information so we expect it to capture linguistic information rather than statistical information. - Visualizations of both words embeddings and thought vectors. #### Questions/Notes - Why not just use LSTM units? |
Learning to Execute
Zaremba, Wojciech and Sutskever, Ilya
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Zaremba, Wojciech and Sutskever, Ilya
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors show that seq2seq LSTM networks (2 layers, 400-dims) can learn to evaluate short Python programs (loops, conditionals, addition, subtraction, multiplication). The program code is fed one character at a time, and the LSTM is tasked with generating an output number (12 character vocab). The authors also present a new curriculum learning strategy, where the network is fed with a sensible mixture of easy and increasingly difficult examples, allowing it to gradually build up the concepts required to evaluate these programs. #### Key Points - LSTM unrolled for 50 steps, 2 layer, 400 cells per layer, ~2.5M parameters. Gradient norm constrained to 5. - 3 Curriculum Learning strategies: 1. Naive (increase example difficulty) 2. Mixed: Randomly sample easy and hard problems, 3. Combined: Sample from Naive and Mixed strategy. Mixed or Combined almost always performs better. - Output Vocabulary: 10 digits, minus, dot - For evaluation teacher forcing is used: Feed correct output when generating target sequence - Evaluation Tasks: Program Evaluation, Addition, Memorization - Tricks: Reverse Input sequence, Double input sequence. Seem to make big difference. - Nesting loops makes the tasks difficult since LSTMs can't deal with compositionality. - Feeding easy examples and before hard examples may require the LSTM to restructure its memory. #### Notes / Questions - I wonder if there's a relation between regularization/dropout and curriculum learning. The authors propose that mixing example difficulty forces a more general representation. Shouldn't dropout be doing a similar thing? |
Neural Turing Machines
Graves, Alex and Wayne, Greg and Danihelka, Ivo
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Graves, Alex and Wayne, Greg and Danihelka, Ivo
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors propose Neural Turing Machines (NTMs). A NTM consists of a memory bank and a controller network. The controller network (LSTM or MLP in this paper) controls read/write heads by focusing their attention softly, using a distribution over all memory addresses. It can learn the parameters for two addressing mechanisms: Content-based addressing ("find similar items") and location-based addressing. NTMs can be trained end-to-end using gradient descent. The authors evaluate NTMs on program generations tasks and compare their performance against that of LSTMs. Tasks include copying, recall, prediction, and sorting binary vectors. While both LSTMs and NTMs seems to perform well on training data, only NTMs are able to generalize to longer sequences.
#### Key Observations
- Controller network tried with LSTM or MLP. Which one works better is task-dependent, but LSTM "cache" can be a bottleneck.
- Controller size, number of read/write heads, and memory size are hyperparameters.
- Monitoring the memory addressing shows that the NTM actually learns meaningful programs.
- Number LSTM parameters grow quadratically with hidden unit size due to recurrent connection, not so for NTMs, leading to models with fewer parameters.
- Example problems are very small, typically using sequences 8 bit vectors.
#### Notes/Questions
- At what length to NTMs stop to work? Would've liked to see where results get significantly worse.
- Can we automatically transform fuzzy NTM programs into deterministic ones?
|
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
Cho, KyungHyun and van Merrienboer, Bart and Bahdanau, Dzmitry and Bengio, Yoshua
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Cho, KyungHyun and van Merrienboer, Bart and Bahdanau, Dzmitry and Bengio, Yoshua
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors empirically evaluate seq2seq Neural Machine Translation systems. They find that performance degrades significantly as sentences get longer, and as the number of unknown words in the source sentence increases. Thus, they propose that more investigation into how to deal with large vocabularies and long-range dependencies is needed. The authors also present a new gated recursive convolutional network (grConv) architecture, which consists of a binary tree using GRU units. While this network architecture does not perform as well as the RNN encoder, it seems to be learning grammatical properties represented in the gate activations in an unsupervised fashion. #### Key Points - GrConv: Neuron computed as combination between left and right neuron in previous layer, gated with the activations of those neurons. 3 gates: Left, right, reset. - In experiments, encoder varies between RNN and grConv. Decoder is always RNN. - Model size is only 500MB. 30k vocabulary. Only trained on sentences <= 30 tokens. Networks not trained to convergence. - Beam search with scores normalized by sequence length to choose translations. - Hypothesis is that fixed vector representation is a bottleneck, or that decoder is not powerful enough. #### Notes/Questions - THe network is only trained on sequences <= 30 tokens. Can we really expect it to perform well on long sequences? Long sequences may inherently have grammatical structures that cannot be observed in short sequences. - There's a mistake in the new activation formula, wrong time superscript, should be (t-1). |
Recurrent Neural Network Regularization
Zaremba, Wojciech and Sutskever, Ilya and Vinyals, Oriol
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Zaremba, Wojciech and Sutskever, Ilya and Vinyals, Oriol
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors show that applying dropout to only the **non-recurrent** connections (between layers of the same timestep) in an LSTM works well, improving the scores on various sequence tasks. #### Data Sets and model performance - PTB Language Modeling Perplexity: 78.4 - Google Icelandic Speech Dataset WER Accuracy: 70.5 - WMT'14 English to French Machine Translation BLEU: 29.03 - MS COCO Image Caption Generation BLEU: 24.3 |
Sequence to Sequence Learning with Neural Networks
Sutskever, Ilya and Vinyals, Oriol and Le, Quoc V.
