
arXiv is an e-print service in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance and statistics.
- 1996 1
- 2010 1
- 2011 1
- 2012 8
- 2013 31
- 2014 43
- 2015 134
- 2016 231
- 2017 182
- 2018 141
- 2019 100
- 2020 33
- 2021 10
- 2022 7
- 2023 3
Women also Snowboard: Overcoming Bias in Captioning Models (Extended Abstract)
Lisa Anne Hendricks and Kaylee Burns and Kate Saenko and Trevor Darrell and Anna Rohrbach
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2024/07/27 (just now)
Abstract: Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data. This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over reliance on the learned prior and image context. We investigate generation of gender specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender specific prediction. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men.
more
less
Lisa Anne Hendricks and Kaylee Burns and Kate Saenko and Trevor Darrell and Anna Rohrbach
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2024/07/27 (just now)
Abstract: Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data. This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over reliance on the learned prior and image context. We investigate generation of gender specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender specific prediction. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men.













[link]
This paper is to reduce gender bias in the captioning model. Concretely, traditional captioning models tend to rely on contextual cues, so they usually predict incorrect captions for an image that contains people.
To reduce gender bias, they introduced a new $Equalizer$ model that contains two losses:
(1) Appearance Confusion Loss: When it is hard to tell if there is a man or a woman in the image, the model should provide a fair probability of predicting a man or a woman.
To define that loss, first, they define a confusion function, which indicates how likely a next predicted word belongs to a set of woman words or a set of man words.
https://i.imgur.com/oI6xswy.png
Where, $w~_{t}$ is the next predicted word, $G_{w}$ is the set of woman words, $G_{m}$ is the set of man words.
And the Loss is defined as the normal cross-entropy loss multiplied by the Confusion function.
https://i.imgur.com/kLpROse.png
(2) Confident Loss: When it is easy to recognize a man or a woman in an image, this loss encourages the model to predict gender words correctly.
In this loss, they also defined in-confidence functions, there are two in-confidence functions, the first one is the in-confidence function for man words, and the second one is for woman words. These two functions are the same.
https://i.imgur.com/4stFjac.png
This function tells that if the model is confident when predicting a gender (ex. woman), then the value of the in-confidence function for woman words should be low.
Then, the confidence loss function is as follows:
https://i.imgur.com/1pRgDir.png
 |

Learning to Count Objects in Natural Images for Visual Question Answering
Zhang, Yan and Hare, Jonathon S. and Prügel-Bennett, Adam
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Zhang, Yan and Hare, Jonathon S. and Prügel-Bennett, Adam
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Visual Question Answering can not do the counting objects problem properly. So in this paper, they figured out the reason is due to the Soft Attention module, and they also proposed a module that can produce reliable counting from object proposals.
There are two challenges in VQA Counting tasks:
(1) There is no ground truth label for the objects to be counted.
(2) The additional module should not affect performance on non-counting problems.
Why Soft Attention is not good for the counting task:
One case to explain why Soft Attention limits counting ability:
Consider the task of counting cats for two images: an image of a cat and an image that contains two images side-by-side that are copies of the first image.
For image 1: after the normalization of the softmax function in the attention, the cat in this image will receive a normalized weight of 1.
For image 2: each cat receives a weight of 0.5.
Then, the attention module will do the weighted sum to produce an attention feature vector. Because the weighted sum process will average the two cats in the second image back to a single cat, so 2 attention feature vectors of the two images are the same. As a result, the information about possible counts is lost by using the attention map.
Counting Component:
This component will be in charge of counting objects for an image. This has two things to do:
1) A differentiable mechanism for counting from attention weights.
2) Handling overlapping object proposals to reduce object double-counting.
The Counting Component is as follows:
https://i.imgur.com/xVGcaov.png
Note that, intra-objects are objects that point to the same object and the same class, while inter-objects are objects that point to the different object and the same class.
They have three main components: (1) object proposals (4 vertices), the black ones are relevant objects while the white ones are irrelevant objects. Then (2) intra-object edges between duplicate proposals, and (3) blue edges mark the inter-object duplicate edges. Finally, there will be one edge and 2 vertices (2 relevant objects).
To illustrate the component in more detail, there are 4 main steps:
(1) Input: The component needs n attention weights $a = [a_{1}, a_{2},...,a_{n}]^{T}$ and their corresponding boxes $b = [b_{1}, ..., b_{n}]^{T}$
(2) Deduplication: The goal of this step is to make a graph $A=aa^{T}$ (attention matrix) where each vertex is a bounding box proposal if the $ith$ bounding box is a relevant box, then $a_{i} = 1$ otherwise, $a_{i} = 0$.
And the Counting Component will modify this graph to delete those edges until the graph becomes a fully directed graph with self-loops.
For example, [a1, a2, a3, a4, a5]=[1,0,1,0,1], the subgraph containing a1, a3, or a5 is a fully directed graph, as follows:
https://i.imgur.com/cCKIQ0K.png
The illustration for this graph is as follows:
https://i.imgur.com/x93gk8c.png
Then we will eliminate duplicate edges:
(1) intra-object edges and (2) inter-object edges.
1. Intra-object edges
First, we eliminate intra-object edges.
To achieve this, we need to calculate the distance matrix $D$ where $D_{ij} = 1- IoU(b_{i}, b_{j})$, if $D_{ij}=1$ which means two bounding boxes are quite overlapped, and then should be eliminated.
To remove them, multiply the attention matrix $A$, which is calculated before, with the matrix $D$, to remove the connection between duplicate proposals of a single object.
https://i.imgur.com/TQAvAnW.png
2. Inter-object edges
Second, we eliminate inter-object edges.
The main idea is to combine the proposals of the duplicate objects into 1.
To do this, scale down the weight of its associated edges (vertices connected to that vertex).
For example, if an object has two proposals, the edges involving those proposals should be scaled by 0.5. Essentially, this is averaging the proposal within each base object, since we only use the sum of edge weights to compute the final count.
https://i.imgur.com/4An0BAj.png
|
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Tan, Mingxing and Chen, Bo and Pang, Ruoming and Vasudevan, Vijay and Le, Quoc V.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Tan, Mingxing and Chen, Bo and Pang, Ruoming and Vasudevan, Vijay and Le, Quoc V.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
When machine learning models need to run on personal devices, that implies a very particular set of constraints: models need to be fairly small and low-latency when run on a limited-compute device, without much loss in accuracy. A number of human-designed architectures have been engineered to try to solve for these constraints (depthwise convolutions, inverted residual bottlenecks), but this paper's goal is to use Neural Architecture Search (NAS) to explicitly optimize the architecture against latency and accuracy, to hopefully find a good trade-off curve between the two. This paper isn't the first time NAS has been applied on the problem of mobile-optimized networks, but a few choices are specific to this paper. 1. Instead of just optimizing against accuracy, or optimizing against accuracy with a sharp latency requirement, the authors here construct a weighted loss that includes both accuracy and latency, so that NAS can explore the space of different trade-off points, rather than only those below a sharp threshold. 2. They design a search space where individual sections or "blocks" of the network can be configured separately, with the hope being that this flexibility helps NAS trade off complexity more strongly in the early parts of the network, where, at a higher spatial resolution, it implies greater computation cost and latency, without necessary dropping that complexity later in the network, where it might be lower-cost. Blocks here are specified by the type of convolution op, kernel size, squeeze-and-excitation ratio, use of a skip op, output filter size, and the number of times an identical layer of this construction will be repeated to constitute a block. Mechanically, models are specified as discrete strings of tokens (a block is made up of tokens indicating its choices along these design axes, and a model is made up of multiple blocks). These are represented in a RL framework, where a RNN model sequentially selects tokens as "actions" until it gets to a full model specification . This is repeated multiple times to get a batch of models, which here functions analogously to a RL episode. These models are then each trained for only five epochs (it's desirable to use a full-scale model for accurate latency measures, but impractical to run its full course of training). After that point, accuracy is calculated, and latency determined by running the model on an actual Pixel phone CPU. These two measures are weighted together to get a reward, which is used to train the RNN model-selection model using PPO. https://i.imgur.com/dccjaqx.png Across a few benchmarks, the authors show that models found with MNasNet optimization are able to reach parts of the accuracy/latency trade-off curve that prior techniques had not. |

Data-Efficient Hierarchical Reinforcement Learning
Ofir Nachum and Shixiang Gu and Honglak Lee and Sergey Levine
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2024/07/27 (just now)
Abstract: Hierarchical reinforcement learning (HRL) is a promising approach to extend traditional reinforcement learning (RL) methods to solve more complex tasks. Yet, the majority of current HRL methods require careful task-specific design and on-policy training, making them difficult to apply in real-world scenarios. In this paper, we study how we can develop HRL algorithms that are general, in that they do not make onerous additional assumptions beyond standard RL algorithms, and efficient, in the sense that they can be used with modest numbers of interaction samples, making them suitable for real-world problems such as robotic control. For generality, we develop a scheme where lower-level controllers are supervised with goals that are learned and proposed automatically by the higher-level controllers. To address efficiency, we propose to use off-policy experience for both higher and lower-level training. This poses a considerable challenge, since changes to the lower-level behaviors change the action space for the higher-level policy, and we introduce an off-policy correction to remedy this challenge. This allows us to take advantage of recent advances in off-policy model-free RL to learn both higher- and lower-level policies using substantially fewer environment interactions than on-policy algorithms. We term the resulting HRL agent HIRO and find that it is generally applicable and highly sample-efficient. Our experiments show that HIRO can be used to learn highly complex behaviors for simulated robots, such as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods, we find that our approach substantially outperforms previous state-of-the-art techniques.
more
less
Ofir Nachum and Shixiang Gu and Honglak Lee and Sergey Levine
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2024/07/27 (just now)
Abstract: Hierarchical reinforcement learning (HRL) is a promising approach to extend traditional reinforcement learning (RL) methods to solve more complex tasks. Yet, the majority of current HRL methods require careful task-specific design and on-policy training, making them difficult to apply in real-world scenarios. In this paper, we study how we can develop HRL algorithms that are general, in that they do not make onerous additional assumptions beyond standard RL algorithms, and efficient, in the sense that they can be used with modest numbers of interaction samples, making them suitable for real-world problems such as robotic control. For generality, we develop a scheme where lower-level controllers are supervised with goals that are learned and proposed automatically by the higher-level controllers. To address efficiency, we propose to use off-policy experience for both higher and lower-level training. This poses a considerable challenge, since changes to the lower-level behaviors change the action space for the higher-level policy, and we introduce an off-policy correction to remedy this challenge. This allows us to take advantage of recent advances in off-policy model-free RL to learn both higher- and lower-level policies using substantially fewer environment interactions than on-policy algorithms. We term the resulting HRL agent HIRO and find that it is generally applicable and highly sample-efficient. Our experiments show that HIRO can be used to learn highly complex behaviors for simulated robots, such as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods, we find that our approach substantially outperforms previous state-of-the-art techniques.
|
[link]
# Keypoints
- Proposes the HIerarchical Reinforcement learning with Off-policy correction (**HIRO**) algorithm.
- Does not require careful task-specific design.
- Generic goal representation to make it broadly applicable, without any manual design of goal spaces, primitives, or controllable dimensions.
- Use of off-policy experience using a novel off-policy correction.
- A two-level hierarchy architecture
- A higher-level controller outputs a goal for the lower-level controller every **c** time steps and collects the rewards given by the environment, being the goal the desired change in state space
- The lower level controller has the goal given added to its input and acts directly in the environment, the reward received is parametrized from the current state and the goal.
# Background
This paper adopts a standard continuous control reinforcement learning setting, in which an agent acts on an environment that yields a next state and a reward from unknown functions. This paper utilizes the TD3 learning algorithm.
## General and Efficient Hierarchical Reinforcement Learning
https://i.imgur.com/zAHoWWO.png
## Hierarchy of Two Policies
The higher-level policy $\mu^{hi}$ outputs a goal $g_t$, which correspond directly to desired relative changes in state that the lower-level policy $\mu^{lo}$ attempts to reach. $\mu^{hi}$ operates at a time abstraction, updating the goal $g_t$ and collecting the environment rewards $R_t$ every $c$ environment steps, the higher-level transition $(s_{t:t+c−1},g_{t:t+c−1},a_{t:t+c−1},R_{t:t+c−1},s_{t+c})$ is stored for off-policy training.
The lower-level policy $\mu^{lo}$ outputs an action to be applied directly to the environment, having as input the current environment observations $s_t$ and the goal $g_t$. The goal $g_t$ is given by $\mu^{hi}$ every $c$ environment time steps, for the steps in between, the goal $g_t$ used by $\mu^{lo}$ is given by the transition function $g_t=h(s_{t−1},g_{t−1},s_t)$, the lower-level controller reward is provided by the parametrized reward function $r_t=r(s_t,g_t,a_t,s_{t+1})$. The lower-level transition $(s_t,g_t,a_t,r_t,s_{t+1}, g_{t+1})$ is stored for off-policy training.
## Parameterized Rewards
The goal $g_t$ indicates a desired relative changes in state observations, the lower-level agent task is to take actions from state $s_t$ that yield it an observation $s_{t+c}$ that is close to $s_t+g_t$. To maintain the same absolute position of the goal regardless of state change, the goal transition model, used between $\mu^{hi}$ updates every $c$ steps, is defined as:
$h(s_t,g_t,s_{t+1}) =s_t+g_t−s_{t+1}$
And the reward given to the lower-level controller is defined as to reinforce reaching a state closer to the goal $g_t$, this paper parametrizes it by the function:
$r(s_t,g_t,a_t,s_{t+1}) =−||s_t+g_t−s_{t+1}||_2$.
## Off-Policy Corrections for Higher-Level Training
The higher-level transitions stored $(s_{t:t+c−1},g_{t:t+c−1},a_{t:t+c−1},R_{t:t+c−1},s_{t+c})$ have to be converted to state-action-reward transitions $(s_t,g_t,∑R_{t:t+c−1},s_{t+c})$ as they can be used in standard off-policy RL algorithms, however, since the lower-level controller is evolving, these past transitions do not accurately represent the actions tha would be taken by the current lower-level policy and must be corrected.
This paper correction technique used is to change the goal $g_t$ of past transitions using an out of date lower-level controller to a relabeled goal $g ̃_t$ which is likely to induce the same lower-level behavior with the updated $\mu^{lo}$. In other words, we want to find a goal $g ̃_t$ which maximizes the probability $μ_{lo}(a_{t:t+c−1}|s_{t:t+c−1},g ̃_{t:t+c−1})$, in which the $\mu^{lo}$ is the current policy and the actions $a_{t:t+c−1}$ and states $s_{t:t+c−1}$ are from the stored high level transition.
To approximately maximize this quantity in practice, the authors calculated the probability for 10 candidates $g ̃_t$, eight candidate goals sampled randomly from a Gaussian centered at $s_{t+c}−s_t$, the original goal $g_t$ and a goal corresponding to the difference $s_{t+c}−s_t$.
# Experiments
https://i.imgur.com/iko9nCd.png
https://i.imgur.com/kGx8fZv.png
The authors compared the $HIRO$ method to prior method in 4 different environments:
- Ant Gather;
- Ant Maze;
- Ant Push;
- Ant Fall.
They also performed an ablative analysis with the following variants:
- With lower-level re-labeling;
- With pre-training;
- No off-policy correction;
- No HRL.
# Closing Points
- The method proposed is interesting in the hierarchical reinforcement learning setting for not needing a specific design, the generic goal representation enables applicability without the need of designing a goal space manually;
- The off-policy correction method enables this algorithm to be sample efficient;
- The hierarchical structure with intermediate goals on state-space enables to better visualize the agent goals;
- The paper Appendix elaborates on possible alternative off-policy corrections.
|

Recurrent World Models Facilitate Policy Evolution
David Ha and Jürgen Schmidhuber
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/09/04 (5 years ago)
Abstract: A generative recurrent neural network is quickly trained in an unsupervised manner to model popular reinforcement learning environments through compressed spatio-temporal representations. The world model's extracted features are fed into compact and simple policies trained by evolution, achieving state of the art results in various environments. We also train our agent entirely inside of an environment generated by its own internal world model, and transfer this policy back into the actual environment. Interactive version of paper at https://worldmodels.github.io
more
less
David Ha and Jürgen Schmidhuber
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/09/04 (5 years ago)
Abstract: A generative recurrent neural network is quickly trained in an unsupervised manner to model popular reinforcement learning environments through compressed spatio-temporal representations. The world model's extracted features are fed into compact and simple policies trained by evolution, achieving state of the art results in various environments. We also train our agent entirely inside of an environment generated by its own internal world model, and transfer this policy back into the actual environment. Interactive version of paper at https://worldmodels.github.io
|
[link]
## General Framework
The take-home message is that the challenge of Reinforcement Learning for environments with high-dimensional and partial observations is learning a good representation of the environment. This means learning a sensory features extractor V to deal with the highly dimensional observation (pixels for example). But also learning a temporal representation M of the environment dynamics to deal with the partial observability. If provided with such representations, learning a controller so as to maximize a reward is really easy (single linear layer evolved with CMA-ES).
Authors call these representations a *World model* since they can use the learned environment's dynamics to simulate roll-outs. They show that policies trained inside the world model transfer well back to the real environment provided that measures are taken to prevent the policy from exploiting the world model's inaccuracies.
## Method
**Learning the World Model**

In this work they propose to learn these representations off-line in an unsupervized manner in order to be more efficient.
They use a VAE for V that they train exclusively with the reconstruction loss, that way the learned representations are independent of the reward and can be used alongside any reward. They then train M as Mixture-Density-Network-RNN to predict the next sensory features (as extracted by the VAE) --and possibly the done condition and the reward-- and thus learn the dynamics of the environment in the VAE's latent space (which is likely simpler there than in the pixel space).
Note that the VAE's latent space is a single Gaussian (adding stochasticity makes it more robust to the "next state" outputs of M), whereas M outputs next states in a mixture of Gaussians. Indeed, an image is likely to have one visual encoding, yet it can have multiple and different future scenarii which are captured by the multimodal output of M.
**Training the policy**

* In the real env:
The agent is provided with the visual features and M's hidden state (temporal features).
* In the world model:
To avoid that the agent exploits this imperfect simulator they increase its dynamics' stochasticity by playing with $\tau$ the sampling temperature of $z_{t+1}$ in M.
## Limitations
If exploration is important in the environment the initial random policy might fail to collect data in all the relevant part of the environment and an iterative version of Algorithm 1 might be required (see https://worldmodels.github.io/ for a discussion on the different iterative methods) for the data collection.
By training V independently of M it might fail to encode all the information relevant to the task. Another option would be to train V and M concurrently so that the reward and $z_{t+1}$'s prediction loss (or next state reconstruction loss) of M flows through V (that would also be trained with its own reconstruction loss). The trade-off is that now V is tuned to a particular reward and cannot be reused.
The authors argue that since $h_t$ is such that it can predict $z_{t+1}$, it contains enough insight about the future for the agent not needing to *plan ahead* and just doing reflexive actions based on $h_t$. This is interesting but the considered tasks (driving, dodging fireball) are still very reflexive and do not require much planning.
## Results
When trained on the true env, a simple controller with the V and M representations achieve SOTA on car-racing. V + M is better than V alone.
When trained inside the world model, its dynamics' stochasticity must be tuned in order for the policy to transfer well and perform well on the real env: too little stochasticity and the agent overfits to the world model flaws and does not transfer to the real env, too much and the agent becomes risk-averse and robust but suboptimal.

