[link]
Summary by jerpint 5 years ago
# Summary
This paper presents state-of-the-art methods for both caption generation of images and visual question answering (VQA). The authors build on previous methods by adding what they call a "bottom-up" approach to previous "top-down" attention mechanisms. They show that using their approach they obtain SOTA on both Image captioning (MSCOCO) and the Visual Question and Answering (2017 VQA challenge). They propose a specific network configurations for each. Their biggest contribution is using Faster-R-CNN to retrieve the "important" parts of an image to focus on in both models.
## Top Down
Up until this paper, the traditional approach was to use a "top-down" approach, in which the last feature map layer of a CNN is used to obtain a latent representation of the given input image. These features, along with the context of the caption being generated, were used to generate attention weights that were used to predict the next sequence in the context of caption generation. The network would learn to focus its attention on regions of the feature map that matters most. This is the approach used in previous SOTA methods like [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044).
## Bottom-up
The authors argue that the feature map of a CNN is too generic and can be thought of operating on a uniform, grid-like feature map. In other words, there is no particular reason to think that the feature map of generated by a CNN would give optimal regions to attend to. Also, carefully choosing the dimensions of the feature map can be very arbitrary.
In order to fix this, the authors propose combining object detection methods in a *bottom-up* approach. To do so, the authors propose using Faster-R-CNN to identify regions of interest in an image. Given an input image, Faster-R-CNN will identify bounding boxes of the image that likely correspond to objects of a given category and simultaneously compute a feature vector of that bounding box. Figure 1 shows the difference between the Bottom-up and Top-Down approach.