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Sutskever, Ilya and Vinyals, Oriol and Le, Quoc V.
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
TLDR; The authors show that a multilayer LSTM RNN (4 layers, 1000 cells per layer, 1000d embeddings, 160k source vocab, 80k target vocab) can achieve competitive results on Machine Translation tasks. The authors find that reversing the input sequence leads to significant improvements, most likely due to the introduction of short-term dependencies that are more easily captured by the gradients. Somewhat surprisingly, the LSTM did not have difficulties on long sentences. The model is evaluated on MT tasks and achieves competitive results (34.8 BLEU) by itself, and close to state of the art if coupled with existing baseline systems (36.5 BLEU). #### Key Points - Invert input sequence leads to significant improvement - Deep LSTM performs much better than shallow LSTM. - User different parameters for encoder/decoder. This allows parallel training for multiple languages decoders. - 4 Layers, 1000 cells per layer. 1000-dimensional words embeddings. 160k source vocabulary. 80k target vocabulary.Trained on 12M sentences (652M words). SGD with fixed learning rate of 0.7, decreasing by 1/2 every epoch after 5 initial epochs. Gradient clipping. Parallelization on GPU leads to 6.3k words/sec. - Batching sentences of approximately the same length leads to 2x speedup. - PCA projection shows meaningful clusters of sentences robust to passive/active voice, suggesting that the fixed vector representation captures meaning. - "No complete explanation" for why the LSTM does so much better with the introduced short-range dependencies. - Beam size 1 already performs well, beam size 2 is best in deep model. #### Notes/Questions - Seems like the performance here is mostly due to the computational resources available and optimized implementation. These models are pretty big by most standards, and other approaches (e.g. attention) may lead to better results if they had more computational resources. - Reversing the input still feels like a hack to me, there should be a more principled solution to deal with long-range dependencies. |
Affinity Weighted Embedding
Weston, Jason and Weiss, Ron J. and Yee, Hector
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
Weston, Jason and Weiss, Ron J. and Yee, Hector
International Conference on Machine Learning - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper extends supervised embedding models by combining them multiplicatively, i.e. $f'(x,y) = G(x,y) f(x,y). $ It considers two types of model, dot product in the *embedding* space and kernel density in the *embedding* space, where the kernel in the embedding space is restricted to $k((x,y),(x','y)) = k(x-x')k(y-y'). $ It proposes an iterative algorithm which alternates $f$ and $G$ parameter updates. |

A* Sampling
Maddison, Chris J. and Tarlow, Daniel and Minka, Tom
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Maddison, Chris J. and Tarlow, Daniel and Minka, Tom
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper introduces a new approach to sampling from continuous probability distributions. The method extends prior work on using a combination of Gumbel perturbations and optimization to the continuous case. This is technically challenging, and they devise several interesting ideas to deal with continuous spaces, e.g. to produce an exponentially large or even infinite number of random variables (one per point of the continuous/discrete space) with the right distribution in an implicit way. Finally, they highlight an interesting connection with adaptive rejection sampling. Some experimental results are provided and show the promise of the approach. This paper introduces a sampling algorithm based on the Gumbel-max trick and A* search for continuous spaces. The Gumbel-Max trick adds perturbations to an energy function and after applying argmax, results in exact samples from the Gibbs distribution. While this applies to discrete spaces, this paper extends this idea to continuous spaces using the upper bounds on the infinitely many perturbation values. |

Recurrent Models of Visual Attention
Mnih, Volodymyr and Heess, Nicolas and Graves, Alex and Kavukcuoglu, Koray
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Mnih, Volodymyr and Heess, Nicolas and Graves, Alex and Kavukcuoglu, Koray
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