## Additional ressources
Thorough interactive blog post with additional experiments and discussions: https://worldmodels.github.io/
|

Junction Tree Variational Autoencoder for Molecular Graph Generation
Jin, Wengong and Barzilay, Regina and Jaakkola, Tommi S.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Jin, Wengong and Barzilay, Regina and Jaakkola, Tommi S.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Prior to this paper, most methods that used machine learning to generate molecular blueprints did so using SMILES representations - a string format with characters representing different atoms and bond types. This preference came about because ML had existing methods for generating strings that could be built on for generating SMILES (a particular syntax of string). However, an arguably more accurate and fundamental way of representing molecules is as graphs (with atoms as nodes and bonds as edges). Dealing with molecules as graphs avoids the problem of a given molecule having many potential SMILES representations (because there's no canonical atom to start working your way around the molecule on), and, hopefully, would have an inductive bias that somewhat more closely matches the actual biomechanical interactions within a molecule. One way you could imagine generating a graph structure is by adding on single components (atoms or bonds) at a time. However, the authors of this paper argue that this approach is harder to constrain to only construct valid molecular graphs, since, in the course of sampling out a molecule, you'd have to go through intermediate stages that you expect to be invalid (for example, bonds with no attached atoms), making it hard to add in explicit validity checks. The alternate approach proposed here works as follows: - Atoms within molecules are grouped into valid substructures, based on a combination of biologically-motivated rules (like treating aromatic rings as a single substructure) and computational heuristics. For the purpose of this paper, substructures are generally either 1) a ring, 2) two particular atoms on either end of a bond, or 3) a "tail" with a bond and an atom. Importantly, these substructures are designed to be overlapping - if you had a N bonded with O, and then O with C (this example are entirely made up, and I expect chemically incoherent), then you could have "N-O" as one substructure, and "O-C" as another. https://i.imgur.com/yGzRPjT.png - Using these substructures (or clusters), you can form a simplified representation of a molecule, as a connected, non-cyclic junction tree of clusters connected together. This doesn't give you all the information you'd need to construct the molecule - since there could be multiple different ways, on a molecular level, to connect two substructures, but it does give a blueprint of what the molecule will look like. - Given these two representations, the paper proposes a two-step encoding and decoding process. For a given molecule, we encode both the full molecular graph and the simplified junction tree, getting out vectors Zg and Zt respectively. - The first step of decoding generates a tree given the Zt representation. This generation process works via graph message-passing, taking in the Zt vector in addition to whatever part of the tree exists, and predicting a probability for whether that node has a child, and, if it exists, a probability for what cluster is at that child node. Given this parametrized set of probabilities, we can calculate the probability of the junction tree representation of whatever ground truth molecule we're decoding, and train the tree decoder to increase that model likelihood. (Importantly, although we frame this step as "reconstruction," during training, we're not actually sampling discrete nodes and edges, because we couldn't backprop through that, we're just defining a probability distribution and trying to increase the probability of our real data under it). - The second step of decoding takes in a tree - which at this point is a set of cluster labels with connections specified between one another - as well as the Zg vector, and generates a full, atom-level graph. This is done by enumerating all the ways that two substructures could be attached (this number is typically small, ≤4), and learning a parametrized function that scores each possible type of connection, based on the full tree "blueprint", the Zg embedding, and the molecule that has been generated so far. - When you want to sample a new molecule, you can draw a sample from the prior distributions of Zg and Zt, and run the decoding process in a sampling mode, actually making discrete draws from the distributions given by your model https://i.imgur.com/QdSY25u.png The authors perform three empirical tests: ability to successfully sample-reconstruct a given molecule, ability to optimize for a desired chemical property by finding a Z that scores high on that property according to an auxiliary predictive model, and ability to optimize for a property while staying within a given similarity radius to an original anchor molecule. The Junction Tree approach outperforms on all three tasks. On reconstruction, it matches the best alternative method on reconstruction reliability, but with 100% valid molecules, rather than 43.5% on the competing method. Overall, I found this paper really enjoyable and satisfying to read. Occasionally, ML-for-bio papers err on the side of too little domain thought (just throwing the most generic-for-images model structure at a problem), or too little machine learning thought (take hand-designed features and throw them at a whole range of models), where I think this one struck a nice balance of some amount of domain knowledge (around what makes for valid substructures) but embedded in a complex and thoughtfully designed neural network framework. |
Low Frequency Adversarial Perturbation
Chuan Guo and Jared S. Frank and Kilian Q. Weinberger
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/09/24 (5 years ago)
Abstract: Adversarial images aim to change a target model's decision by minimally perturbing a target image. In the black-box setting, the absence of gradient information often renders this search problem costly in terms of query complexity. In this paper we propose to restrict the search for adversarial images to a low frequency domain. This approach is readily compatible with many existing black-box attack frameworks and consistently reduces their query cost by 2 to 4 times. Further, we can circumvent image transformation defenses even when both the model and the defense strategy are unknown. Finally, we demonstrate the efficacy of this technique by fooling the Google Cloud Vision platform with an unprecedented low number of model queries.
more
less
Chuan Guo and Jared S. Frank and Kilian Q. Weinberger
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/09/24 (5 years ago)
Abstract: Adversarial images aim to change a target model's decision by minimally perturbing a target image. In the black-box setting, the absence of gradient information often renders this search problem costly in terms of query complexity. In this paper we propose to restrict the search for adversarial images to a low frequency domain. This approach is readily compatible with many existing black-box attack frameworks and consistently reduces their query cost by 2 to 4 times. Further, we can circumvent image transformation defenses even when both the model and the defense strategy are unknown. Finally, we demonstrate the efficacy of this technique by fooling the Google Cloud Vision platform with an unprecedented low number of model queries.
|
[link]
Guo et al. propose to augment black-box adversarial attacks with low-frequency noise to obtain low-frequency adversarial examples as shown in Figure 1. To this end, the boundary attack as well as the NES attack are modified to sample from a low-frequency Gaussian distribution instead from Gaussian noise directly. This is achieved through an inverse discrete cosine transform as detailed in the paper. https://i.imgur.com/fejvuw7.jpg Figure 1: Example of a low-frequency adversarial example. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |

Semantic Adversarial Examples
Hossein Hosseini and Radha Poovendran
Conference and Computer Vision and Pattern Recognition - 2018 via Local CrossRef
Keywords:
Hossein Hosseini and Radha Poovendran
Conference and Computer Vision and Pattern Recognition - 2018 via Local CrossRef
Keywords:
|
[link]
Hosseini and Poovendran propose semantic adversarial examples by randomly manipulating hue and saturation of images. In particular, in an iterative algorithm, hue and saturation are randomly perturbed and projected back to their valid range. If this results in mis-classification the perturbed image is returned as the adversarial example and the algorithm is finished; if not, another iteration is run. The result is shown in Figure 1. As can be seen, the structure of the images is retained while hue and saturation changes, resulting in mis-classified images. https://i.imgur.com/kFcmlE3.jpg Figure 1: Examples of the computed semantic adversarial examples. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Sensitivity and Generalization in Neural Networks: an Empirical Study
Roman Novak and Yasaman Bahri and Daniel A. Abolafia and Jeffrey Pennington and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG, cs.NE
First published: 2018/02/23 (6 years ago)
Abstract: In practice it is often found that large over-parameterized neural networks generalize better than their smaller counterparts, an observation that appears to conflict with classical notions of function complexity, which typically favor smaller models. In this work, we investigate this tension between complexity and generalization through an extensive empirical exploration of two natural metrics of complexity related to sensitivity to input perturbations. Our experiments survey thousands of models with various fully-connected architectures, optimizers, and other hyper-parameters, as well as four different image classification datasets. We find that trained neural networks are more robust to input perturbations in the vicinity of the training data manifold, as measured by the norm of the input-output Jacobian of the network, and that it correlates well with generalization. We further establish that factors associated with poor generalization $-$ such as full-batch training or using random labels $-$ correspond to lower robustness, while factors associated with good generalization $-$ such as data augmentation and ReLU non-linearities $-$ give rise to more robust functions. Finally, we demonstrate how the input-output Jacobian norm can be predictive of generalization at the level of individual test points.
more
less
Roman Novak and Yasaman Bahri and Daniel A. Abolafia and Jeffrey Pennington and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG, cs.NE
First published: 2018/02/23 (6 years ago)
Abstract: In practice it is often found that large over-parameterized neural networks generalize better than their smaller counterparts, an observation that appears to conflict with classical notions of function complexity, which typically favor smaller models. In this work, we investigate this tension between complexity and generalization through an extensive empirical exploration of two natural metrics of complexity related to sensitivity to input perturbations. Our experiments survey thousands of models with various fully-connected architectures, optimizers, and other hyper-parameters, as well as four different image classification datasets. We find that trained neural networks are more robust to input perturbations in the vicinity of the training data manifold, as measured by the norm of the input-output Jacobian of the network, and that it correlates well with generalization. We further establish that factors associated with poor generalization $-$ such as full-batch training or using random labels $-$ correspond to lower robustness, while factors associated with good generalization $-$ such as data augmentation and ReLU non-linearities $-$ give rise to more robust functions. Finally, we demonstrate how the input-output Jacobian norm can be predictive of generalization at the level of individual test points.
|
[link]
Novak et al. study the relationship between neural network sensitivity and generalization. Here, sensitivity is measured in terms of the Frobenius gradient of the network’s probabilities (resulting in a Jacobian matrix, not depending on the true label) or based on a coding scheme of activations. The latter is intended to quantify transitions between linear regions of the piece-wise linear model. To this end, all activations are assigned either $0$ or $1$ depending on their ReLU output. Based on a path between two or more input examples, the difference in this coding scheme is an estimator of how many linear regions have been “traversed”. Both metrics are illustrated in Figure 1, showing that they are low for test and training examples, or in regions within the same class, and high otherwise. The second metric is also illustrated in Figure 2. Based on these metrics, the authors show that these metrics correlate with the generalization gap, meaning that the sensitivity of the network and its generalization performance seem to be inherently connected. https://i.imgur.com/iRt3ADe.jpg Figure 1: For a network trained on MNIST, illustrations of a possible trajectory (left) and the corresponding sensitivity metrics (middle and right). I refer to the paper for details. https://i.imgur.com/0G8su3K.jpg Figure 2: Linear regions for a random 2-dimensional slice of the pre-logit space before and after training. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Group Normalization
Yuxin Wu and Kaiming He
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2018/03/22 (6 years ago)
Abstract: Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. This limits BN's usage for training larger models and transferring features to computer vision tasks including detection, segmentation, and video, which require small batches constrained by memory consumption. In this paper, we present Group Normalization (GN) as a simple alternative to BN. GN divides the channels into groups and computes within each group the mean and variance for normalization. GN's computation is independent of batch sizes, and its accuracy is stable in a wide range of batch sizes. On ResNet-50 trained in ImageNet, GN has 10.6% lower error than its BN counterpart when using a batch size of 2; when using typical batch sizes, GN is comparably good with BN and outperforms other normalization variants. Moreover, GN can be naturally transferred from pre-training to fine-tuning. GN can outperform its BN-based counterparts for object detection and segmentation in COCO, and for video classification in Kinetics, showing that GN can effectively replace the powerful BN in a variety of tasks. GN can be easily implemented by a few lines of code in modern libraries.
more
less
Yuxin Wu and Kaiming He
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG
First published: 2018/03/22 (6 years ago)
Abstract: Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. This limits BN's usage for training larger models and transferring features to computer vision tasks including detection, segmentation, and video, which require small batches constrained by memory consumption. In this paper, we present Group Normalization (GN) as a simple alternative to BN. GN divides the channels into groups and computes within each group the mean and variance for normalization. GN's computation is independent of batch sizes, and its accuracy is stable in a wide range of batch sizes. On ResNet-50 trained in ImageNet, GN has 10.6% lower error than its BN counterpart when using a batch size of 2; when using typical batch sizes, GN is comparably good with BN and outperforms other normalization variants. Moreover, GN can be naturally transferred from pre-training to fine-tuning. GN can outperform its BN-based counterparts for object detection and segmentation in COCO, and for video classification in Kinetics, showing that GN can effectively replace the powerful BN in a variety of tasks. GN can be easily implemented by a few lines of code in modern libraries.
|
[link]
Wu and He propose group normalization as alternative to batch normalization. Instead of computing the statistics used for normalization based on the current mini-batch, group normalization computes these statistics per instance but in groups of channels (for convolutional layers). Specifically, given activations $x_i$ with $i = (i_N, i_C, i_H, i_W)$ indexing along batch size, channels, height and width, batch normalization computes
$\mu_i = \frac{1}{|S|}\sum_{k \in S} x_k$ and $\sigma_i = \sqrt{\frac{1}{|S|} \sum_{k \in S} (x_k - \mu_i)^2 + \epsilon}$
with the set $S$ holds all indices for a specific channel (i.e. across samples, height and width). For group normalization, in contrast, $S$ holds all indices of the current instance and group of channels. Meaning the statistics are computed across height, width and the current group of channels. Here, all channels can be divided into groups arbitrarily. In the paper, on ImageNet, groups of $32$ channels are used. Then, Figure 1 shows that for a batch size of 32, group normalization performs en-par with batch normalization – although the validation error is slightly larger. This is attributed to the stochastic element of batch normalization that leads to regularization. Figure 2 additionally shows the influence of the batch size of batch normalization and group normalization.
https://i.imgur.com/lwP5ycw.jpg
Figure 1: Training and validation error for different normalization schemes on ImageNet.
https://i.imgur.com/0c3CnEX.jpg
Figure 2: Validation error for different batch sizes.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels
Zhang, Zhilu and Sabuncu, Mert R.
Neural Information Processing Systems Conference - 2018 via Local Bibsonomy
Keywords: dblp
Zhang, Zhilu and Sabuncu, Mert R.
Neural Information Processing Systems Conference - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Zhang and Sabuncu propose a generalized cross entropy loss for robust learning on noisy labels. The approach is based on the work by Gosh et al. [1] showing that the mean absolute error can be robust to label noise. Specifically, they show that a symmetric loss, under specific assumptions on the label noise, is robust. Here, symmetry corresponds to
$\sum_{j=1}^c \mathcal{L}(f(x), j) = C$ for all $x$ and $f$
where $c$ is the number of classes and $C$ some constant. The cross entropy loss is not symmetric, while the mean absolute error is. The mean absolute error however, usually results in slower learning and may reach lower accuracy. As alternative, the authors propose
$\mathcal{L}(f(x), e_j) = \frac{(1 – f_j(x)^q)}{q}$.
Here, $f$ is the classifier which is assumed to contain a softmax layer at the end. For $q \rightarrow 0$ this reduces to the cross entropy and for $q = 1$ it reduces to the mean absolute error. As shown in Figure 1, this loss (or a slightly adapted version, see paper, respectively) may obtain better performance on noisy labels. To this end, the label noise is assumed to be uniform, meaning that $p(\tilde{y} = k|y = j, x)= 1 - \eta$ where $\tilde{y}$ is the perturbed label.
https://i.imgur.com/HRQ84Zv.jpg
Figure 1: Performance of the proposed loss for different $q$ and noise rate $\eta$ on Cifar-10. A ResNet-34 is used.
[1] Aritra Gosh, Himanshu Kumar, PS Sastry. Robust loss functions under label noise for deep neural networks. AAAI, 2017.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Taming VAEs
Danilo Jimenez Rezende and Fabio Viola
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/01 (5 years ago)
Abstract: In spite of remarkable progress in deep latent variable generative modeling, training still remains a challenge due to a combination of optimization and generalization issues. In practice, a combination of heuristic algorithms (such as hand-crafted annealing of KL-terms) is often used in order to achieve the desired results, but such solutions are not robust to changes in model architecture or dataset. The best settings can often vary dramatically from one problem to another, which requires doing expensive parameter sweeps for each new case. Here we develop on the idea of training VAEs with additional constraints as a way to control their behaviour. We first present a detailed theoretical analysis of constrained VAEs, expanding our understanding of how these models work. We then introduce and analyze a practical algorithm termed Generalized ELBO with Constrained Optimization, GECO. The main advantage of GECO for the machine learning practitioner is a more intuitive, yet principled, process of tuning the loss. This involves defining of a set of constraints, which typically have an explicit relation to the desired model performance, in contrast to tweaking abstract hyper-parameters which implicitly affect the model behavior. Encouraging experimental results in several standard datasets indicate that GECO is a very robust and effective tool to balance reconstruction and compression constraints.
more
less
Danilo Jimenez Rezende and Fabio Viola
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/01 (5 years ago)
Abstract: In spite of remarkable progress in deep latent variable generative modeling, training still remains a challenge due to a combination of optimization and generalization issues. In practice, a combination of heuristic algorithms (such as hand-crafted annealing of KL-terms) is often used in order to achieve the desired results, but such solutions are not robust to changes in model architecture or dataset. The best settings can often vary dramatically from one problem to another, which requires doing expensive parameter sweeps for each new case. Here we develop on the idea of training VAEs with additional constraints as a way to control their behaviour. We first present a detailed theoretical analysis of constrained VAEs, expanding our understanding of how these models work. We then introduce and analyze a practical algorithm termed Generalized ELBO with Constrained Optimization, GECO. The main advantage of GECO for the machine learning practitioner is a more intuitive, yet principled, process of tuning the loss. This involves defining of a set of constraints, which typically have an explicit relation to the desired model performance, in contrast to tweaking abstract hyper-parameters which implicitly affect the model behavior. Encouraging experimental results in several standard datasets indicate that GECO is a very robust and effective tool to balance reconstruction and compression constraints.
|
[link]
The paper provides derivations and intuitions about the learning dynamics for VAEs based on observations about [$\beta$-VAEs][beta]. Using this they derive an alternative way to constrain the training of VAEs that doesn't require typical heuristics, such as warmup or adding noise to the data. How exactly would this change a typical implementation? Typically, SGD is used to [optimize the ELBO directly](https://github.com/pytorch/examples/blob/master/vae/main.py#L91-L95). Using GECO, I keep a moving average of my constraint $C$ (chosen based on what I want the VAE to do, but it can be just the likelihood plus a tolerance parameter) and use that to calculate Lagrange multipliers, which control the weighting of the constraint to the loss. [This implementation](https://github.com/denproc/Taming-VAEs/blob/master/train.py#L83-L97) from a class project appears to be correct. With the stabilization of training, I can't help but think of this as batchnorm for VAEs. [beta]: https://openreview.net/forum?id=Sy2fzU9gl |