## Combining the two
In this paper, the authors suggest using the bottom-up approach to compute the salient regions of the image the network should focus on using Faster-R-CNN. FRCNN is carefully pretrained on both imagenet and the Visual Genome dataset. It is then frozen and only used to generate bounding boxes of regions with high confidence of being of interest. The top-down approach is then used on the features obtained from the bottom-up approach. In order to "enhance" the FRCNN performance, they initialize their FRCNN with a ResNet-101 pre-trained on imagenet. They train their FRCNN on the Visual Genome dataset, adding attributes to the loss function that are available from the Visual Genome dataset, attributes such as color (black, white, gold etc.), state (open, close, dark, bright, etc.). A sample of FRCNN outputs are shown in figure 2. It is important to stress that only the feature representations and not the actual outputs (i.e. not the labels) are used in their model.

## Caption Generation
Figure 3 provides a high-level overview of the model being used for caption generation for images. The image is first passed through FRCNN which produces a set of image features *V*. In their specific implementation, *V* consists of *k* vectors of size 1x2048. Their model consists of two LSTM blocks, one for attention and the other for language generation.
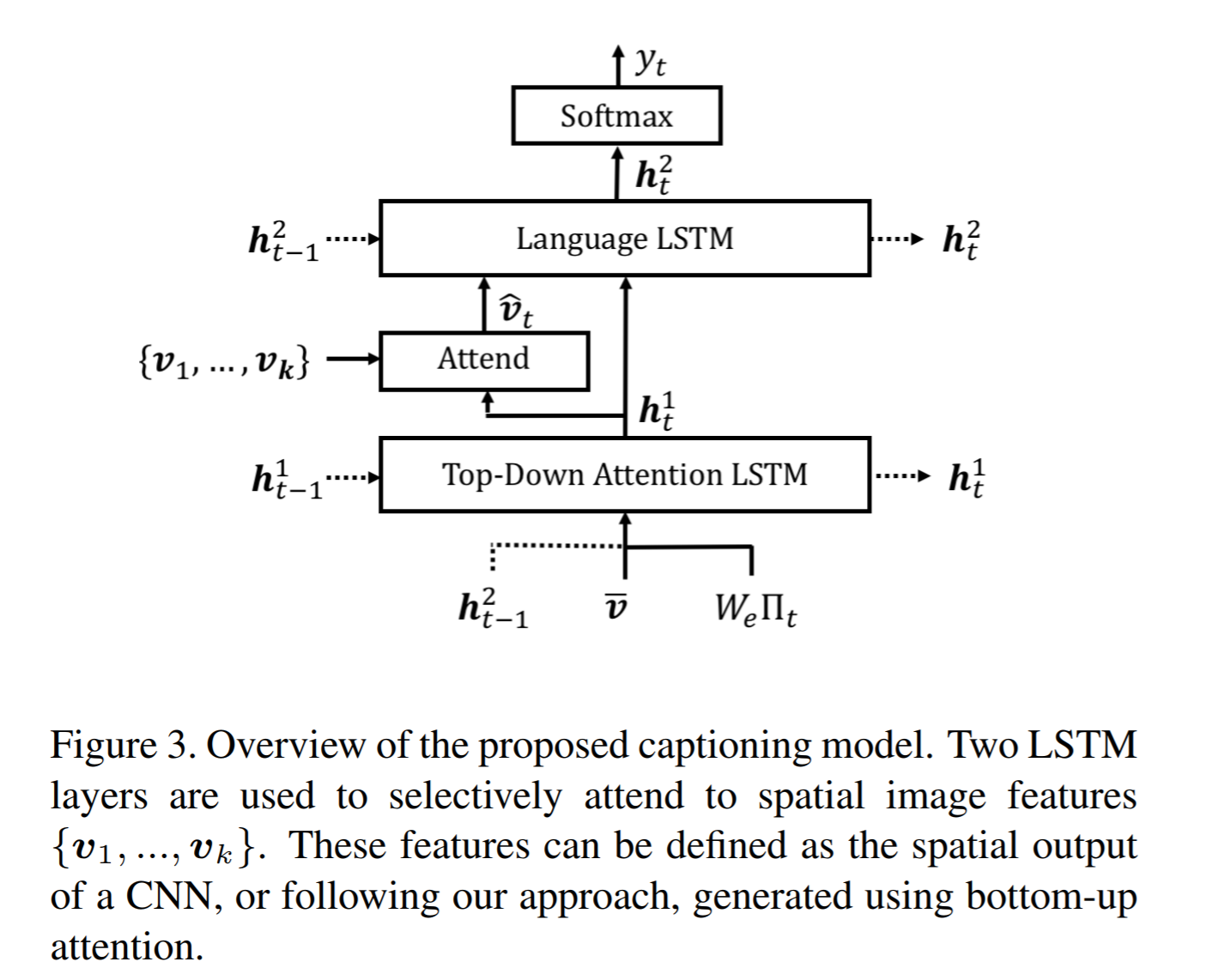
The first block of their model is a Top-Down Attention LSTM layer. It takes as input the mean-pooled features *V* , i.e. 1/k*sum(v_i), concatenated with the previous timestep's hidden representation of the language LSTM as well as the word embedding of the previously generated word. The word embedding is learned and not pretrained.
The output of the first LSTM is used to compute the attention for each vector using an MLP and softmax:

The attention weighted image feature is then used as an input to the language LSTM model, concatenated with the output from the top-down Attention LSTM and a softmax is used to predict the next word in the sequence. The loss function seeks to minimize the cross-entropy of the generated sentence.
