
The program for CVPR consists of high quality contributed papers on all aspects of
computer vision and pattern recognition.
Salient Region Detection via High-Dimensional Color Transform
Jiwhan Kim and Dongyoon Han and Yu-Wing Tai and Junmo Kim
Conference and Computer Vision and Pattern Recognition - 2014 via Local CrossRef
Keywords:
Jiwhan Kim and Dongyoon Han and Yu-Wing Tai and Junmo Kim
Conference and Computer Vision and Pattern Recognition - 2014 via Local CrossRef
Keywords:













[link]
**Introduction** * Salient region is an area where a striking combination of features in images is perceived at the first observation. * These features combined to make a region that has a significant distinction with other areas in the image. * This paper presents a map of saliency using linear combination of high-dimensional color representation space. **Related work** * Present work in saliency detection is divided into two groups which are taking into account low-level features, and statistical learning methods. Both approach has variety of results with no clear significance which performs better in saliency detection. * In the first group of taking into account of low-level features, there are approaches on saliency region detection based on color contrast, Markovian approach, and multi-scale saliency based on superpixels that have drawbacks on the pres.ence of high-contrast edges, unpreserved boundary, and segmentation parameters. * Using learning-based methods present are region detection saliency based on the regional descriptor, using graph-based, and sample patches. **Approach** * Paper provides a method of mapping low dimensional color of RGB, CIELab, HSV spaces into high dimensional color. * Method identify the presence of superpixel saliency features using the SLIC method with 500 number of superpixels. * Feature vector is defined by the location of superpixels and then combined with color which proceeds to color space representation computation. * Histogram features are later combined with 8 bins in each of the histogram and distance is computed using the Chi-squared method. * Global and local contrast are used using Euclidean distance with variance parameters of 0.25. * Histogram of gradients method with 31 dimensions is used to extract shape and texture features in the superpixels. As backgrounds tend to have more blur features in the pixel, separation of backgrounds is done using Singular Value Feature which algorithm is following the concept of Eigen images with weight acquired by using Singular Value Decomposition. * 75 dimension of feature vectors are then obtained for saliency detection. These feature maps are combined from all the superpixel operations mentioned. Features included are location features, color features, color histogram features, color contrast features, shape and texture features. * Regression algorithm is then applied to feature vectors. As large databases including 2000 images in a dataset are tested, the best present approach for the algorithm is a random forest. An unlimited number of nodes are applied with 200 trees. * To construct the transformation into high-dimensional color, a Trimap is built by dividing the starting saliency map to three different regions that are 2x2, 3x3, and 4x4. Then seven