Progress & Compress: A scalable framework for continual learning
Jonathan Schwarz and Jelena Luketina and Wojciech M. Czarnecki and Agnieszka Grabska-Barwinska and Yee Whye Teh and Razvan Pascanu and Raia Hadsell
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/05/16 (6 years ago)
Abstract: We introduce a conceptually simple and scalable framework for continual learning domains where tasks are learned sequentially. Our method is constant in the number of parameters and is designed to preserve performance on previously encountered tasks while accelerating learning progress on subsequent problems. This is achieved by training a network with two components: A knowledge base, capable of solving previously encountered problems, which is connected to an active column that is employed to efficiently learn the current task. After learning a new task, the active column is distilled into the knowledge base, taking care to protect any previously acquired skills. This cycle of active learning (progression) followed by consolidation (compression) requires no architecture growth, no access to or storing of previous data or tasks, and no task-specific parameters. We demonstrate the progress & compress approach on sequential classification of handwritten alphabets as well as two reinforcement learning domains: Atari games and 3D maze navigation.
more
less
Jonathan Schwarz and Jelena Luketina and Wojciech M. Czarnecki and Agnieszka Grabska-Barwinska and Yee Whye Teh and Razvan Pascanu and Raia Hadsell
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/05/16 (6 years ago)
Abstract: We introduce a conceptually simple and scalable framework for continual learning domains where tasks are learned sequentially. Our method is constant in the number of parameters and is designed to preserve performance on previously encountered tasks while accelerating learning progress on subsequent problems. This is achieved by training a network with two components: A knowledge base, capable of solving previously encountered problems, which is connected to an active column that is employed to efficiently learn the current task. After learning a new task, the active column is distilled into the knowledge base, taking care to protect any previously acquired skills. This cycle of active learning (progression) followed by consolidation (compression) requires no architecture growth, no access to or storing of previous data or tasks, and no task-specific parameters. We demonstrate the progress & compress approach on sequential classification of handwritten alphabets as well as two reinforcement learning domains: Atari games and 3D maze navigation.
|
[link]
Proposes a two-stage approach for continual learning. An active learning phase and a consolidation phase. The active learning stage optimizes for a specific task that is then consolidated into the knowledge base network via Elastic Weight Consolidation (Kirkpatrick et al., 2016). The active learning phases uses a separate network than the knowledge base, but is not always trained from scratch - authors suggest a heuristic based on task-similarity. Improves EWC by deriving a new online method so parameters don’t increase linearly with the number of tasks. Desiderata for a continual learning solution: - A continual learning method should not suffer from catastrophic forgetting. That is, it should be able to perform reasonably well on previously learned tasks. - It should be able to learn new tasks while taking advantage of knowledge extracted from previous tasks, thus exhibiting positive forward transfer to achieve faster learning and/or better final performance. - It should be scalable, that is, the method should be trainable on a large number of tasks. - It should enable positive backward transfer as well, which means gaining improved performance on previous tasks after learning a new task which is similar or relevant. - Finally, it should be able to learn without requiring task labels, and ideally, it should even be applicable in the absence of clear task boundaries. Experiments: - Sequential learning of handwritten characters of 50 alphabets taken from the Omniglot dataset. - Sequential learning of 6 games in the Atari suite (Bellemare et al., 2012) (“Space Invaders”, “Krull”, “Beamrider”, “Hero”, “Stargunner” and “Ms. Pac-man”). - 8 navigation tasks in 3D environments inspired by experiments with Distral (Teh et al., 2017). |

19 dubious ways to compute the marginal likelihood of a phylogenetic tree topology
Mathieu Fourment and Andrew F. Magee and Chris Whidden and Arman Bilge and Frederick A. Matsen IV and Vladimir N. Minin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: q-bio.PE, stat.CO
First published: 2018/11/28 (5 years ago)
Abstract: The marginal likelihood of a model is a key quantity for assessing the evidence provided by the data in support of a model. The marginal likelihood is the normalizing constant for the posterior density, obtained by integrating the product of the likelihood and the prior with respect to model parameters. Thus, the computational burden of computing the marginal likelihood scales with the dimension of the parameter space. In phylogenetics, where we work with tree topologies that are high-dimensional models, standard approaches to computing marginal likelihoods are very slow. Here we study methods to quickly compute the marginal likelihood of a single fixed tree topology. We benchmark the speed and accuracy of 19 different methods to compute the marginal likelihood of phylogenetic topologies on a suite of real datasets. These methods include several new ones that we develop explicitly to solve this problem, as well as existing algorithms that we apply to phylogenetic models for the first time. Altogether, our results show that the accuracy of these methods varies widely, and that accuracy does not necessarily correlate with computational burden. Our newly developed methods are orders of magnitude faster than standard approaches, and in some cases, their accuracy rivals the best established estimators.
more
less
Mathieu Fourment and Andrew F. Magee and Chris Whidden and Arman Bilge and Frederick A. Matsen IV and Vladimir N. Minin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: q-bio.PE, stat.CO
First published: 2018/11/28 (5 years ago)
Abstract: The marginal likelihood of a model is a key quantity for assessing the evidence provided by the data in support of a model. The marginal likelihood is the normalizing constant for the posterior density, obtained by integrating the product of the likelihood and the prior with respect to model parameters. Thus, the computational burden of computing the marginal likelihood scales with the dimension of the parameter space. In phylogenetics, where we work with tree topologies that are high-dimensional models, standard approaches to computing marginal likelihoods are very slow. Here we study methods to quickly compute the marginal likelihood of a single fixed tree topology. We benchmark the speed and accuracy of 19 different methods to compute the marginal likelihood of phylogenetic topologies on a suite of real datasets. These methods include several new ones that we develop explicitly to solve this problem, as well as existing algorithms that we apply to phylogenetic models for the first time. Altogether, our results show that the accuracy of these methods varies widely, and that accuracy does not necessarily correlate with computational burden. Our newly developed methods are orders of magnitude faster than standard approaches, and in some cases, their accuracy rivals the best established estimators.
|
[link]
This paper compares methods to calculate the marginal likelihood, $p(D | \tau)$, when you have a tree topology $\tau$ and some data $D$ and you need to marginalise over the possible branch lengths $\mathbf{\theta}$ in the process of Bayesian inference. In other words, solving the following integral:
$$
\int_{ [ 0, \infty ]^{2S - 3} } p(D | \mathbf{\theta}, \tau ) p( \mathbf{\theta} | \tau) d \mathbf{\theta}
$$
There are some details about this problem that are common to phylogenetic problems, such as an exponential prior on the branch lengths, but otherwise this is the common problem of approximate Bayesian inference. This paper compares the following methods:
* ELBO (appears to be [BBVI][])
* Gamma Laplus Importance Sampling
* Variational Bayes Importance Sampling
* Beta' Laplus
* Gamma Laplus
* Maximum un-normalized posterior probability
* Maximum likelihood
* Naive Monte Carlo
* Bridge Sampling
* Conditional Predictive Ordinates
* Harmonic Mean
* Stabilized Harmonic Mean
* Nested Sampling
* Pointwise Predictive Density
* Path Sampling
* Modified Path Sampling
* Stepping Stone
* Generalized Stepping Stone
I leave the in depth description of each algorithm to the paper and appendices, although it's worth mentioning that Laplus is a Laplace approximation where the approximating distribution is constrained to be positive.
Some takeaways from the empirical results:
* If runtime is not a concern power posterior methods are preferred:
> The power posterior methods remain the best general-purpose tools for phylogenetic modelcomparisons, though they are certainly too slow to explore the tree space produced by PT.
* Bridge sampling is the next choice, if you need something faster.
* Harmonic Mean is a bad estimator for phylogenetic tree problems.
* Gamma Laplus is a good fast option.
* Naive Monte Carlo is a poor estimator, which is probably to be expected.
* Gamma Laplus is the best option for very fast algorithms:
> Empirical posterior distributions on branch lengths are clearly not point-masses, and yet simply normalizing the unnormalized posterior at the maximum outperforms 6 of the 19 tested methods.
All methods were compared on metrics important to phylogenetic inference, such as *average standard deviation of split frequencies" (ASDSF), which is typically used to confirm whether parallel MCMC chains are sampling from the same distribution over tree topologies. Methods were also compared on KL divergence to the true posterior and RMSD (appears to be the mean squared error between CDFs?).
[bbvi]: https://arxiv.org/abs/1401.0118
|
Rao-Blackwellized Stochastic Gradients for Discrete Distributions
Runjing Liu and Jeffrey Regier and Nilesh Tripuraneni and Michael I. Jordan and Jon McAuliffe
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/10 (5 years ago)
Abstract: We wish to compute the gradient of an expectation over a finite or countably infinite sample space having $K \leq \infty$ categories. When $K$ is indeed infinite, or finite but very large, the relevant summation is intractable. Accordingly, various stochastic gradient estimators have been proposed. In this paper, we describe a technique that can be applied to reduce the variance of any such estimator, without changing its bias---in particular, unbiasedness is retained. We show that our technique is an instance of Rao-Blackwellization, and we demonstrate the improvement it yields on a semi-supervised classification problem and a pixel attention task.
more
less
Runjing Liu and Jeffrey Regier and Nilesh Tripuraneni and Michael I. Jordan and Jon McAuliffe
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/10 (5 years ago)
Abstract: We wish to compute the gradient of an expectation over a finite or countably infinite sample space having $K \leq \infty$ categories. When $K$ is indeed infinite, or finite but very large, the relevant summation is intractable. Accordingly, various stochastic gradient estimators have been proposed. In this paper, we describe a technique that can be applied to reduce the variance of any such estimator, without changing its bias---in particular, unbiasedness is retained. We show that our technique is an instance of Rao-Blackwellization, and we demonstrate the improvement it yields on a semi-supervised classification problem and a pixel attention task.
|
[link]
This paper approaches the problem of optimizing parameters of a discrete distribution with respect to some loss function that is an expectation over that distribution. In other words, an experiment will probably be a variational autoencoder with discrete latent variables, but there are many real applications:
$$
\mathcal{L} (\eta) : = \mathbb{E}_{z \sim q_{\eta} (z)} \left[ f_{\eta} (z) \right]
$$
Using the [product rule of differentiation][product] the derivative of this loss function can be computed by enumerating all $1 \to K$ possible values of $z$:
$$
\nabla_\eta \mathbb{E}_{z \sim q_{\eta} (z)} \left[ f_{\eta} (z) \right] = \nabla_\eta \sum_{k=1}^{K} q_\eta (k) f_\eta (k) \\
= \sum_{k=1}^{K} f_\eta (k) \nabla_\eta q_\eta (k) + q_\eta (k) \nabla_\eta f_\eta (k)
$$
This expectation can also be expressed as the score function estimator (aka the REINFORCE estimator):
$$
\nabla_\eta \mathbb{E}_{z \sim q_{\eta} (z)} \left[ f_{\eta} (z) \right] = \sum_{k=1}^{K} \left(f_\eta (k) \nabla_\eta q_\eta (k) + q_\eta (k) \nabla_\eta f_\eta (k)\right)\frac{q_\eta (k)}{q_\eta (k)} \\
= \sum_{k=1}^{K} q_\eta (k) f_\eta (k) \nabla_\eta \log q_\eta (k) + q_\eta (k) \nabla_\eta f_\eta (k) \\
= \mathbb{E}_{z \sim q_{\eta} (z)} \left[ f_\eta (k) \nabla_\eta \log q_\eta (k) + \nabla_\eta f_\eta (k) \right] \\
= \sum_{k=1}^{K} f_\eta (k) \nabla_\eta q_\eta (k) + q_\eta (k) \nabla_\eta f_\eta (k) = \mathbb{E}_{z \sim q_{\eta} (z)} \left[ g(z) \right]
$$
In other words, both can be referred to as estimators $g(z)$.
The authors note that this can be calculated over a subset of the $k$ most probable states (overloading their $k$ from possible values of $z$). Call this set $C_k$:
$$
\nabla_\eta \mathbb{E}_{z \sim q_{\eta} (z)} \left[ f_{\eta} (z) \right] = \mathbb{E}_{z \sim q_{\eta} (z)} \left[ g(z) \right] \\
= \mathbb{E}_{z \sim q_{\eta} (z)} \left[ g(z) \mathbb{1}\{ z \in C_k\} + g(z) \mathbb{1} \{ z \notin C_k \} \right] \\
= \sum_{z \in C_k} q_\eta(z) g(z) + \mathbb{E}_{z \sim q_{\eta} (z)} \left[ g(z) \mathbb{1} \{ z \notin C_k \} \right]
$$
As long as $k$ is small, it's easy to calculate the first term, and if most of the probability mass is contained in that set, then it shouldn't matter how well we approximate the second term.
The authors choose an importance-sampling for the second term, but this is where I get confused. They denote their importance weighting function $q_\eta (z \notin C_k)$ which *could* mean all of the probability mass *not* under the states in $C_k$? Later, they define a decision variable $b$ that expresses whether we are in this set or not, and it's sampled with probability $q_\eta (z \notin C_k)$, so I think my interpretation is correct. The gradient estimator then becomes:
$$
\hat{g} (v) = \sum_{z \in C_k} q_\eta (z) g(z) + q_\eta (z \notin C_k) g(v)\\
v \sim q_\eta | v \notin C_k
$$
[product]: https://en.wikipedia.org/wiki/Product_rule
Showing this is Rao-Blackwellization
----------------------------------------------
Another way to express $z$ would be to sample a Bernoulli r.v. with probability $\sum_{j \notin C_k} q_\eta (j) $, then if it's $1$ sample from $z \in C_k$ and if it's $0$ sample from $z \notin C_k$. As long as those samples are drawn using $q_\eta$ then:
$$
T(u,v,b) \stackrel{d}{=} z \\
T := u^{1-b} v^b
$$
where $u \sim q_\eta | C_k$, $v \sim q_\eta | v \notin C_k$ and $b \sim \text{Bernoulli}(\sum_{j \notin C_k} q_\eta (j))$.
Expressing $z$ in this way means the gradient estimator from before can be written as:
$$
\hat{g} (v) = \mathbb{E} \left[ g( T(u,v,b) ) | v \right]
$$
And they left it as an exercise for the reader to expand that out and show it's the same as equation 6:
$$
\mathbb{E} \left[ g( T(u,v,b) ) | v \right] = \mathbb{E} \left[ g( T(u,v,b)) \mathbb{1} \{ b=0 \} + g( T(u,v,b)) \mathbb{1} \{ b=1 \} \right] \\
= \mathbb{E} \left[ g(z) \mathbb{1} \{ z \in C_k \} + g( z) \mathbb{1} \{ z \notin C_k \} \right] = \mathbb{E} \left[ g(z) \right]
$$
Writing the estimator as a conditional expectation of some statistic of the random variables under the distribution is sufficient to show that this is an instance of Rao-Blackwellization. To be safe, the authors also apply the [conditional variance decomposition][eve] to reinforce the property that RB estimators always have lower variance:
$$
Var(Y) = E\left[ Var (Y|X) \right] + Var(E \left[ Y | X \right] ) \\
Var(g (z) ) = Var (\mathbb{E} \left[ g( T(u,v,b) ) | v \right] ) + E \left[ Var ( g( T(u,v,b) ) | v ) \right] \\
Var (\mathbb{E} \left[ g( T(u,v,b) ) | v \right] ) = Var (\hat{g} (v) ) = Var(g (z) ) - E \left[ Var ( g( T(u,v,b) ) | v ) \right]
$$
They go on to show that the variance is less than or equal to $Var(g(z)) \sum_{j \notin C_k} q_\eta (j)$.
Finally, they note that the variance of a simple estimator can also be reduced by taking multiple samples and averaging. They then provide an equation to calculate the optimal $k$ number of elements of $z$ to evaluate depending on how concentrated the distribution being evaluated is, and a proof showing that this will have a lower variance than the naive estimator.
$$
\hat{k} = \underset{k \in {0, ..., N}}{\operatorname{argmin}} \frac{\sum_{j \notin C_k} q_\eta (j)}{N-k}
$$
I'm not very interested in the experiments right now, but skimming through them it's interesting to see that this method performs very well on a high dimensional hard attention task on MNIST. Particularly because a Gumbel-softmax estimator falls apart in the same experiment. It would be nice to see results on RL problems as were shown in the [RELAX][] paper.
[eve]: https://en.wikipedia.org/wiki/Law_of_total_variance
[relax]: https://arxiv.org/abs/1711.00123
|
MultiPoseNet: Fast Multi-Person Pose Estimation Using Pose Residual Network
Muhammed Kocabas and Salih Karagoz and Emre Akbas
Computer Vision – ECCV 2018 - 2018 via Local CrossRef
Keywords:
Muhammed Kocabas and Salih Karagoz and Emre Akbas
Computer Vision – ECCV 2018 - 2018 via Local CrossRef
Keywords:
|
[link]
The method is a multi-task learning model performing person detection, keypoint detection, person segmentation, and pose estimation. It is a bottom-up approach as it first localizes identity-free semantics and then group them into instances. https://i.imgur.com/kRs9687.png Model structure: - **Backbone**. A feature extractor is presented by ResNet-(50 or 101) with one [Feature Pyramid Network](https://arxiv.org/pdf/1612.03144.pdf) (FPN) for keypoint branch and one for person detection branch. FPN enhances extracted features through multi-level representation. - **Keypoint detection** detects keypoints as well as produces a pixel-level segmentation mask. https://i.imgur.com/XFAi3ga.png FPN features $K_i$ are processed with multiple $3\times3$ convolutions followed by concatenation and final $1\times1$ convolution to obtain predictions for each keypoint, as well as segmentation mask (see Figure for details). This results in #keypoints_in_dataset_per_person + 1 output layers. Additionally, intermediate supervision (i.e. loss) is applied at the FPN outputs. $L_2$ loss between predictions and Gaussian peaks at the keypoint locations is used. Similarly, $L_2$ loss is applied for segmentation predictions and corresponding ground truth masks. - **Person detection** is essentially a [RetinaNet](https://arxiv.org/pdf/1708.02002.pdf), a one-stage object detector, modified to only handle *person* class. - **Pose estimation**. Given initial keypoint predictions, Pose Estimation Network (PRN) selects a single keypoint for each class. https://i.imgur.com/k8wNP5p.png During inference, PRN takes cropped outputs from keypoint detection branch defined by the predicted bounding boxes from the person detection branch, resizes it to a fixed size, and forwards it through a multilayer perceptron with residual connection. During the training, the same process is performed, except the cropped keypoints come from the ground truth annotation defined by a labeled bounding box. This model is not an end-to-end trainable model. While keypoint and person detection branches can, in theory, be trained simultaneously, PRN network requires separate training. **Personal note**. Interestingly, PRN training with ground truth inputs (i.e. "perfect" inputs) only reaches 89.4 mAP validation score which is surprisingly quite far from the max possible score. This presumably means that even if preceding networks or branches perform god-like, the PRN might become a bottleneck in the performance. Therefore, more efforts should be directed to PRN itself. Moreover, modifying the network to support end-to-end training might help in boosting the performance. Open-source implementations used to make sure the paper apprehension is correct: [link1](https://github.com/LiMeng95/MultiPoseNet.pytorch), [link2](https://github.com/IcewineChen/pytorch-MultiPoseNet). |