## VQA Model
The VQA task differs to the image generation in that a text-based question accompanies an input image and the network must produce an answer. The VQA model proposed is different to that of the caption generation model previously described, however they both use the same bottom-up approach to generate the feature vectors of the image based on the FRCNN architecture. A high-level overview of the architecture for the VQA model is presented in Figure 4.
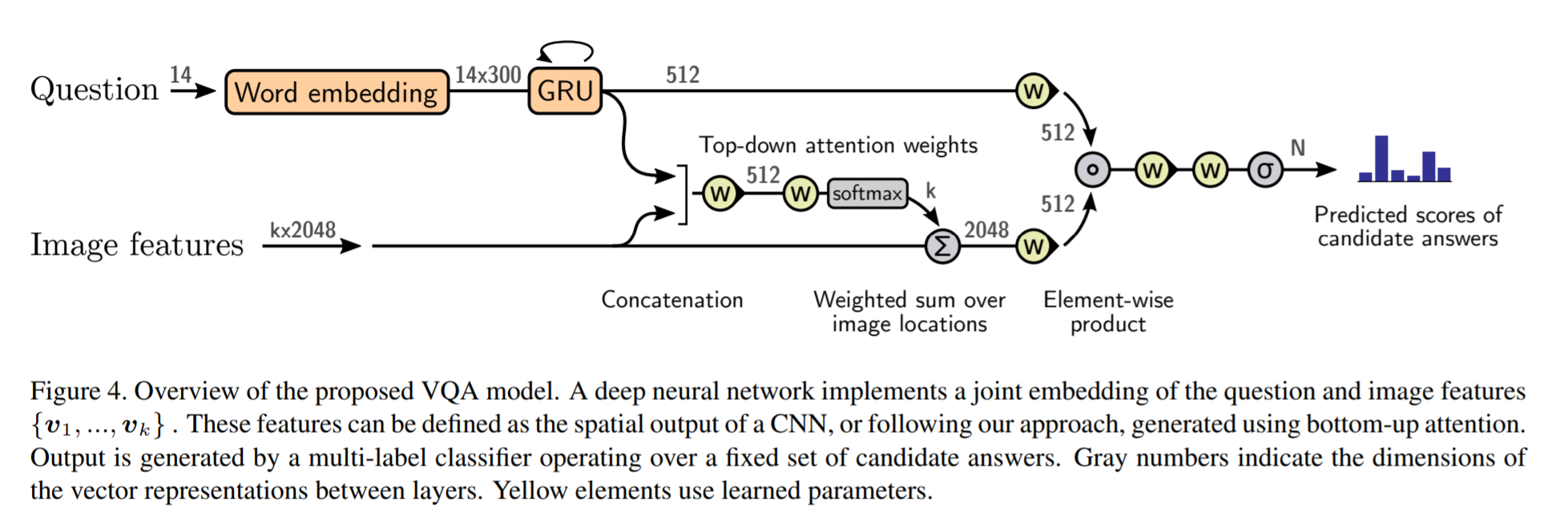
Each word from the question is converted to a learned word embedding which is used as input to a GRU. The number of words for each question is limited to 14 for computational efficiency. The output from the GRU is concatenated with each of the *k* image features, and attention weights are computed for each *k*th feature using an MLP and softmax, similar to what is done in the attention for caption generation. The weighted sum of the feature vectors is then passed through an linear layer such that its shape is compatible with the gru output, and the Hadamard product (element-wise product) is computed over the GRU output and attention-weighted image feature representation. Finally, a tanh non-linear activation is used. This results in a "gated tanh", which have been shown empirically to outperform both ReLU and tanh. Finally, a softmax probability distribution is generated at the output which selects a candidate answer among all possible candidate answers.
## Results and experiments
### Resnet Baseline
To demonstrate that their contribution of bottom-up mechanism actually improves on results, the authors use a ResNet trained on imagenet as a baseline for generating the image feature vectors (they resize the final CNN layers using bilinear interpolation when needed). They consistently obtain better results when using the bottom-up approach over the ResNet approach in both caption generation and VQA.
## MSCOCO
The authors demonstrate that they outperform all results on all metrics on the MSCOCO test server.
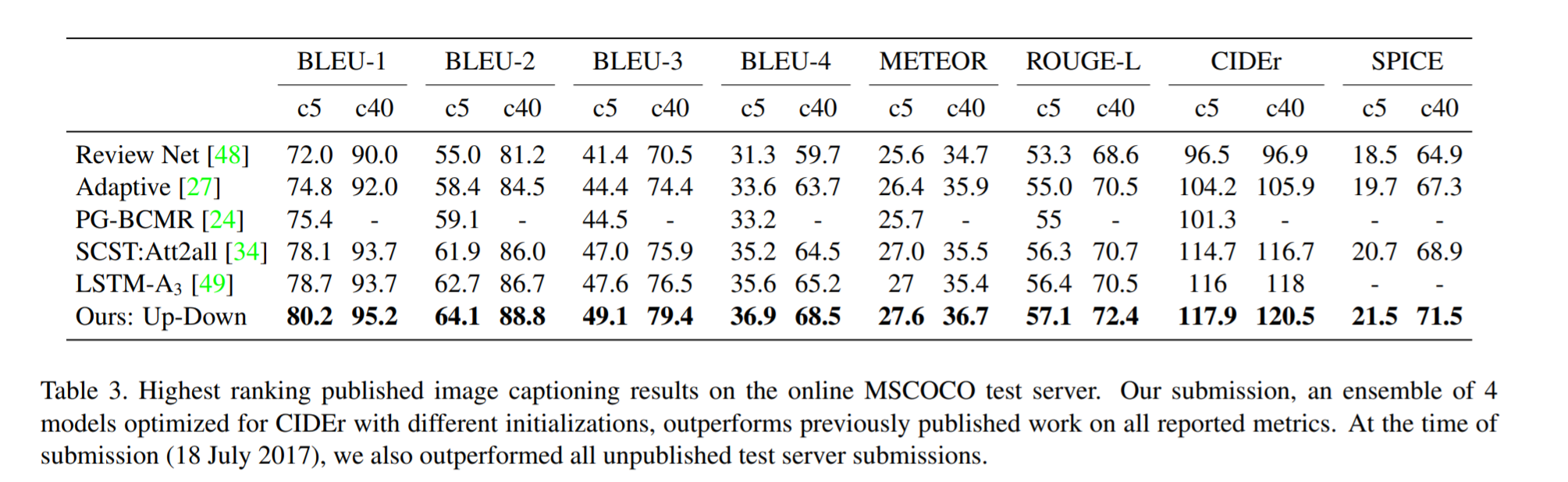
They also show how using the bottom-up approach over ResNet consistently scores them higher on detecting instances of objects, attributes, relations, etc:

The authors, like their predecessors, insist on demonstrating their network's frisbee ability:

## VQA Results
They also demonstrate that the addition of bottom-up attention improves results over a ResNet baseline.