level of adaptive thresholding is applied to each subregion which then produces 21-level of the locally thresholded map. * Global threshold construct the trimap by the division of local levels, when the levels are more and equal to 18 levels, the map is defined by 1 and when the levels are less and equal than 6 levels, map is defined by 0. https://i.imgur.com/4eF1UZd.png * High dimensional color is used as it combines all the benefits of color representation properties. Nonlinear color representation in RGB and its gradients, CIELab color representation, and saturation and hue in HSV are combined. This produces 11 color channels. * Linear RGB values are not combined as it counteracts with YUV/YIQ color space. * Then gamma correction in the range of 0.5 to 2 with 0.5 intervals is applied, generating 44 high dimensional color vector. * Background that had been separated from the foreground in trimap is then examined to approximate color coefficients' linear combination using the minimum of least square problem of two matrices. The first matrix is a vector with binary value with 0 represents background and 1 represents foreground. The second matrix is color samples multiplied by a coefficient vector. * The map of the saliency region is then built by the summation of color samples applied to the coefficient vector estimation. The whole method is iterated three times to construct a stable saliency map. * The map is then refined by spatial information by adding more weights to pixels that contain foreground region. It is defined by exponential to the power of a parameter 0.5 applied to the minimum Euclidean distance for both foreground and background. It is concluded in the image below: https://i.imgur.com/k9heDiw.png * Algorithm is evaluated using three datasets that contain 5000 images in the MSRA dataset, 1000 images in the ECCSD dataset, and 643 multiple objects in the Interactive co-segmentation dataset. * Eight saliency region detection are compared using precision and recall measurements. The algorithms compared are LC, HC, LR, SF, HS, GMR, and DRFI. * F-measurement to evaluate performance is computed by application of precision-recall, and a quadratic parameter added by one that is divided by the summation of precision, recall, and the quadratic parameter. The quadratic parameter has a value of 0.3. * Algorithm performance placed at the second-best compared to all other methods. **Notes on The Paper** * Paper provides an algorithm that performs well for detecting saliency based on colors by generating features that are high dimensional from low-level features. * In high dimensional color space, salient regions are able to be separated from the background (Rahman, I et al. 2016). * If the algorithm is further developed using classifier, it is then able to integrate richer features as a higher dimension is present (Borji, A et al. 2017).  |

Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks
Oquab, Maxime and Bottou, Léon and Laptev, Ivan and Sivic, Josef
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
Oquab, Maxime and Bottou, Léon and Laptev, Ivan and Sivic, Josef
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