WAIC, but Why? Generative Ensembles for Robust Anomaly Detection
Hyunsun Choi and Eric Jang and Alexander A. Alemi
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/02 (5 years ago)
Abstract: Machine learning models encounter Out-of-Distribution (OoD) errors when the data seen at test time are generated from a different stochastic generator than the one used to generate the training data. One proposal to scale OoD detection to high-dimensional data is to learn a tractable likelihood approximation of the training distribution, and use it to reject unlikely inputs. However, likelihood models on natural data are themselves susceptible to OoD errors, and even assign large likelihoods to samples from other datasets. To mitigate this problem, we propose Generative Ensembles, which robustify density-based OoD detection by way of estimating epistemic uncertainty of the likelihood model. We present a puzzling observation in need of an explanation -- although likelihood measures cannot account for the typical set of a distribution, and therefore should not be suitable on their own for OoD detection, WAIC performs surprisingly well in practice.
more
less
Hyunsun Choi and Eric Jang and Alexander A. Alemi
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/02 (5 years ago)
Abstract: Machine learning models encounter Out-of-Distribution (OoD) errors when the data seen at test time are generated from a different stochastic generator than the one used to generate the training data. One proposal to scale OoD detection to high-dimensional data is to learn a tractable likelihood approximation of the training distribution, and use it to reject unlikely inputs. However, likelihood models on natural data are themselves susceptible to OoD errors, and even assign large likelihoods to samples from other datasets. To mitigate this problem, we propose Generative Ensembles, which robustify density-based OoD detection by way of estimating epistemic uncertainty of the likelihood model. We present a puzzling observation in need of an explanation -- although likelihood measures cannot account for the typical set of a distribution, and therefore should not be suitable on their own for OoD detection, WAIC performs surprisingly well in practice.
|
[link]
### Summary
Knowing when a model is qualified to make a prediction is critical to safe deployment of ML technology. Model-independent / Unsupervised Out-of-Distribution (OoD) detection is appealing mostly because it doesn't require task-specific labels to train. It is tempting to suggest a simple one-tailed test in which lower likelihoods are OoD (assigned by a Likelihood Model), but the intuition that In-Distribution (ID) inputs should have highest likelihoods _does not hold in higher dimension_. The authors propose to use the Watanabe-Akaike Information Criterion (WAIC) to circumvent this problem and empirically show the robustness of the approach.
### Counterintuitive Properties of Likelihood Models:
https://i.imgur.com/4vo0Ff5.png
So a GLOW model with Gaussian prior maps SVHN closer to the origin than Cifar (but never actually generates SVHN because Gaussian samples are on the shell). This is bad news for OoD detection.
### Proposed Methodology:
Use the WAIC criterion for OoD detection which gives an asymptotically correct estimate of the gap between the training set and test set expectations:
https://i.imgur.com/vasSxuk.png
Basically, the correction term subtracts the variance in likelihoods across independent samples from the posterior. This acts to robustify the estimate, ensuring that points that are sensitive to the particular choice of posterior are penalized. They use an ensemble of generative models as a proxy for posterior samples i.e. the ensembles acts as approximate posterior samples.
Now, OoD can be detected with a Likelihood Model:
https://i.imgur.com/M3CDKOA.png
### Discussion
Interestingly, GLOW maps Cifar and other datasets INSIDE the gaussian shell (which is an annulus of radius $\sqrt{dim} = \sqrt{3072} \approx 55.4$
https://i.imgur.com/ERdgOaz.png
This is in itself quite disturbing, as it suggests that better flow-based generative models (for sampling) can be obtained by encouraging the training distribution to overlap better with the typical set in latent
space.
|

Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Peter Anderson and Xiaodong He and Chris Buehler and Damien Teney and Mark Johnson and Stephen Gould and Lei Zhang
Conference and Computer Vision and Pattern Recognition - 2018 via Local CrossRef
Keywords:
Peter Anderson and Xiaodong He and Chris Buehler and Damien Teney and Mark Johnson and Stephen Gould and Lei Zhang
Conference and Computer Vision and Pattern Recognition - 2018 via Local CrossRef
Keywords:
|
[link]
# Summary This paper presents state-of-the-art methods for both caption generation of images and visual question answering (VQA). The authors build on previous methods by adding what they call a "bottom-up" approach to previous "top-down" attention mechanisms. They show that using their approach they obtain SOTA on both Image captioning (MSCOCO) and the Visual Question and Answering (2017 VQA challenge). They propose a specific network configurations for each. Their biggest contribution is using Faster-R-CNN to retrieve the "important" parts of an image to focus on in both models. ## Top Down Up until this paper, the traditional approach was to use a "top-down" approach, in which the last feature map layer of a CNN is used to obtain a latent representation of the given input image. These features, along with the context of the caption being generated, were used to generate attention weights that were used to predict the next sequence in the context of caption generation. The network would learn to focus its attention on regions of the feature map that matters most. This is the approach used in previous SOTA methods like [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044). ## Bottom-up The authors argue that the feature map of a CNN is too generic and can be thought of operating on a uniform, grid-like feature map. In other words, there is no particular reason to think that the feature map of generated by a CNN would give optimal regions to attend to. Also, carefully choosing the dimensions of the feature map can be very arbitrary. In order to fix this, the authors propose combining object detection methods in a *bottom-up* approach. To do so, the authors propose using Faster-R-CNN to identify regions of interest in an image. Given an input image, Faster-R-CNN will identify bounding boxes of the image that likely correspond to objects of a given category and simultaneously compute a feature vector of that bounding box. Figure 1 shows the difference between the Bottom-up and Top-Down approach.  ## Combining the two In this paper, the authors suggest using the bottom-up approach to compute the salient regions of the image the network should focus on using Faster-R-CNN. FRCNN is carefully pretrained on both imagenet and the Visual Genome dataset. It is then frozen and only used to generate bounding boxes of regions with high confidence of being of interest. The top-down approach is then used on the features obtained from the bottom-up approach. In order to "enhance" the FRCNN performance, they initialize their FRCNN with a ResNet-101 pre-trained on imagenet. They train their FRCNN on the Visual Genome dataset, adding attributes to the loss function that are available from the Visual Genome dataset, attributes such as color (black, white, gold etc.), state (open, close, dark, bright, etc.). A sample of FRCNN outputs are shown in figure 2. It is important to stress that only the feature representations and not the actual outputs (i.e. not the labels) are used in their model.  ## Caption Generation Figure 3 provides a high-level overview of the model being used for caption generation for images. The image is first passed through FRCNN which produces a set of image features *V*. In their specific implementation, *V* consists of *k* vectors of size 1x2048. Their model consists of two LSTM blocks, one for attention and the other for language generation. 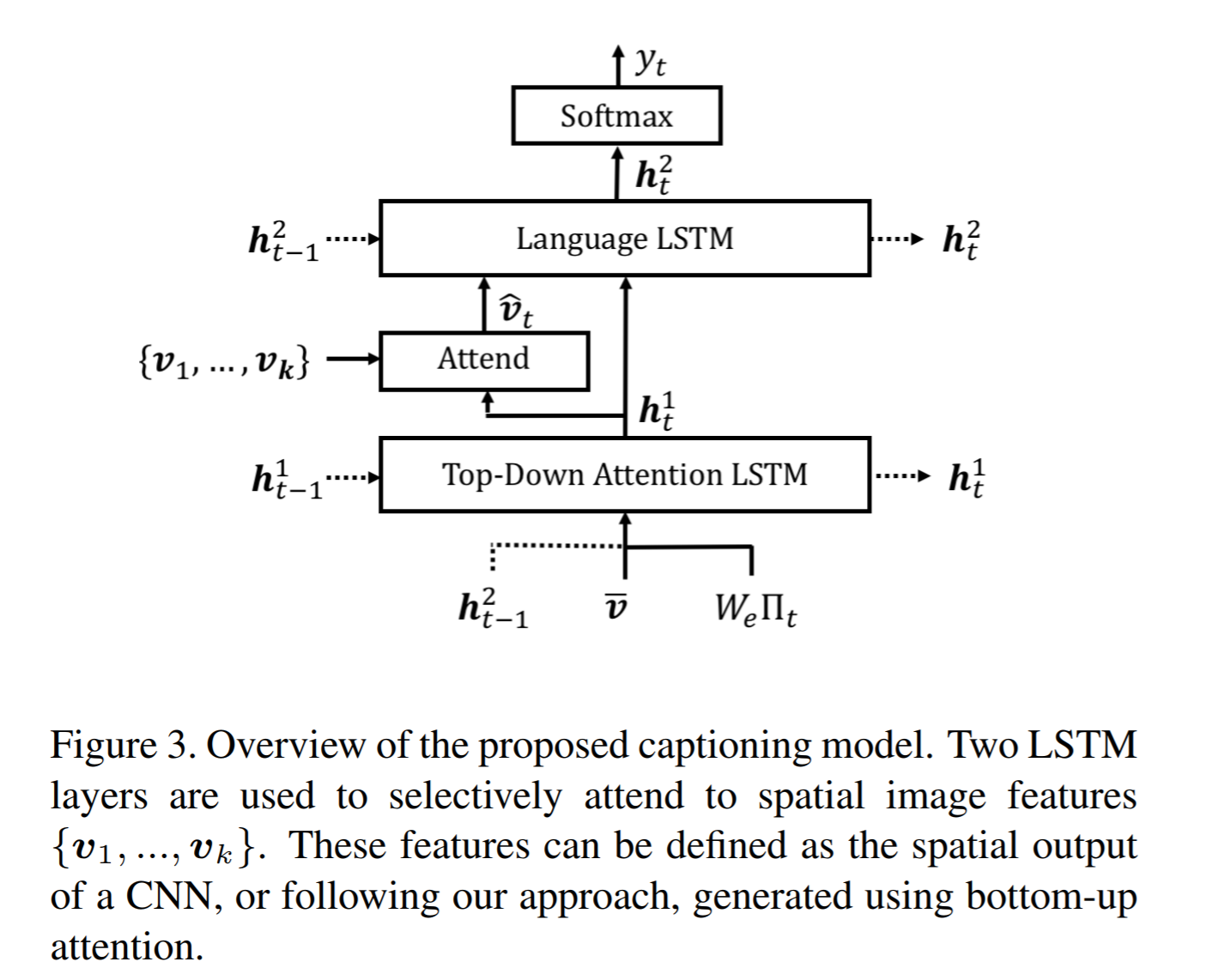 The first block of their model is a Top-Down Attention LSTM layer. It takes as input the mean-pooled features *V* , i.e. 1/k*sum(v_i), concatenated with the previous timestep's hidden representation of the language LSTM as well as the word embedding of the previously generated word. The word embedding is learned and not pretrained. The output of the first LSTM is used to compute the attention for each vector using an MLP and softmax:  The attention weighted image feature is then used as an input to the language LSTM model, concatenated with the output from the top-down Attention LSTM and a softmax is used to predict the next word in the sequence. The loss function seeks to minimize the cross-entropy of the generated sentence. ## VQA Model The VQA task differs to the image generation in that a text-based question accompanies an input image and the network must produce an answer. The VQA model proposed is different to that of the caption generation model previously described, however they both use the same bottom-up approach to generate the feature vectors of the image based on the FRCNN architecture. A high-level overview of the architecture for the VQA model is presented in Figure 4. 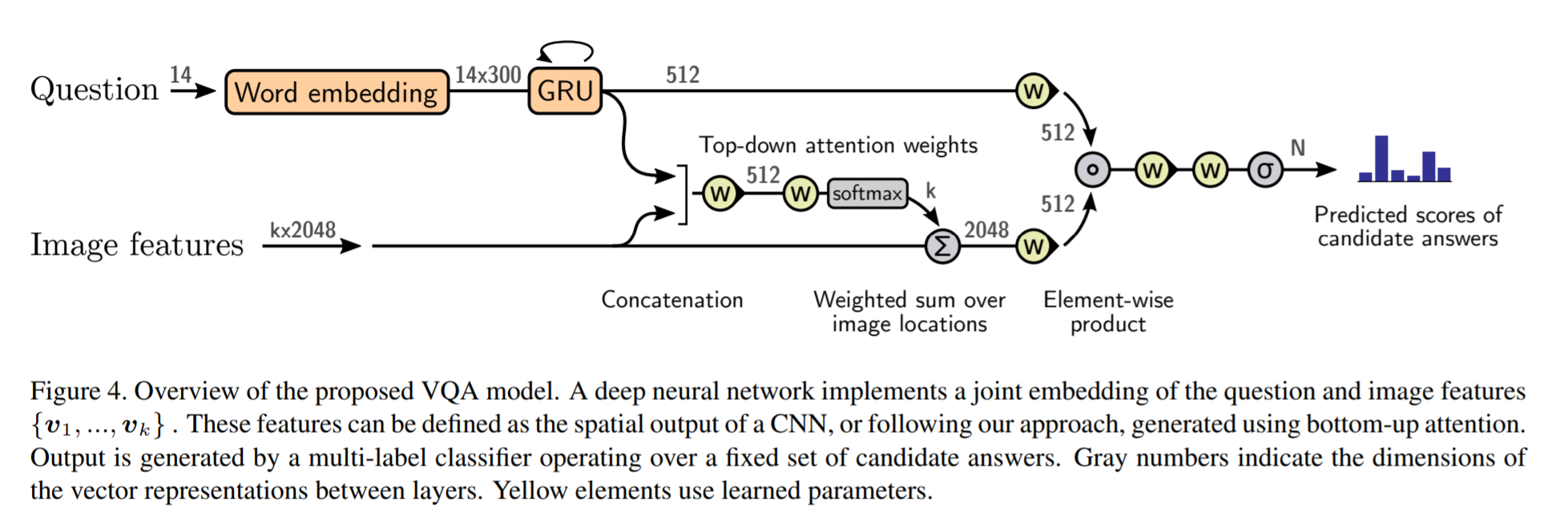 Each word from the question is converted to a learned word embedding which is used as input to a GRU. The number of words for each question is limited to 14 for computational efficiency. The output from the GRU is concatenated with each of the *k* image features, and attention weights are computed for each *k*th feature using an MLP and softmax, similar to what is done in the attention for caption generation. The weighted sum of the feature vectors is then passed through an linear layer such that its shape is compatible with the gru output, and the Hadamard product (element-wise product) is computed over the GRU output and attention-weighted image feature representation. Finally, a tanh non-linear activation is used. This results in a "gated tanh", which have been shown empirically to outperform both ReLU and tanh. Finally, a softmax probability distribution is generated at the output which selects a candidate answer among all possible candidate answers. ## Results and experiments ### Resnet Baseline To demonstrate that their contribution of bottom-up mechanism actually improves on results, the authors use a ResNet trained on imagenet as a baseline for generating the image feature vectors (they resize the final CNN layers using bilinear interpolation when needed). They consistently obtain better results when using the bottom-up approach over the ResNet approach in both caption generation and VQA. ## MSCOCO The authors demonstrate that they outperform all results on all metrics on the MSCOCO test server. 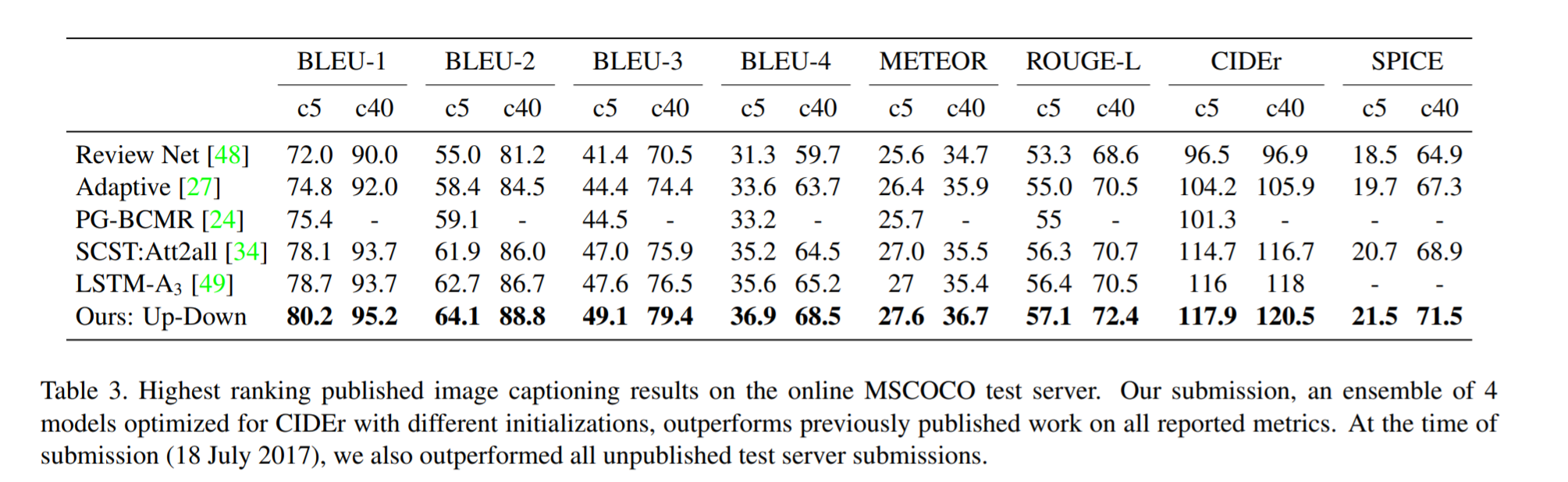 They also show how using the bottom-up approach over ResNet consistently scores them higher on detecting instances of objects, attributes, relations, etc:  The authors, like their predecessors, insist on demonstrating their network's frisbee ability:  ## VQA Results They also demonstrate that the addition of bottom-up attention improves results over a ResNet baseline. 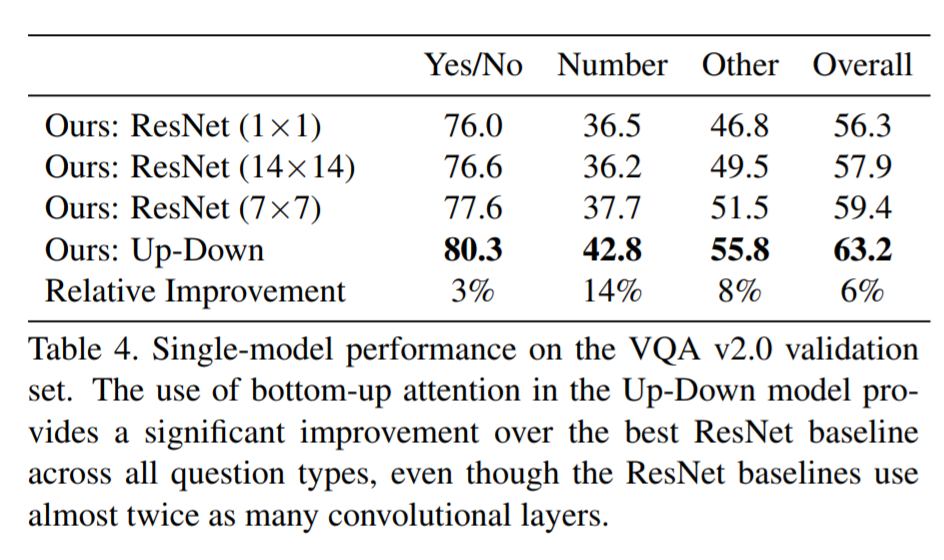 They also show that their model outperformed all other submissions on the VQA submission. They mention using an ensemble of 30 models for their submission.  A sample image of what is attended in an image given a proper answer is shown in figure 6.  # Comments The authors introduce a new way to select portions of the image on which to focus attention. The idea is very original and came at a time when object detection was making significant progress (i.e. FRCNN). A few comments: * This method might not generalize well to other types of data. It requires pre-training on larger datasets (visual genome, imagenet, etc.) which consist of categories that overlap with both the MSCOCO and VQA datasets (i.e. cars, people, etc.). It would be interesting to see an end-to-end model that does not rely on pre-training on other similar datasets. * No insight is given to the computational complexity nor to the inference time or training time. I imagine that FRCNN is resource intensive, and having to do a forward pass of FRCNN for every pass of the network must be a computational bottleneck. Not to mention that they ensembled 30 of them! |

Sanity Checks for Saliency Maps
Adebayo, Julius and Gilmer, Justin and Muelly, Michael and Goodfellow, Ian J. and Hardt, Moritz and Kim, Been
Neural Information Processing Systems Conference - 2018 via Local Bibsonomy
Keywords: dblp
Adebayo, Julius and Gilmer, Justin and Muelly, Michael and Goodfellow, Ian J. and Hardt, Moritz and Kim, Been
Neural Information Processing Systems Conference - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
The paper designs some basic tests to compare saliency methods. It founds that some of the most popular methods are independent of model parameters and the data, meaning they are effectively useless. ## Methods compared The paper compare the following methods: gradient explanation, gradient x input, integrated gradients, guided backprop, guided GradCam and SmoothGrad. They provide a refresher on those methods in the appendix. All those methods can be put in the same framework. They require a classification model and an input (typically an image). The output of the method is an *explanation map* of the shape of the input where a higher value for a feature implies greater relevance in the decision of the model. ## Metrics of comparison The authors argue that visual inspection of the saliency maps can be misleading. They propose to compute the Spearman rank correlation, the structural similarity index (SSMI) and the Pearson correlation of the histogram of gradients. The authors point out that those metrics capture various notions of similarity, but it is an active area of research and those metrics are imperfect. ## First test: model parameters randomization A saliency method must be dependent of model parameters, otherwise it cannot help us understand a model. In this test, the authors randomize the model parameters, layer per layer, starting from the top. Surprisingly, methods such as guided backprop and guided gradcam are completely insensitive to model parameters, as illustrated on this Inception v3 trained on ImageNet:  Integrated gradients looks also dubious as the bird is still visible with a mostly fully randomized model, but the quantitative metrics reveal the difference is actually big between the two models. ## Second test: data randomization It is well-known that randomly shuffling the labels of a dataset does not prevent a neural network from getting a high accuracy on the training set, though it does prevent generalization. The model is able to learn by either memorizing the data or finding spurious patterns. As a result, saliency maps obtained from such a network should have no clearly interpretable signal. Here is the result for a ConvNet trained on MNIST and a shuffled MNIST:  The results are very damning for most methods. Only gradients and GradCam are very different between both models, as confirmed by the low correlation. ## Discussion - Even though some methods do no depend on model parameters and data, they might still depend on the architecture of the models, which could be of some use in some contexts. - Methods that multiply the input with the gradient are dominated by the input. - Complex saliency methods are just fancy edge detectors. - Only gradient, smooth gradient and GradCam survives the sanity checks. # Comments - Why is their GradCam maps so ugly? They don't look like usual GradCam maps at all. - Their tests are simple enough that it's hard to defend a method that doesn't pass them. - The methods that are left are not very good either. They give fuzzy maps that are difficult to interpret. - In the case of integrated gradients (IG), I'm not convinced this is sufficient to discard the method. IG requires a "baseline input" that represents the absence of features. In the case of images, people usually just set the image to 0, which is not at all the absence of a feature. The authors also use the "set the image to 0" strategy, and I'd say their tests are damning for this strategy, not for IG in general. I'd expect an estimation of the baseline such as done in [this paper](https://arxiv.org/abs/1702.04595) would be a fairer evaluation of IG. Code: [GitHub](https://github.com/adebayoj/sanity_checks_saliency) (not available as of 17/07/19) |