The main contribution of this paper is introducing a (recurrent) visual attention model (RAM). Convolutional networks (CNs) seem to do a great job in computer vision tasks. Unfortunately, the amount of computation they require grows (at least) linearly in the size of the image. The RAM surges as an alternative that performs as well as CNs, but where the amount of computation can be controlled independently of the image size. #### What is RAM? A model that describes a sequential decision process of a goal-directed agent interacting with a visual environment. It involves deciding where to look in a constrained visual environment and taking decisions to maximize a reward. It uses a recurrent neural network to combine information from the past to decide its future actions. #### What do we gain? The attention mechanism takes care of deciding the parts of the image that are worth looking to solve the task. Therefore, it will ignore clutter. In addition, the amount of computation can be decided independently of the image sizes. Furthermore, this could also be directly applied to variable size images as well as detecting multiple objects in one image. #### What follows? An extension that may be worth exploring is whether the attention mechanism can be made differentiable. This might be already done in other papers. #### Like: * Can be used for analyzing videos and playing games. Useful in cluttered environments. #### Dislike: * The model is non-differentiable. |

Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation
Denton, Emily L. and Zaremba, Wojciech and Bruna, Joan and LeCun, Yann and Fergus, Rob
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Denton, Emily L. and Zaremba, Wojciech and Bruna, Joan and LeCun, Yann and Fergus, Rob
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
The paper addresses the problem of speeding up the evaluation of pre-trained image classification ConvNets. To this end, a number of techniques are proposed, which are based on the tensor representation of the conv. layer weight matrix. Namely, the following techniques are considered (Sect. 3.2-3.5): 1. SVD decomposition of the tensor 2. outer product decomposition of the tensor 3. monochromatic approximation of the first conv. layer - projecting RGB colors to a 1-D space, followed by clustering 4. biclustering tensor approximation - clustering input and output features to split the tensor into a number of sub-tensors, each of which is then separately approximated 5. fine-tuning of approximate models to (partially) recover the lost accuracy |
Two-Stream Convolutional Networks for Action Recognition in Videos
Simonyan, Karen and Zisserman, Andrew
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Simonyan, Karen and Zisserman, Andrew
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper proposes a model for solving discriminative tasks with video inputs. The model consists of two convolutional nets. The input to one net is an appearance frame. The input to the second net is a stack of densely computed optical flow features. Each pathway is trained separately to classify its input. The prediction for a video is obtained by taking a (weighted) average of the predictions made by each net. |
Semi-Separable Hamiltonian Monte Carlo for Inference in Bayesian Hierarchical Models
Zhang, Yichuan and Sutton, Charles A.
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
Zhang, Yichuan and Sutton, Charles A.
Neural Information Processing Systems Conference - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper proposes a way to speed up Hamiltonian Monte Carlo (HMC) \cite{Duane1987216} sampling for hierarchical models. It is similar in spirit to RMHMC, in which the mass matrix varies according to local topology, except that here the mass matrices for each parameter type (parameter or hyperparameter) only depend on their counterpart, which allows an explicit leapfrog integrator to be used to simulate dynamics rather than an implicit integrator requiring fixed-point iteration to convergence for each step. The authors point out that their method goes beyond straightforward Gibbs sampling with HMC within each Gibbs step since their method leaves the counterpart parameter's momentum intact.
|
Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
The R-CNN method is a way to localize objects in an image. It is restricted to finding one of each object in an image. 1. Regions are generated based on any method including brute force sliding window. 2. Each region is classified using AlexNet. 3. The classifications for each label are searched to find the location which expresses that label the most. |
Going Deeper with Convolutions
Szegedy, Christian and Liu, Wei and Jia, Yangqing and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Szegedy, Christian and Liu, Wei and Jia, Yangqing and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper introduces the GoogLeNet Inception Architecture The major part of this paper is the *Inception Module* which takes convolutions at multiple layers and provides a good receptive field as well as reducing the overall number of parameters.  |
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Kingma, Diederik P. and Ba, Jimmy
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
Adam is like RMSProp with momentum. The (simplified) update [[Stanford CS231n]](https://cs231n.github.io/neural-networks-3/#ada) looks as follows: ``` m = beta1*m + (1-beta1)*dx v = beta2*v + (1-beta2)*(dx**2) x += - learning_rate * m / (np.sqrt(v) + eps) ``` |