_Objective:_ Transfer feature learned from large-scale dataset to small-scale dataset _Dataset:_ [ImageNet](www.image-net.org), [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/). #### Inner-workings: Basically they train the network on the large dataset, then replace the last layers, sometimes adding a new one and train this on the new dataset. Pretty standard transfer learning nowadays. [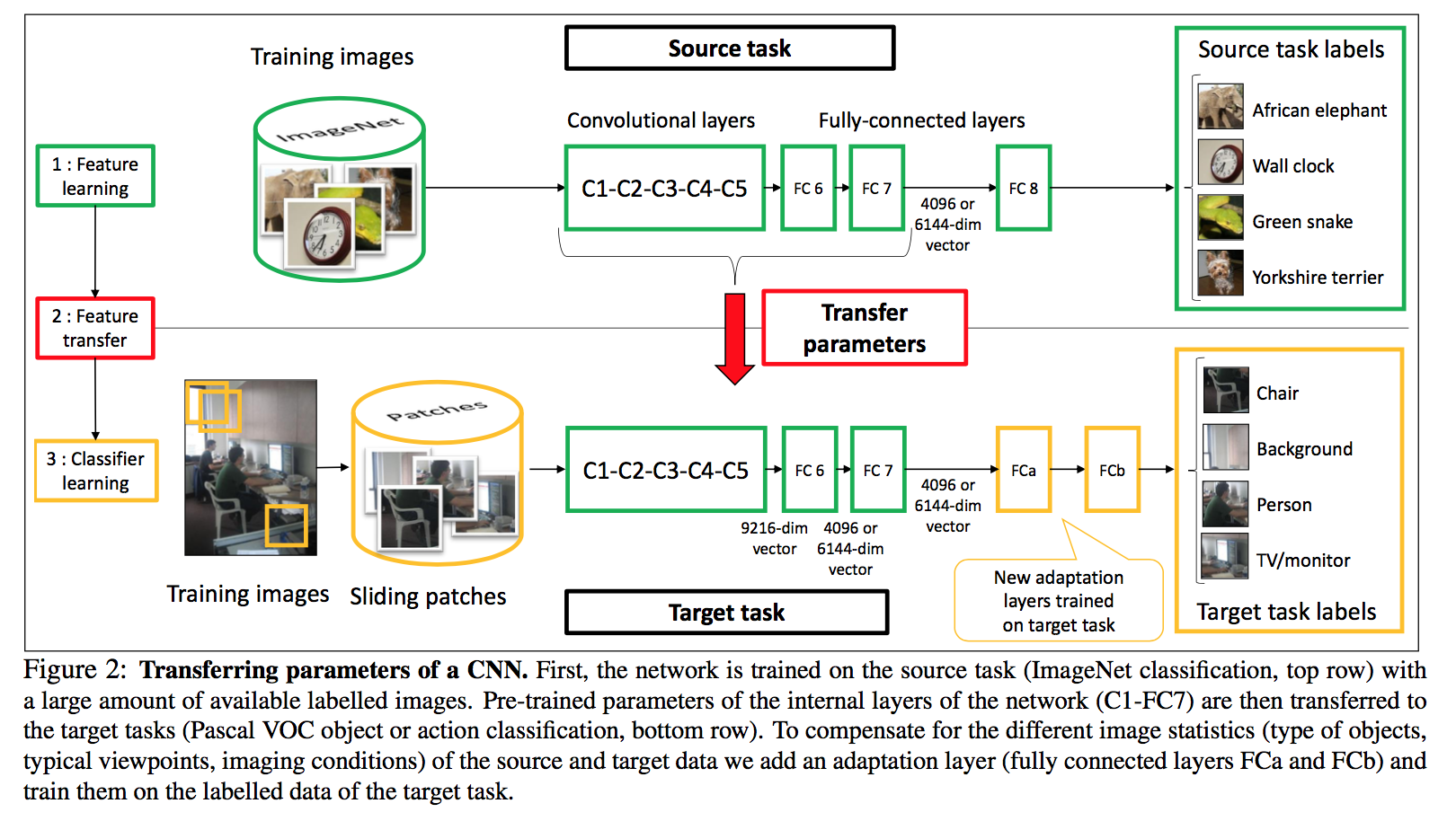](https://user-images.githubusercontent.com/17261080/27133634-2d4c0fde-5113-11e7-848a-719514b1a12c.png) What's a bit more interesting is how they deal with background being overrepresented by using the bounding box that they have. [](https://user-images.githubusercontent.com/17261080/27133641-34d4ee7e-5113-11e7-8307-f1ff708bd5c7.png) #### Results: A bit dated, not really applicable but the part on specifically tackling the domain shift (such as background) is interesting. Plus they use the bounding-box information to refine the dataset. |

Hypercolumns for Object Segmentation and Fine-grained Localization
Bharath Hariharan and Pablo Arbeláez and Ross Girshick and Jitendra Malik
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/21 (9 years ago)
Abstract: Recognition algorithms based on convolutional networks (CNNs) typically use the output of the last layer as feature representation. However, the information in this layer may be too coarse to allow precise localization. On the contrary, earlier layers may be precise in localization but will not capture semantics. To get the best of both worlds, we define the hypercolumn at a pixel as the vector of activations of all CNN units above that pixel. Using hypercolumns as pixel descriptors, we show results on three fine-grained localization tasks: simultaneous detection and segmentation[22], where we improve state-of-the-art from 49.7[22] mean AP^r to 60.0, keypoint localization, where we get a 3.3 point boost over[20] and part labeling, where we show a 6.6 point gain over a strong baseline.
more
less
Bharath Hariharan and Pablo Arbeláez and Ross Girshick and Jitendra Malik
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/21 (9 years ago)
Abstract: Recognition algorithms based on convolutional networks (CNNs) typically use the output of the last layer as feature representation. However, the information in this layer may be too coarse to allow precise localization. On the contrary, earlier layers may be precise in localization but will not capture semantics. To get the best of both worlds, we define the hypercolumn at a pixel as the vector of activations of all CNN units above that pixel. Using hypercolumns as pixel descriptors, we show results on three fine-grained localization tasks: simultaneous detection and segmentation[22], where we improve state-of-the-art from 49.7[22] mean AP^r to 60.0, keypoint localization, where we get a 3.3 point boost over[20] and part labeling, where we show a 6.6 point gain over a strong baseline.
|
[link]
So the hypervector is just a big vector created from a network:
`"We concatenate features from some or all of the feature
maps in the network into one long vector for every location
which we call the hypercolumn at that location. As an
example, using pool2 (256 channels), conv4 (384 channels)
and fc7 (4096 channels) from the architecture of [28] would
lead to a 4736 dimensional vector."`
So how exactly do we construct the vector?