Second-Order Adversarial Attack and Certifiable Robustness
Li, Bai and Chen, Changyou and Wang, Wenlin and Carin, Lawrence
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Li, Bai and Chen, Changyou and Wang, Wenlin and Carin, Lawrence
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Li et al. propose an adversarial attack motivated by second-order optimization and uses input randomization as defense. Based on a Taylor expansion, the optimal adversarial perturbation should be aligned with the dominant eigenvector of the Hessian matrix of the loss. As the eigenvectors of the Hessian cannot be computed efficiently, the authors propose an approximation; this is mainly based on evaluating the gradient under Gaussian noise. The gradient is then normalized before taking a projected gradient step. As defense, the authors inject random noise on the input (clean example or adversarial example) and compute the average prediction over multiple iterations. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Certified Robustness to Adversarial Examples with Differential Privacy
Mathias Lecuyer and Vaggelis Atlidakis and Roxana Geambasu and Daniel Hsu and Suman Jana
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.CR, cs.LG
First published: 2018/02/09 (6 years ago)
Abstract: Adversarial examples that fool machine learning models, particularly deep neural networks, have been a topic of intense research interest, with attacks and defenses being developed in a tight back-and-forth. Most past defenses are best effort and have been shown to be vulnerable to sophisticated attacks. Recently a set of certified defenses have been introduced, which provide guarantees of robustness to norm-bounded attacks, but they either do not scale to large datasets or are limited in the types of models they can support. This paper presents the first certified defense that both scales to large networks and datasets (such as Google's Inception network for ImageNet) and applies broadly to arbitrary model types. Our defense, called PixelDP, is based on a novel connection between robustness against adversarial examples and differential privacy, a cryptographically-inspired formalism, that provides a rigorous, generic, and flexible foundation for defense.
more
less
Mathias Lecuyer and Vaggelis Atlidakis and Roxana Geambasu and Daniel Hsu and Suman Jana
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.CR, cs.LG
First published: 2018/02/09 (6 years ago)
Abstract: Adversarial examples that fool machine learning models, particularly deep neural networks, have been a topic of intense research interest, with attacks and defenses being developed in a tight back-and-forth. Most past defenses are best effort and have been shown to be vulnerable to sophisticated attacks. Recently a set of certified defenses have been introduced, which provide guarantees of robustness to norm-bounded attacks, but they either do not scale to large datasets or are limited in the types of models they can support. This paper presents the first certified defense that both scales to large networks and datasets (such as Google's Inception network for ImageNet) and applies broadly to arbitrary model types. Our defense, called PixelDP, is based on a novel connection between robustness against adversarial examples and differential privacy, a cryptographically-inspired formalism, that provides a rigorous, generic, and flexible foundation for defense.
|
[link]
Lecuyer et al. propose a defense against adversarial examples based on differential privacy. Their main insight is that a differential private algorithm is also robust to slight perturbations. In practice, this amounts to injecting noise in some layer (or on the image directly) and using Monte Carlo estimation for computing the expected prediction. The approach is compared to adversarial training against the Carlini+Wagner attack. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models
Sven Gowal and Krishnamurthy Dvijotham and Robert Stanforth and Rudy Bunel and Chongli Qin and Jonathan Uesato and Relja Arandjelovic and Timothy Mann and Pushmeet Kohli
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML
First published: 2018/10/30 (5 years ago)
Abstract: Recent work has shown that it is possible to train deep neural networks that are verifiably robust to norm-bounded adversarial perturbations. Most of these methods are based on minimizing an upper bound on the worst-case loss over all possible adversarial perturbations. While these techniques show promise, they remain hard to scale to larger networks. Through a comprehensive analysis, we show how a careful implementation of a simple bounding technique, interval bound propagation (IBP), can be exploited to train verifiably robust neural networks that beat the state-of-the-art in verified accuracy. While the upper bound computed by IBP can be quite weak for general networks, we demonstrate that an appropriate loss and choice of hyper-parameters allows the network to adapt such that the IBP bound is tight. This results in a fast and stable learning algorithm that outperforms more sophisticated methods and achieves state-of-the-art results on MNIST, CIFAR-10 and SVHN. It also allows us to obtain the first verifiably robust model on a downscaled version of ImageNet.
more
less
Sven Gowal and Krishnamurthy Dvijotham and Robert Stanforth and Rudy Bunel and Chongli Qin and Jonathan Uesato and Relja Arandjelovic and Timothy Mann and Pushmeet Kohli
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML
First published: 2018/10/30 (5 years ago)
Abstract: Recent work has shown that it is possible to train deep neural networks that are verifiably robust to norm-bounded adversarial perturbations. Most of these methods are based on minimizing an upper bound on the worst-case loss over all possible adversarial perturbations. While these techniques show promise, they remain hard to scale to larger networks. Through a comprehensive analysis, we show how a careful implementation of a simple bounding technique, interval bound propagation (IBP), can be exploited to train verifiably robust neural networks that beat the state-of-the-art in verified accuracy. While the upper bound computed by IBP can be quite weak for general networks, we demonstrate that an appropriate loss and choice of hyper-parameters allows the network to adapt such that the IBP bound is tight. This results in a fast and stable learning algorithm that outperforms more sophisticated methods and achieves state-of-the-art results on MNIST, CIFAR-10 and SVHN. It also allows us to obtain the first verifiably robust model on a downscaled version of ImageNet.
|
[link]
Gowal et al. propose interval bound propagation to obtain certified robustness against adversarial examples. In particular, given a neural network consisting of linear layers and monotonic increasing activation functions, a set of allowed perturbations is propagated to obtain upper and lower bounds at each layer. These lead to bounds on the logits of the network; these are used to verify whether the network changes its prediction on the allowed perturbations. Specifically, Gowal et al. consider an $L_\infty$ ball around input examples; the initial bounds are, thus, $\underline{z}_0 = x - \epsilon$ and $\overline{z}_0 = x + \epsilon$. For each layer, the bounds are defined as
$\underline{z}_{k,i} = \min_{\underline{z}_{k – 1} \leq z_{k – 1} \leq \overline{z}_{k-1}} e_i^T h_k(z_{k – 1})$
and the analogous maximization problem for the upper bound; here, $h$ denotes the applied layer. For Linear layers and monotonic activation functions, this is easy to solve, as shown in the paper. Moreover, computing these bounds is very efficient, only needing roughly two times the computation of one forward pass. During training, a combination of a clean loss and adversarial loss is used:
$\kappa l(z_K, y) + (1 - \kappa) l(\hat{z}_K, y)$
where $z_K$ are the logits of the input $x$, and $\hat{z}_K$ are the adversarial logits computed as
$\hat{Z}_{K,y’} = \begin{cases} \overline{z}_{K,y’} & \text{if } y’ \neq y\\\underline{z}_{K,y} & \text{otherwise}\end{cases}$
Both $\epsilon$ and $\kappa$ are annealed during training. In experiments, it is shown that this method results in quite tight bounds on robustness.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Deep-RBF Networks Revisited: Robust Classification with Rejection
Zadeh, Pourya Habib and Hosseini, Reshad and Sra, Suvrit
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Zadeh, Pourya Habib and Hosseini, Reshad and Sra, Suvrit
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Zadeh et al. propose a layer similar to radial basis functions (RBFs) to increase a network’s robustness against adversarial examples by rejection. Based on a deep feature extractor, the RBF units compute
$d_k(x) = \|A_k^Tx + b_k\|_p^p$
with parameters $A$ and $b$. The decision rule remains unchanged, but the output does not resemble probabilities anymore. The full network, i.e., feature extractor and RBF layer, is trained using an adapted loss that resembles a max margin loss:
$J = \sum_i (d_{y_i}(x_i) + \sum_{j \neq y_i} \max(0, \lambda – d_j(x_i)))$
where $(x_i, y_i)$ is a training examples including label. The loss essentially minimizes the output corresponding to the true class while maximizing the output for all other classes up to a specified margin. Additionally, noise examples are injected during training. For these noise examples,
$\sum_j \max(0, \lambda – d_j(x))$
is maximized to enforce that these examples are treated as negatives in a rejection setting where samples not corresponding to the data distribution (or adversarial examples) can be rejected by the model. In experiments, the proposed method seems to be more robust against FGSM and iterative attacks (as evaluated on Foolbox).
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Neural Networks with Structural Resistance to Adversarial Attacks
Luca de Alfaro
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.CR, cs.LG, cs.NE
First published: 2018/09/25 (5 years ago)
Abstract: In adversarial attacks to machine-learning classifiers, small perturbations are added to input that is correctly classified. The perturbations yield adversarial examples, which are virtually indistinguishable from the unperturbed input, and yet are misclassified. In standard neural networks used for deep learning, attackers can craft adversarial examples from most input to cause a misclassification of their choice. We introduce a new type of network units, called RBFI units, whose non-linear structure makes them inherently resistant to adversarial attacks. On permutation-invariant MNIST, in absence of adversarial attacks, networks using RBFI units match the performance of networks using sigmoid units, and are slightly below the accuracy of networks with ReLU units. When subjected to adversarial attacks, networks with RBFI units retain accuracies above 90% for attacks that degrade the accuracy of networks with ReLU or sigmoid units to below 2%. RBFI networks trained with regular input are superior in their resistance to adversarial attacks even to ReLU and sigmoid networks trained with the help of adversarial examples. The non-linear structure of RBFI units makes them difficult to train using standard gradient descent. We show that networks of RBFI units can be efficiently trained to high accuracies using pseudogradients, computed using functions especially crafted to facilitate learning instead of their true derivatives. We show that the use of pseudogradients makes training deep RBFI networks practical, and we compare several structural alternatives of RBFI networks for their accuracy.
more
less
Luca de Alfaro
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.CR, cs.LG, cs.NE
First published: 2018/09/25 (5 years ago)
Abstract: In adversarial attacks to machine-learning classifiers, small perturbations are added to input that is correctly classified. The perturbations yield adversarial examples, which are virtually indistinguishable from the unperturbed input, and yet are misclassified. In standard neural networks used for deep learning, attackers can craft adversarial examples from most input to cause a misclassification of their choice. We introduce a new type of network units, called RBFI units, whose non-linear structure makes them inherently resistant to adversarial attacks. On permutation-invariant MNIST, in absence of adversarial attacks, networks using RBFI units match the performance of networks using sigmoid units, and are slightly below the accuracy of networks with ReLU units. When subjected to adversarial attacks, networks with RBFI units retain accuracies above 90% for attacks that degrade the accuracy of networks with ReLU or sigmoid units to below 2%. RBFI networks trained with regular input are superior in their resistance to adversarial attacks even to ReLU and sigmoid networks trained with the help of adversarial examples. The non-linear structure of RBFI units makes them difficult to train using standard gradient descent. We show that networks of RBFI units can be efficiently trained to high accuracies using pseudogradients, computed using functions especially crafted to facilitate learning instead of their true derivatives. We show that the use of pseudogradients makes training deep RBFI networks practical, and we compare several structural alternatives of RBFI networks for their accuracy.
|
[link]
De Alfaro proposes a deep radial basis function (RBF) network to obtain robustness against adversarial examples. In contrast to “regular” RBF networks, which usually consist of only one hidden layer containing RBF units, de Alfaro proposes to stack multiple layers with RBF units. Specifically, a Gaussian unit utilizing the $L_\infty$ norm is used: $\exp\left( - \max_i(u_i(x_i – w_i))^2\right)$ where $u_i$ and $w_i$ are parameters and $x_i$ are the inputs to the unit – so the network inputs or the outputs of the previous hidden layer. This unit can be understood as computing a soft AND operation; therefore, an alternative OR operation $1 - \exp\left( - \max_i(u_i(x_i – w_i))^2\right)$ is used as well. These two units are used alternatingly in hidden layers in the conducted experiments. Based on these units, de Alfaro argues that the model is less sensitive to adversarial examples, compared to linear operations as commonly used in ReLU networks. For training a deep RBF-network, pseudo gradients are used for both the maximum operation and the exponential function. This is done for simplifying training; I refer to the paper for details. In their experiments, on MNIST, a multi-layer perceptron with the proposed RBF units is used. The network consists of 512 AND units, 512 OR units, 512 AND units and finally 10 OR units. Robustness against FGSM and I-FGSM as well as PGD attacks seems to improve. However, the used PGD attack seems to be weaker than usually, it does not manage to reduce adversarial accuracy of a normal networks to near-zero. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples
Lee, Kimin and Lee, Honglak and Lee, Kibok and Shin, Jinwoo
International Conference on Learning Representations - 2018 via Local Bibsonomy
Keywords: dblp
Lee, Kimin and Lee, Honglak and Lee, Kibok and Shin, Jinwoo
International Conference on Learning Representations - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Lee et al. propose a generative model for obtaining confidence-calibrated classifiers. Neural networks are known to be overconfident in their predictions – not only on examples from the task’s data distribution, but also on other examples taken from different distributions. The authors propose a GAN-based approach to force the classifier to predict uniform predictions on examples not taken from the data distribution. In particular, in addition to the target classifier, a generator and a discriminator are introduced. The generator generates “hard” out-of-distribution examples; ideally these examples are close to the in-distribution, i.e., the data distribution of the actual task. The discriminator is intended to distinguish between out- and in-distribution. The overall algorithm, including the necessary losses, is given in Algorithm 1. In experiments, the approach is shown to allow detecting out-distribution examples nearly perfectly. Examples of the generated “hard” out-of-distribution samples are given in Figure 1. https://i.imgur.com/NmF0fpN.png Algorithm 1: The proposed joint training scheme of out-distribution generator $G$, the in-/out-distribution discriminator $G$ and the original classifier providing $P_\theta$(y|x)$ with parameters $\theta$. https://i.imgur.com/kAclSQz.png Figure 1: A comparison of a regular GAN (a and c) to the proposed framework (c and d). Clearly, the proposed approach generates out-of-distribution samples (i.e., no meaningful digits) close to the original data distribution. |
On the importance of single directions for generalization
Ari S. Morcos and David G. T. Barrett and Neil C. Rabinowitz and Matthew Botvinick
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG, cs.NE
First published: 2018/03/19 (6 years ago)
Abstract: Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network's reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyperparameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.
more
less
Ari S. Morcos and David G. T. Barrett and Neil C. Rabinowitz and Matthew Botvinick
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG, cs.NE
First published: 2018/03/19 (6 years ago)
Abstract: Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network's reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyperparameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.
|
[link]
Morcos et al. study the influence of ablating single units as a proxy to generalization performance. On Cifar10, for example, a 11-layer convolutional network is trained on the clean dataset, as well as on versions of Cifar10 where a fraction of $p$ samples have corrupted labels. In the latter cases, the network is forced to memorize examples, as there is no inherent structure in the labels assignment. Then, it is experimentally shown that these memorizing networks are less robust to setting whole feature maps to zero, i.e., ablating them. This is shown in Figure 1. Based on this result, the authors argue that the area under this ablation curve (AUC) can be used as proxy for generalization performance. For example, early stopping or hyper-parameter selection can be done based on this AUC value. Furthermore, they show that batch normalization discourages networks to rely on these so-called single-directions, i.e., single units or feature maps. Specifically, batch normalization seems to favor units holding information about multiple classes/concepts. https://i.imgur.com/h2JwLUF.png Figure 1: Classification accuracy (y-axis) over the number of units that are ablated (x-axis) for networks trained on Cifar10 with various degrees of corrupted labels. The same experiments (left and right) for MNIST and ImageNet. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Improving Transferability of Adversarial Examples with Input Diversity
Cihang Xie and Zhishuai Zhang and Yuyin Zhou and Song Bai and Jianyu Wang and Zhou Ren and Alan Yuille
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/03/19 (6 years ago)
Abstract: Though CNNs have achieved the state-of-the-art performance on various vision tasks, they are vulnerable to adversarial examples --- crafted by adding human-imperceptible perturbations to clean images. However, most of the existing adversarial attacks only achieve relatively low success rates under the challenging black-box setting, where the attackers have no knowledge of the model structure and parameters. To this end, we propose to improve the transferability of adversarial examples by creating diverse input patterns. Instead of only using the original images to generate adversarial examples, our method applies random transformations to the input images at each iteration. Extensive experiments on ImageNet show that the proposed attack method can generate adversarial examples that transfer much better to different networks than existing baselines. By evaluating our method against top defense solutions and official baselines from NIPS 2017 adversarial competition, the enhanced attack reaches an average success rate of 73.0%, which outperforms the top-1 attack submission in the NIPS competition by a large margin of 6.6%. We hope that our proposed attack strategy can serve as a strong benchmark baseline for evaluating the robustness of networks to adversaries and the effectiveness of different defense methods in the future. Code is available at https://github.com/cihangxie/DI-2-FGSM.
more
less
Cihang Xie and Zhishuai Zhang and Yuyin Zhou and Song Bai and Jianyu Wang and Zhou Ren and Alan Yuille
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/03/19 (6 years ago)
Abstract: Though CNNs have achieved the state-of-the-art performance on various vision tasks, they are vulnerable to adversarial examples --- crafted by adding human-imperceptible perturbations to clean images. However, most of the existing adversarial attacks only achieve relatively low success rates under the challenging black-box setting, where the attackers have no knowledge of the model structure and parameters. To this end, we propose to improve the transferability of adversarial examples by creating diverse input patterns. Instead of only using the original images to generate adversarial examples, our method applies random transformations to the input images at each iteration. Extensive experiments on ImageNet show that the proposed attack method can generate adversarial examples that transfer much better to different networks than existing baselines. By evaluating our method against top defense solutions and official baselines from NIPS 2017 adversarial competition, the enhanced attack reaches an average success rate of 73.0%, which outperforms the top-1 attack submission in the NIPS competition by a large margin of 6.6%. We hope that our proposed attack strategy can serve as a strong benchmark baseline for evaluating the robustness of networks to adversaries and the effectiveness of different defense methods in the future. Code is available at https://github.com/cihangxie/DI-2-FGSM.
|
[link]
Xie et al. propose to improve the transferability of adversarial examples by computing them based on transformed input images. In particular, they adapt I-FGSM such that, in each iteration, the update is computed on a transformed version of the current image with probability $p$. When, at the same time attacking an ensemble of networks, this is shown to improve transferability. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Beyond Pixel Norm-Balls: Parametric Adversaries using an Analytically Differentiable Renderer
Hsueh-Ti Derek Liu and Michael Tao and Chun-Liang Li and Derek Nowrouzezahrai and Alec Jacobson
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, cs.GR, stat.ML
First published: 2018/08/08 (5 years ago)
Abstract: Many machine learning image classifiers are vulnerable to adversarial attacks, inputs with perturbations designed to intentionally trigger misclassification. Current adversarial methods directly alter pixel colors and evaluate against pixel norm-balls: pixel perturbations smaller than a specified magnitude, according to a measurement norm. This evaluation, however, has limited practical utility since perturbations in the pixel space do not correspond to underlying real-world phenomena of image formation that lead to them and has no security motivation attached. Pixels in natural images are measurements of light that has interacted with the geometry of a physical scene. As such, we propose the direct perturbation of physical parameters that underly image formation: lighting and geometry. As such, we propose a novel evaluation measure, parametric norm-balls, by directly perturbing physical parameters that underly image formation. One enabling contribution we present is a physically-based differentiable renderer that allows us to propagate pixel gradients to the parametric space of lighting and geometry. Our approach enables physically-based adversarial attacks, and our differentiable renderer leverages models from the interactive rendering literature to balance the performance and accuracy trade-offs necessary for a memory-efficient and scalable adversarial data augmentation workflow.
more
less
Hsueh-Ti Derek Liu and Michael Tao and Chun-Liang Li and Derek Nowrouzezahrai and Alec Jacobson
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, cs.GR, stat.ML
First published: 2018/08/08 (5 years ago)
Abstract: Many machine learning image classifiers are vulnerable to adversarial attacks, inputs with perturbations designed to intentionally trigger misclassification. Current adversarial methods directly alter pixel colors and evaluate against pixel norm-balls: pixel perturbations smaller than a specified magnitude, according to a measurement norm. This evaluation, however, has limited practical utility since perturbations in the pixel space do not correspond to underlying real-world phenomena of image formation that lead to them and has no security motivation attached. Pixels in natural images are measurements of light that has interacted with the geometry of a physical scene. As such, we propose the direct perturbation of physical parameters that underly image formation: lighting and geometry. As such, we propose a novel evaluation measure, parametric norm-balls, by directly perturbing physical parameters that underly image formation. One enabling contribution we present is a physically-based differentiable renderer that allows us to propagate pixel gradients to the parametric space of lighting and geometry. Our approach enables physically-based adversarial attacks, and our differentiable renderer leverages models from the interactive rendering literature to balance the performance and accuracy trade-offs necessary for a memory-efficient and scalable adversarial data augmentation workflow.
|
[link]
Liu et al. propose adversarial attacks on physical parameters of images, which can be manipulated efficiently through differentiable renderer. In particular, they propose adversarial lighting and adversarial geometry; in both cases, an image is assumed to be a function of lighting and geometry, generated by a differentiable renderer. By directly manipulating these latent variables, more realistic looking adversarial examples can be generated for synthetic images as shown in Figure 1. https://i.imgur.com/uh2pj9w.png Figure 1: Comparison of the proposed attack with known attacks applied to large perturbations, $L_\infty \approx 0.82$. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Breaking Transferability of Adversarial Samples with Randomness
Zhou, Yan and Kantarcioglu, Murat and Xi, Bowei
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Zhou, Yan and Kantarcioglu, Murat and Xi, Bowei
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Zhou et al. study transferability of adversarial examples against ensembles of randomly perturbed networks. Specifically, they consider randomly perturbing the weights using Gaussian additive noise. Using an ensemble of these perturbed networks, the authors show that transferability of adversarial examples decreases significantly. However, the authors do not consider adapting their attack to this defense scenario. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Cost-Sensitive Robustness against Adversarial Examples
Zhang, Xiao and Evans, David
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Zhang, Xiao and Evans, David
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Thang and Evanse propose cost-sensitive certified robustness where different adversarial examples can be weighted based on their actual impact for the application. Specifically, they consider the certified robustness formulation (and the corresponding training scheme) by Wong and Kolter. This formulation is extended by acknowledging that different adversarial examples have different impact for specific applications; this is formulized through a cost matrix which quantifies which source-target label combinations of adversarial examples are actually harmful. Based on this cost matrix, cost-sensitive certified robustness as well as the corresponding training scheme is proposed and evaluated in experiments. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Black-box Adversarial Attacks with Limited Queries and Information
Andrew Ilyas and Logan Engstrom and Anish Athalye and Jessy Lin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.CR, stat.ML
First published: 2018/04/23 (6 years ago)
Abstract: Current neural network-based classifiers are susceptible to adversarial examples even in the black-box setting, where the attacker only has query access to the model. In practice, the threat model for real-world systems is often more restrictive than the typical black-box model where the adversary can observe the full output of the network on arbitrarily many chosen inputs. We define three realistic threat models that more accurately characterize many real-world classifiers: the query-limited setting, the partial-information setting, and the label-only setting. We develop new attacks that fool classifiers under these more restrictive threat models, where previous methods would be impractical or ineffective. We demonstrate that our methods are effective against an ImageNet classifier under our proposed threat models. We also demonstrate a targeted black-box attack against a commercial classifier, overcoming the challenges of limited query access, partial information, and other practical issues to break the Google Cloud Vision API.
more
less
Andrew Ilyas and Logan Engstrom and Anish Athalye and Jessy Lin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.CR, stat.ML
First published: 2018/04/23 (6 years ago)
Abstract: Current neural network-based classifiers are susceptible to adversarial examples even in the black-box setting, where the attacker only has query access to the model. In practice, the threat model for real-world systems is often more restrictive than the typical black-box model where the adversary can observe the full output of the network on arbitrarily many chosen inputs. We define three realistic threat models that more accurately characterize many real-world classifiers: the query-limited setting, the partial-information setting, and the label-only setting. We develop new attacks that fool classifiers under these more restrictive threat models, where previous methods would be impractical or ineffective. We demonstrate that our methods are effective against an ImageNet classifier under our proposed threat models. We also demonstrate a targeted black-box attack against a commercial classifier, overcoming the challenges of limited query access, partial information, and other practical issues to break the Google Cloud Vision API.
|
[link]
Ilyas et al. propose three query-efficient black-box adversarial example attacks using distribution-based gradient estimation. In particular, their simplest attacks involves estimating the gradient locally using a search distribution:
$ \nabla_x \mathbb{E}_{\pi(\theta|x)} [F(\theta)] = \mathbb{E}_{\pi(\theta|x)} [F(\theta) \nabla_x \log(\pi(\theta|x))]$
where $F(\cdot)$ is a loss function – e.g., using the cross-entropy loss which is maximized to obtain an adversarial example. The above equation, using a Gaussian noise search distribution leads to a simple approximator for the gradient:
$\nabla \mathbb{E}[F(\theta)] = \frac{1}{\sigma n} \sum_{i = 1}^n \delta_i F(\theta + \sigma \delta_i)$
where $\sigma$ is the search variance and $\delta_i$ are sampled from a unit Gaussian. This scheme can then be applied as part of the projected gradient descent white-box attacks to obtain adversarial examples.
The above attack assumes that the black-box network provides probability outputs in order to compute the loss $F$. In the remainder of the paper, the authors also generalize this approach to the label-only case, where the network only provides the top $k$ labels for each input. In experiments, the attacks is shown to be effective while rarely requiring more than $50$k queries on ImageNet.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
On the Intriguing Connections of Regularization, Input Gradients and Transferability of Evasion and Poisoning Attacks
Ambra Demontis and Marco Melis and Maura Pintor and Matthew Jagielski and Battista Biggio and Alina Oprea and Cristina Nita-Rotaru and Fabio Roli
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML, 68T10, 68T45
First published: 2018/09/08 (5 years ago)