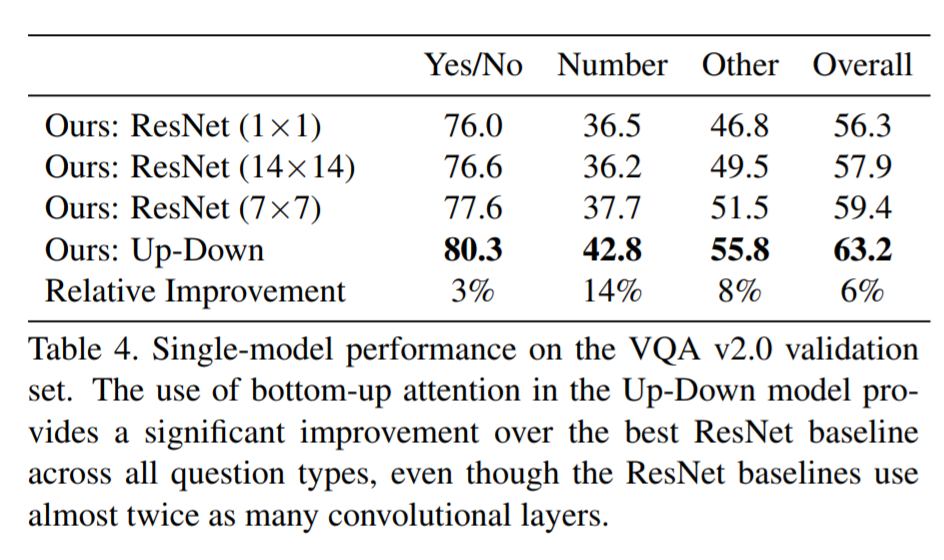
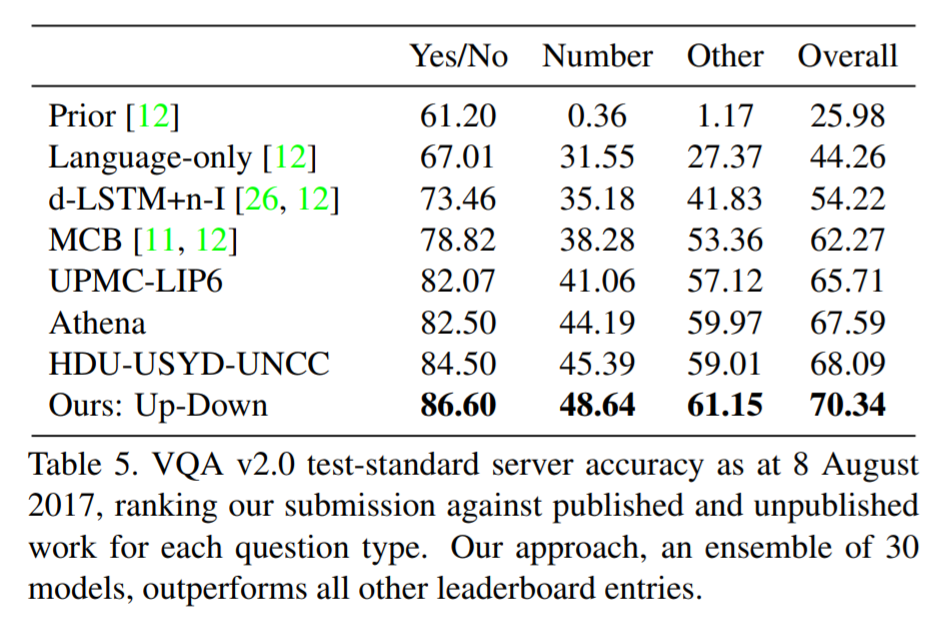
They also show that their model outperformed all other submissions on the VQA submission. They mention using an ensemble of 30 models for their submission.
A sample image of what is attended in an image given a proper answer is shown in figure 6.

# Comments
The authors introduce a new way to select portions of the image on which to focus attention. The idea is very original and came at a time when object detection was making significant progress (i.e. FRCNN).
A few comments:
* This method might not generalize well to other types of data. It requires pre-training on larger datasets (visual genome, imagenet, etc.) which consist of categories that overlap with both the MSCOCO and VQA datasets (i.e. cars, people, etc.). It would be interesting to see an end-to-end model that does not rely on pre-training on other similar datasets.
* No insight is given to the computational complexity nor to the inference time or training time. I imagine that FRCNN is resource intensive, and having to do a forward pass of FRCNN for every pass of the network must be a computational bottleneck. Not to mention that they ensembled 30 of them!


