Each activation map results in a single element of the resulting hypervector. The corresponding pixel location in each activation map is used as if the activation maps were all scaled to the size of the original image.
The paper shows the below formula for the calculation. Here $\mathbf{f}_i$ is the value of the pixel in the scaled space and each $\mathbf{F}_{k}$ are points in the activation map. $\alpha_{ik}$ scales the known values to produce the midway points.
$$\mathbf{f}_i = \sum_k \alpha_{ik} \mathbf{F}_{k}$$
Then the fully connected layers are simply appended to complete the vector.
So this gives us a representation for each pixel but is it a good one? The later layers will have the input pixel in their receptive field. After the first few layers it is expected that the spatial constraint is not strong.
|

Fully Convolutional Networks for Semantic Segmentation
Jonathan Long and Evan Shelhamer and Trevor Darrell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/14 (9 years ago)
Abstract: Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
more
less
Jonathan Long and Evan Shelhamer and Trevor Darrell
arXiv e-Print archive - 2014 via Local arXiv
Keywords: cs.CV
First published: 2014/11/14 (9 years ago)
Abstract: Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
|
[link]
## Terms
* Semantic Segmentation: Traditional segmentation divides the image in visually similar patches. Semantic segmentation on the other hand divides the image in semantically meaningful patches. This usually means to classify each pixel (e.g.: This pixel belongs to a cat, that pixel belongs to a dog, the other pixel is background).
## Main ideas
* Complete neural networks which were trained for image classification can be used as a convolution. Those networks can be trained on Image Net (e.g. VGG, AlexNet, GoogLeNet)
* Use upsampling to (1) reduce training and prediction time (2) improve consistency of output. (See [What are deconvolutional layers?](http://datascience.stackexchange.com/a/12110/8820) for an explanation.)
## How FCNs work
1. Train a neural network for image classification which is trained on input images of a fixed size ($d \times w \times h$)
2. Interpret the network as a single convolutional filter for each output neuron (so $k$ output neurons means you have $k$ filters) over the complete image area on which the original network was trained.
3. Run the network as a CNN over an image of any size (but at least $d \times w \times h$) with a stride $s \in \mathbb{N}_{\geq 1}$
4. If $s > 1$, then you need an upsampling layer (deconvolutional layer) to convert the coarse output into a dense output.
## Nice properties
* FCNs take images of arbitrary size and produce an image of the same output size.
* Computationally efficient
## See also:
https://www.quora.com/What-are-the-benefits-of-converting-a-fully-connected-layer-in-a-deep-neural-network-to-an-equivalent-convolutional-layer
> They allow you to treat the convolutional neural network as one giant filter. You can then spatially apply the neural net as a convolution to images larger than the original training image size, getting a spatially dense output.
>
> Let's say you train a neural net (with some loss function) with a convolutional layer (3 x 3, stride of 2), pooling layer (3 x 3, stride of 2), and a fully connected layer with 10 units, using 25 x 25 images. Note that the receptive field size of each max pooling unit is 7 x 7, so the pooling output is 5 x 5. You can convert the fully connected layer to to a set of 10 5 x 5 convolutional filters (unit strides). If you do that, the entire net can be treated as a filter with receptive field size 35 x 35 and stride of 4. You can then take that net and apply it to a 50 x 50 image, and you'd get a 3 x 3 x 10 spatially dense output.
1 Comments
 |

DeepFace: Closing the Gap to Human-Level Performance in Face Verification
Taigman, Yaniv and Yang, Ming and Ranzato, Marc'Aurelio and Wolf, Lior
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
Taigman, Yaniv and Yang, Ming and Ranzato, Marc'Aurelio and Wolf, Lior
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
## General stuff about face recognition
Face recognition has 4 main tasks:
* **Face detection**: Given an image, draw a rectangle around every face
* **Face alignment**: Transform a face to be in a canonical pose
* **Face representation**: Find a representation of a face which is suitable for follow-up tasks (small size, computationally cheap to compare, invariant to irrelevant changes)
* **Face verification**: Images of two faces are given. Decide if it is the same person or not.