Abstract: Transferability captures the ability of an attack against a machine-learning model to be effective against a different, potentially unknown, model. Studying transferability of attacks has gained interest in the last years due to the deployment of cyber-attack detection services based on machine learning. For these applications of machine learning, service providers avoid disclosing information about their machine-learning algorithms. As a result, attackers trying to bypass detection are forced to craft their attacks against a surrogate model instead of the actual target model used by the service. While previous work has shown that finding test-time transferable attack samples is possible, it is not well understood how an attacker may construct adversarial examples that are likely to transfer against different models, in particular in the case of training-time poisoning attacks. In this paper, we present the first empirical analysis aimed to investigate the transferability of both test-time evasion and training-time poisoning attacks. We provide a unifying, formal definition of transferability of such attacks and show how it relates to the input gradients of the surrogate and of the target classification models. We assess to which extent some of the most well-known machine-learning systems are vulnerable to transfer attacks, and explain why such attacks succeed (or not) across different models. To this end, we leverage some interesting connections highlighted in this work among the adversarial vulnerability of machine-learning models, their regularization hyperparameters and input gradients.
more
less
Ambra Demontis and Marco Melis and Maura Pintor and Matthew Jagielski and Battista Biggio and Alina Oprea and Cristina Nita-Rotaru and Fabio Roli
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML, 68T10, 68T45
First published: 2018/09/08 (5 years ago)
Abstract: Transferability captures the ability of an attack against a machine-learning model to be effective against a different, potentially unknown, model. Studying transferability of attacks has gained interest in the last years due to the deployment of cyber-attack detection services based on machine learning. For these applications of machine learning, service providers avoid disclosing information about their machine-learning algorithms. As a result, attackers trying to bypass detection are forced to craft their attacks against a surrogate model instead of the actual target model used by the service. While previous work has shown that finding test-time transferable attack samples is possible, it is not well understood how an attacker may construct adversarial examples that are likely to transfer against different models, in particular in the case of training-time poisoning attacks. In this paper, we present the first empirical analysis aimed to investigate the transferability of both test-time evasion and training-time poisoning attacks. We provide a unifying, formal definition of transferability of such attacks and show how it relates to the input gradients of the surrogate and of the target classification models. We assess to which extent some of the most well-known machine-learning systems are vulnerable to transfer attacks, and explain why such attacks succeed (or not) across different models. To this end, we leverage some interesting connections highlighted in this work among the adversarial vulnerability of machine-learning models, their regularization hyperparameters and input gradients.
|
[link]
Demontis et al. study transferability of adversarial examples and data poisening attacks in the light of the targeted models gradients. In particular, they experimentally validate the following hypotheses: First, susceptibility to these attacks depends on the size of the model’s gradients; the higher the gradient, the smaller is the perturbation needed to increase the loss. Second, the size of the gradient depends on regularization. And third, the cosine between the target model’s gradients and the surrogate model’s gradients (trained to compute transferable attacks) influences vulnerability. These insights hold for both evasion and poisening attacks and are motivated by a simple linear Taylor expansion of the target model’s loss. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Dropout for Supervised and Semi-Supervised Learning
Park, Sungrae and Park, Jun-Keon and Shin, Su-Jin and Moon, Il-Chul
AAAI Conference on Artificial Intelligence - 2018 via Local Bibsonomy
Keywords: dblp
Park, Sungrae and Park, Jun-Keon and Shin, Su-Jin and Moon, Il-Chul
AAAI Conference on Artificial Intelligence - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Park et al. introduce adversarial dropout, a variant of adversarial training based on adversarially computing dropout masks. Specifically, instead of training on adversarial examples, the authors propose an efficient method to compute adversarial dropout masks during training. In experiments, this approach seems to improve generalization performance in semi-supervised settings. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks
Liu, Kang and Dolan-Gavitt, Brendan and Garg, Siddharth
Springer RAID - 2018 via Local Bibsonomy
Keywords: dblp
Liu, Kang and Dolan-Gavitt, Brendan and Garg, Siddharth
Springer RAID - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Liu et al. propose fine-pruning, a combination of weight pruning and fine-tuning to defend against backdoor attacks on neural networks. Specifically, they consider a setting where training is outsourced to a machine learning service; the attacker has access to the network and training set, however, any change in network architecture would be easily detected. Thus, the attacker tries to inject backdoors through data poisening. As defense against such attacks, the authors propose to identify and prune weights that are not used for the actual tasks but only for the backdoor inputs. This defense can then be combined with fine-tuning and, as shown in experiments, is able to make backdoor attacks less effective – even when considering an attacker aware of this defense. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
On the Geometry of Adversarial Examples
Khoury, Marc and Hadfield-Menell, Dylan
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Khoury, Marc and Hadfield-Menell, Dylan
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Khoury and Hadfield-Menell provide two important theoretical insights regarding adversarial robustness: it is impossible to be robust in terms of all norms, and adversarial training is sample inefficient. Specifically, they study robustness in relation to the problem’s codimension, i.e., the difference between the dimensionality of the embedding space (e.g., image space) and the dimensionality of the manifold (where the data is assumed to actually live on). Then, adversarial training is shown to be sample inefficient in high codimensions. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
The Limitations of Model Uncertainty in Adversarial Settings
Grosse, Kathrin and Pfaff, David and Smith, Michael T. and Backes, Michael
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Grosse, Kathrin and Pfaff, David and Smith, Michael T. and Backes, Michael
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Grosse et al. show that Gaussian Processes allow to reject some adversarial examples based on their confidence and uncertainty; however, attacks maximizing confidence and minimizing uncertainty are still successful. While some state-of-the-art adversarial examples seem to result in significantly different confidence and uncertainty estimates compared to benign examples, Gaussian Processes can still be fooled through particularly crafted adversarial examples. To this end, the confidence is explicitly maximized and, additionally, the uncertainty is constrained to not be larger than the uncertainty of the corresponding benign test example. In experiments, this attack is shown to successfully fool Gaussian Processes while resulting in imperceptible perturbations. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
The Secret Sharer: Measuring Unintended Neural Network Memorization & Extracting Secrets
Carlini, Nicholas and Liu, Chang and Kos, Jernej and Erlingsson, Úlfar and Song, Dawn
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Carlini, Nicholas and Liu, Chang and Kos, Jernej and Erlingsson, Úlfar and Song, Dawn
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Carlini et al. propose several attacks to extract secrets form trained black-box models. Additionally, they show that state-of-the-art neural networks memorize secrets early during training. Particularly on the Penn treebank, after inserting a secret of specific format, the authors validate that the secret can be identified based on the models output probabilities (i.e., black-box access). Several metrics based on the log-perplexity of the secret show that secrets are memorized early during training and memorization happens for all popular architectures and training strategies; additionally, memorization also works for multiple secrets. Furthermore, the authors propose several attacks to extract secrets, most notably through shortest path search. Here, starting with an empty secret, the characters of the secret are identified sequentially in order to minimize log-perplexity. Using this attack, secrets such as credit card numbers are extractable from popular mail datasets. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Playing the Game of Universal Adversarial Perturbations
Julien Perolat and Mateusz Malinowski and Bilal Piot and Olivier Pietquin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, stat.ML
First published: 2018/09/20 (5 years ago)
Abstract: We study the problem of learning classifiers robust to universal adversarial perturbations. While prior work approaches this problem via robust optimization, adversarial training, or input transformation, we instead phrase it as a two-player zero-sum game. In this new formulation, both players simultaneously play the same game, where one player chooses a classifier that minimizes a classification loss whilst the other player creates an adversarial perturbation that increases the same loss when applied to every sample in the training set. By observing that performing a classification (respectively creating adversarial samples) is the best response to the other player, we propose a novel extension of a game-theoretic algorithm, namely fictitious play, to the domain of training robust classifiers. Finally, we empirically show the robustness and versatility of our approach in two defence scenarios where universal attacks are performed on several image classification datasets -- CIFAR10, CIFAR100 and ImageNet.
more
less
Julien Perolat and Mateusz Malinowski and Bilal Piot and Olivier Pietquin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, stat.ML
First published: 2018/09/20 (5 years ago)
Abstract: We study the problem of learning classifiers robust to universal adversarial perturbations. While prior work approaches this problem via robust optimization, adversarial training, or input transformation, we instead phrase it as a two-player zero-sum game. In this new formulation, both players simultaneously play the same game, where one player chooses a classifier that minimizes a classification loss whilst the other player creates an adversarial perturbation that increases the same loss when applied to every sample in the training set. By observing that performing a classification (respectively creating adversarial samples) is the best response to the other player, we propose a novel extension of a game-theoretic algorithm, namely fictitious play, to the domain of training robust classifiers. Finally, we empirically show the robustness and versatility of our approach in two defence scenarios where universal attacks are performed on several image classification datasets -- CIFAR10, CIFAR100 and ImageNet.
|
[link]
Pérolat et al. propose a game-theoretic variant of adversarial training on universal adversarial perturbations. In particular, in each training iteration, the model is trained for a specific number of iterations on the current training set. Afterwards, a universal perturbation is found (and the corresponding test images) that fools the network. The found adversarial examples are added to the training set. In the next iteration, the network is trained on the new training set which includes adversarial examples. Overall, this leads to a network being trained on a sequence of universal adversarial perturbations corresponding to earlier versions of that network. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Are adversarial examples inevitable?
Shafahi, Ali and Huang, W. Ronny and Studer, Christoph and Feizi, Soheil and Goldstein, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Shafahi, Ali and Huang, W. Ronny and Studer, Christoph and Feizi, Soheil and Goldstein, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Shafahi et al. discuss fundamental limits of adversarial robustness, showing that adversarial examples are – to some extent – inevitable. Specifically, for the unit sphere, the unit cube as well as for different attacks (e.g., sparse attacks and dense attacks), the authors show that adversarial examples likely exist. The provided theoretical arguments also provide some insights on which problems are more (or less) robust. For example, more concentrated class distributions seem to be more robust by construction. Overall, these insights lead the authors to several interesting conclusions: First, the results are likely to extent to datasets which actually live on low-dimensional manifolds of the unit sphere/cube. Second, it needs to be differentiated between the existence adversarial examples and our ability to compute them efficiently. Making it harder to compute adversarial examples might, thus, be a valid defense mechanism. And third, the results suggest that lower-dimensional data might be less susceptible to adversarial examples. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Universal Adversarial Training
Shafahi, Ali and Najibi, Mahyar and Xu, Zheng and Dickerson, John P. and Davis, Larry S. and Goldstein, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Shafahi, Ali and Najibi, Mahyar and Xu, Zheng and Dickerson, John P. and Davis, Larry S. and Goldstein, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Shafahi et al. propose universal adversarial training, meaning training on universal adversarial examples. In contrast to regular adversarial examples, universal ones represent perturbations that cause a network to mis-classify many test images. In contrast to regular adversarial training, where several additional iterations are required on each batch of images, universal adversarial training only needs one additional forward/backward pass on each batch. The obtained perturbations for each batch are accumulated in a universal adversarial examples. This makes adversarial training more efficient, however reduces robustness significantly. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Fortified Networks: Improving the Robustness of Deep Networks by Modeling the Manifold of Hidden Representations
Lamb, Alex and Binas, Jonathan and Goyal, Anirudh and Serdyuk, Dmitriy and Subramanian, Sandeep and Mitliagkas, Ioannis and Bengio, Yoshua
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Lamb, Alex and Binas, Jonathan and Goyal, Anirudh and Serdyuk, Dmitriy and Subramanian, Sandeep and Mitliagkas, Ioannis and Bengio, Yoshua
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Lamb et al. introduce fortified networks with denoising auto encoders as hidden layers. These denoising auto encoders are meant to learn the manifold of hidden representations, project adversarial input back to the manifold and improve robustness. The main idea is illustrated in Figure 1. The denoising auto encoders can be added at any layer and are trained jointly with the classification network – either on the original input, or on adversarial examples as done in adversarial training. https://i.imgur.com/5vaZrVk.png Figure 1: Illustration of a fortified layer, i.e., a hidden layer that is reconstructed through a denoising auto encoder as defense mechanism. The denoising auto encoders are trained jointly with the network. In experiments, they show that the proposed defense mechanism improves robustness on MNIST and CIFAR, compared to adversarial training and other baselines. The improvements are, however, very marginal. Especially, as the proposed method imposes an additional overhead (in addition to adversarial training). Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Towards the first adversarially robust neural network model on MNIST
Lukas Schott and Jonas Rauber and Matthias Bethge and Wieland Brendel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/05/23 (6 years ago)
Abstract: Despite much effort, deep neural networks remain highly susceptible to tiny input perturbations and even for MNIST, one of the most common toy datasets in computer vision, no neural network model exists for which adversarial perturbations are large and make semantic sense to humans. We show that even the widely recognized and by far most successful defense by Madry et al. (1) overfits on the L-infinity metric (it's highly susceptible to L2 and L0 perturbations), (2) classifies unrecognizable images with high certainty, (3) performs not much better than simple input binarization and (4) features adversarial perturbations that make little sense to humans. These results suggest that MNIST is far from being solved in terms of adversarial robustness. We present a novel robust classification model that performs analysis by synthesis using learned class-conditional data distributions. We derive bounds on the robustness and go to great length to empirically evaluate our model using maximally effective adversarial attacks by (a) applying decision-based, score-based, gradient-based and transfer-based attacks for several different Lp norms, (b) by designing a new attack that exploits the structure of our defended model and (c) by devising a novel decision-based attack that seeks to minimize the number of perturbed pixels (L0). The results suggest that our approach yields state-of-the-art robustness on MNIST against L0, L2 and L-infinity perturbations and we demonstrate that most adversarial examples are strongly perturbed towards the perceptual boundary between the original and the adversarial class.
more
less
Lukas Schott and Jonas Rauber and Matthias Bethge and Wieland Brendel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/05/23 (6 years ago)
Abstract: Despite much effort, deep neural networks remain highly susceptible to tiny input perturbations and even for MNIST, one of the most common toy datasets in computer vision, no neural network model exists for which adversarial perturbations are large and make semantic sense to humans. We show that even the widely recognized and by far most successful defense by Madry et al. (1) overfits on the L-infinity metric (it's highly susceptible to L2 and L0 perturbations), (2) classifies unrecognizable images with high certainty, (3) performs not much better than simple input binarization and (4) features adversarial perturbations that make little sense to humans. These results suggest that MNIST is far from being solved in terms of adversarial robustness. We present a novel robust classification model that performs analysis by synthesis using learned class-conditional data distributions. We derive bounds on the robustness and go to great length to empirically evaluate our model using maximally effective adversarial attacks by (a) applying decision-based, score-based, gradient-based and transfer-based attacks for several different Lp norms, (b) by designing a new attack that exploits the structure of our defended model and (c) by devising a novel decision-based attack that seeks to minimize the number of perturbed pixels (L0). The results suggest that our approach yields state-of-the-art robustness on MNIST against L0, L2 and L-infinity perturbations and we demonstrate that most adversarial examples are strongly perturbed towards the perceptual boundary between the original and the adversarial class.
|
[link]
Schott et al. propose an analysis-by-synthetis approach for adversarially robust MNIST classification. In particular, as illustrated in Figure 1, class-conditional variational auto-encoders (i.e., one variational auto-encoder per class) are learned. The respective recognition models, i.e., encoders, are discarded. For classification, the optimization problem
$l_y^*(x) = \max_z \log p(x|z) - \text{KL}(\mathcal{N}(z, \sigma I)|\mathcal{N}(0,1))$
is solved for each class $z$. Here, $p(x|z)$ represents the learned generative model. The optimization problem leads a latent code $z$ corresponding to the best reconstruction of the input. The corresponding likelihood can be used for classificaiton using Bayes’ theorem. The obtained posteriors $p(y|x)$ are then scaled using a modified softmax (see paper) to obtain the final decision. (Additionally, input binarization is used as defense.)
https://i.imgur.com/ignvoHQ.png
Figure 1: The proposed analysis by synthesis approach to MNIST classification. The depicted generators are taken from class-specific variational auto-encoders.
In addition to the proposed defense, Schott et al. also derive lower and upper bounds on the robustness of the classification procedure. These bounds can be derived from the optimization problem above, see the paper for details.
In experiments, they show that their defense outperforms state-of-the-art adversarial training and allows to estimate tight bounds. In addition, the method is robust against distal adversarial examples and the adversarial examples look more meaningful, see Figure 2.
https://i.imgur.com/uxGzzg1.png
Figure 2: Adversarial examples for the proposed “ABS” method, its binary variant and related work.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Generating Natural Adversarial Examples
Zhao, Zhengli and Dua, Dheeru and Singh, Sameer
International Conference on Learning Representations - 2018 via Local Bibsonomy
Keywords: dblp
Zhao, Zhengli and Dua, Dheeru and Singh, Sameer
International Conference on Learning Representations - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Zhao et al. propose a generative adversarial network (GAN) based approach to generate meaningful and natural adversarial examples for images and text. With natural adversarial examples, the authors refer to meaningful changes in the image content instead of adding seemingly random/adversarial noise – as illustrated in Figure 1. These natural adversarial examples can be crafted by first learning a generative model of the data, e.g., using a GAN together with an inverter (similar to an encoder), see Figure 2. Then, given an image $x$ and its latent code $z$, adversarial examples $\tilde{z} = z + \delta$ can be found within the latent code. The hope is that these adversarial examples will correspond to meaningful, naturally looking adversarial examples in the image space.
https://i.imgur.com/XBhHJuY.png
Figure 1: Illustration of natural adversarial examples in comparison ot regular, FGSM adversarial examples.
https://i.imgur.com/HT2StGI.png
Figure 2: Generative model (GAN) together with the required inverter.
In practice, e.g., on MNIST, any black-box classifier can be attacked by randomly sampling possible perturbations $\delta$ in the random space (with increasing norm) until an adversarial perturbation is found. Here, the inverted from Figure 2 is trained on top of the critic of the GAN (although specific details are missing in the paper).
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Adversarial Training Versus Weight Decay
Angus Galloway and Thomas Tanay and Graham W. Taylor
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/04/10 (6 years ago)
Abstract: Performance-critical machine learning models should be robust to input perturbations not seen during training. Adversarial training is a method for improving a model's robustness to some perturbations by including them in the training process, but this tends to exacerbate other vulnerabilities of the model. The adversarial training framework has the effect of translating the data with respect to the cost function, while weight decay has a scaling effect. Although weight decay could be considered a crude regularization technique, it appears superior to adversarial training as it remains stable over a broader range of regimes and reduces all generalization errors. Equipped with these abstractions, we provide key baseline results and methodology for characterizing robustness. The two approaches can be combined to yield one small model that demonstrates good robustness to several white-box attacks associated with different metrics.
more
less
Angus Galloway and Thomas Tanay and Graham W. Taylor
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/04/10 (6 years ago)
Abstract: Performance-critical machine learning models should be robust to input perturbations not seen during training. Adversarial training is a method for improving a model's robustness to some perturbations by including them in the training process, but this tends to exacerbate other vulnerabilities of the model. The adversarial training framework has the effect of translating the data with respect to the cost function, while weight decay has a scaling effect. Although weight decay could be considered a crude regularization technique, it appears superior to adversarial training as it remains stable over a broader range of regimes and reduces all generalization errors. Equipped with these abstractions, we provide key baseline results and methodology for characterizing robustness. The two approaches can be combined to yield one small model that demonstrates good robustness to several white-box attacks associated with different metrics.
|
[link]
Galloway et al. provide a theoretical and experimental discussion of adversarial training and weight decay with respect to robustness as well as generalization. In the following I want to try and highlight the most important findings based on their discussion of linear logistic regression. Considering the softplus loss $\mathcal{L}(z) = \log(1 + e^{-z})$, the learning problem takes the form:
$\min_w \mathbb{E}_{x,y \sim p_{data}} [\mathcal{L}(y(w^Tx + b)]$
where $y \in \{-1,1\}$. This optimization problem is also illustrated in Figure 1 (top). Now considering $L_2$ weight decay can also be seen to be equivalent to scaling the softplus loss. In particular, Galloway et al. Argue that $w^Tx + b = \|w\|_2 d(x)$ where $d(x)$ is the (signed) Euclidean distance to the decision boundary. (This follows directly from the fact that $d(x) = \frac{w^Tx +b}{\|w\|w_2}$.) Then, the problem can be rewritten as
$\min_w \mathbb{E}_{x,y \sim p_{data}} [\mathcal{L}(yd(x) \|w\|_2)]$
This can be understood as a scaled version of the softplus loss; adding a $L_2$ weight decay term basically controls the level of scaling. This is illustrated in Figure 1 (middle) for different levels of scaling. Finally, adversarial training means training on the worst-case example for a given $\epsilon$. In practice, for the linear logistic regression model, this results in training on $x - \epsilon y \frac{w}{\|w\|_2}$ - which can easily be understood when considering that the attacker can cause the most disturbance when changing the samples in the direction of $-w$ for label $1$. Then,
$y (w^T(x - \epsilon y \frac{w}{\|w\|_2}) + b) = y(w^Tx + b) - \epsilon \|w\|_2 = \|w\|_2 (yd(x) - \epsilon)$,
which results in a shift of the data by $\epsilon$ - as illustrated in Figure 1 (bottom). Overall, show that weight decay acts as scaling the objective and adversarial training acts as shifting the data (or equivalently the objective).
In the non-linear case, decaying weights is argued to be equivalent to decaying the logits. Effectively, this results in a temperature parameter for the softmax function resulting in smoother probability distributions. Similarly, adversarial training (in a first-order approximation) can be understood as effectively reducing the probability attributed to the correct class. Here, again, weight decay results in a scaling effect and adversarial training in a shifting effect. In conclusion, adversarial training is argued to be only effective with small perturbation sizes (i.e., if the shift is not too large), weil weight decay is also beneficial for generalization. However, from reading the paper, it is unclear what the actual recommendation on both methods is.
In the experimental section, the authors focus on two models, a wide residual network and a very constrained 4-layer convolutional neural network. Here, their discussion shifts slightly to the complexity of the employed model. While not stated very explicitly, one of the take-aways is that the simpler model might be more robust, especially for fooling images.
https://i.imgur.com/FKT3a2O.png
https://i.imgur.com/wWwFKqn.png
https://i.imgur.com/oaTfqHJ.png
Figure 1: Illustration of the linear logistic regression argument. Top: illustration of linear logistic regression where $\xi$ is the loss $\mathcal{L}$, middle: illustration of the impact of weight decay/scaling, bottom: illustration of the impact of shift for adversarial training.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Unsupervised Learning via Meta-Learning
Kyle Hsu and Sergey Levine and Chelsea Finn
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, stat.ML
First published: 2018/10/04 (5 years ago)
Abstract: A central goal of unsupervised learning is to acquire representations from unlabeled data or experience that can be used for more effective learning of downstream tasks from modest amounts of labeled data. Many prior unsupervised learning works aim to do so by developing proxy objectives based on reconstruction, disentanglement, prediction, and other metrics. Instead, we develop an unsupervised learning method that explicitly optimizes for the ability to learn a variety of tasks from small amounts of data. To do so, we construct tasks from unlabeled data in an automatic way and run meta-learning over the constructed tasks. Surprisingly, we find that, when integrated with meta-learning, relatively simple mechanisms for task design, such as clustering unsupervised representations, lead to good performance on a variety of downstream tasks. Our experiments across four image datasets indicate that our unsupervised meta-learning approach acquires a learning algorithm without any labeled data that is applicable to a wide range of downstream classification tasks, improving upon the representation learned by four prior unsupervised learning methods.
more
less
Kyle Hsu and Sergey Levine and Chelsea Finn
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, stat.ML
First published: 2018/10/04 (5 years ago)
Abstract: A central goal of unsupervised learning is to acquire representations from unlabeled data or experience that can be used for more effective learning of downstream tasks from modest amounts of labeled data. Many prior unsupervised learning works aim to do so by developing proxy objectives based on reconstruction, disentanglement, prediction, and other metrics. Instead, we develop an unsupervised learning method that explicitly optimizes for the ability to learn a variety of tasks from small amounts of data. To do so, we construct tasks from unlabeled data in an automatic way and run meta-learning over the constructed tasks. Surprisingly, we find that, when integrated with meta-learning, relatively simple mechanisms for task design, such as clustering unsupervised representations, lead to good performance on a variety of downstream tasks. Our experiments across four image datasets indicate that our unsupervised meta-learning approach acquires a learning algorithm without any labeled data that is applicable to a wide range of downstream classification tasks, improving upon the representation learned by four prior unsupervised learning methods.
|
[link]
What is stopping us from applying meta-learning to new tasks? Where do the tasks come from? Designing task distribution is laborious. We should automatically learn tasks! Unsupervised Learning via Meta-Learning: The idea is to use a distance metric in an out-of-the-box unsupervised embedding space created by BiGAN/ALI or DeepCluster to construct tasks in an unsupervised way. If you cluster points to randomly define classes (e.g. random k-means) you can then sample tasks of 2 or 3 classes and use them to train a model. Where does the extra information come from? The metric space used for k-means asserts specific distances. The intuition why this works is that it is useful model initialization for downstream tasks. This summary was written with the help of Chelsea Finn. |