The face verification task is sometimes (more simply) a face classification task (given a face, decide which of a fixed set of people it is).
Datasets being used are:
* **LFW** (Labeled Faces in the Wild): 97.35% accuracy; 13 323 web photos of 5 749 celebrities
* **YTF** (YouTube Faces): 3425 YouTube videos of 1 595 subjects
* **SFC** (Social Face Classification): 4.4 million labeled faces from 4030 people, each 800 to 1200 faces
* **USF** (Human-ID database): 3D scans of faces
## Ideas in this paper
This paper deals with face alignment and face representation.
**Face Alignment**
They made an average face with the USF dataset. Then, for each new face, they apply the following procedure:
* Find 6 points in a face (2 eyes, 1 nose tip, 2 corners of the lip, 1 middle point of the bottom lip)
* Crop according to those
* Find 67 points in the face / apply them to a normalized 3D model of a face
* Transform (=align) face to a normalized position
**Representation**
Train a neural network on 152x152 images of faces to classify 4030 celebrities. Remove the softmax output layer and use the output of the second-last layer as the transformed representation.
The network is:
* C1 (convolution): 32 filters of size $11 \times 11 \times 3$ (RGB-channels) (returns $142\times 142$ "images")
* M2 (max pooling): $3 \times 3$, stride of 2 (returns $71\times 71$ "images")
* C3 (convolution): 16 filters of size $9 \times 9 \times 16$ (returns $63\times 63$ "images")
* L4 (locally connected): $16\times9\times9\times16$ (returns $55\times 55$ "images")
* L5 (locally connected): $16\times7\times7\times16$ (returns $25\times 25$ "images")
* L6 (locally connected): $16\times5\times5\times16$ (returns $21\times 21$ "images")
* F7 (fully connected): ReLU, 4096 units
* F8 (fully connected): softmax layer with 4030 output neurons
The training was done with:
* Stochastic Gradient Descent (SGD)
* Momentum of 0.9
* Performance scheduling (LR starting at 0.01, ending at 0.0001)
* Weight initialization: $w \sim \mathcal{N}(\mu=0, \sigma=0.01)$, $b = 0.5$
* ~15 epochs ($\approx$ 3 days) of training
## Evaluation results
* **Quality**:
* 97.35% accuracy (or mean accuracy?) with an Ensemble of DNNs for LFW
* 91.4% accuracy with a single network on YTF
* **Speed**: DeepFace runs in 0.33 seconds per image (I'm not sure which size). This includes image decoding, face detection and alignment, **the** feed forward network (why only one? wasn't this the best performing Ensemble?) and final classification output
## See also
* Andrew Ng: [C4W4L03 Siamese Network](https://www.youtube.com/watch?v=6jfw8MuKwpI)
|
Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
Girshick, Ross B. and Donahue, Jeff and Darrell, Trevor and Malik, Jitendra
Conference and Computer Vision and Pattern Recognition - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
The R-CNN method is a way to localize objects in an image. It is restricted to finding one of each object in an image. 1. Regions are generated based on any method including brute force sliding window. 2. Each region is classified using AlexNet. 3. The classifications for each label are searched to find the location which expresses that label the most. |
Going Deeper with Convolutions
Szegedy, Christian and Liu, Wei and Jia, Yangqing and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
Szegedy, Christian and Liu, Wei and Jia, Yangqing and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew
arXiv e-Print archive - 2014 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper introduces the GoogLeNet Inception Architecture The major part of this paper is the *Inception Module* which takes convolutions at multiple layers and provides a good receptive field as well as reducing the overall number of parameters.  |