Model-Based Reinforcement Learning via Meta-Policy Optimization
Clavera, Ignasi and Rothfuss, Jonas and Schulman, John and Fujita, Yasuhiro and Asfour, Tamim and Abbeel, Pieter
Conference on Robot Learning - 2018 via Local Bibsonomy
Keywords: dblp
Clavera, Ignasi and Rothfuss, Jonas and Schulman, John and Fujita, Yasuhiro and Asfour, Tamim and Abbeel, Pieter
Conference on Robot Learning - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
In terms of model based RL, learning dynamics models is imperfect, which often leads to the learned policy overfitting to the learned dynamics model, doing well in the learned simulator but not in the real world. Key solution idea: No need to try to learn one accurate simulator. We can learn an ensemble of models that together will sufficiently represent the space. If we learn an ensemble of models (to be used as many learned simulators) we can denoise estimates of performance. In a meta-learning sense these simulations become the tasks. The real world is then just yet another task, to which the policy could adapt quickly. One experimental observation is that at the start of training there is a lot of variation between learned simulators, and then the simulations come together over training, which might also point to this approach providing improved exploration. This summary was written with the help of Pieter Abbeel. |
Explaining Image Classifiers by Counterfactual Generation
Chun-Hao Chang and Elliot Creager and Anna Goldenberg and David Duvenaud
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/07/20 (6 years ago)
Abstract: When an image classifier makes a prediction, which parts of the image are relevant and why? We can rephrase this question to ask: which parts of the image, if they were not seen by the classifier, would most change its decision? Producing an answer requires marginalizing over images that could have been seen but weren't. We can sample plausible image in-fills by conditioning a generative model on the rest of the image. We then optimize to find the image regions that most change the classifier's decision after in-fill. Our approach contrasts with ad-hoc in-filling approaches, such as blurring or injecting noise, which generate inputs far from the data distribution, and ignore informative relationships between different parts of the image. Our method produces more compact and relevant saliency maps, with fewer artifacts compared to previous methods.
more
less
Chun-Hao Chang and Elliot Creager and Anna Goldenberg and David Duvenaud
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/07/20 (6 years ago)
Abstract: When an image classifier makes a prediction, which parts of the image are relevant and why? We can rephrase this question to ask: which parts of the image, if they were not seen by the classifier, would most change its decision? Producing an answer requires marginalizing over images that could have been seen but weren't. We can sample plausible image in-fills by conditioning a generative model on the rest of the image. We then optimize to find the image regions that most change the classifier's decision after in-fill. Our approach contrasts with ad-hoc in-filling approaches, such as blurring or injecting noise, which generate inputs far from the data distribution, and ignore informative relationships between different parts of the image. Our method produces more compact and relevant saliency maps, with fewer artifacts compared to previous methods.
|
[link]
In the area of explaining model predictions over images, there are two main strains of technique: methods that look for pixels that have the highest gradient effect on the output class, and assign those as the “reason” for the class, and approaches that ask which pixel regions are most responsible for a given classification, in the sense that the classification would change the most if they were substituted with some uninformative reference value. The tricky thing about the second class of methods is that you need to decide what to use as your uninformative fill-in value. It’s easy enough to conceptually pose the problem of “what would our model predict if it couldn’t see this region of pixels,” but as a practical matter, these models take in full images, and you have to put *something* to give the classifier in a region, if you’re testing what the score would be if you removed the information contained in the pixels in that region. What should you fill in instead? The simplest answers are things like “zeros”, or “a constant value” or “white noise”. But all of these are very off-distribution for the model; it wouldn’t have typically seen images that resemble white noise, or all zeros, or all a single value. So if you measure the change in your model score from an off-distribution baseline to your existing pixels, you may not be getting the marginal value of the pixels, so much as the marginal disutility of having something so different from what the model has previously seen. There are other, somewhat more sensible approaches, like blurring out the areas around the pixel region of interest, but these experience less intense forms of the same issue. This paper proposes instead, using generative models to fill in the regions conditioned on the surrounding pixels, and use that as a reference. The notion here is that a conditioned generative model, like a GAN or VAE, can take into account the surrounding pixels, and “imagine” a fill-in that flows smoothly from the surrounding pixels, and looks generally like an image, but which doesn’t contain the information from the pixels in the region being tested, since it wasn’t conditioned on that. https://i.imgur.com/2fKnY0M.png Using this approach, the authors run two types of test: one where they optimize to find the smallest region they can remove from the image, and have it switch class (Smallest Deletion Region, or SDR), and also the smallest informative region that can be added to an otherwise uninformative image, and have the model predict the class connected to that region. They find that regions calculated using their generative model fill in, and specifically with GANs, find a smaller and more compact pixel region as their explanation for the prediction, which is consistent with both human intuitions and also with a higher qualitative sensibleness of the explanations found. |
Temporal Difference Variational Auto-Encoder
Gregor, Karol and Besse, Frederic
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Gregor, Karol and Besse, Frederic
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
This was definitely one of the more conceptually nuanced and complicated papers I’ve read recently, and I’ve only got about 60% confidence that I fully grasp all of its intuitions. However, I’m going to try to collect together what I did understand. There is a lot of research into generative models of text or image sequences, and some amount of research into building “models” in the reinforcement learning sense, where your model can predict future observations given current observations and your action. There’s an important underlying distinction here between model-based RL (where you learn a model of how the world evolves, and use that to optimize reward) and model-free RL (where you leave don’t bother explicitly learning a world model, and just directly try to optimize rewards) However, this paper identifies a few limitations of this research. 1) It’s largely focused on predicting observations, rather than predicting *state*. State is a bit of a fuzzy concept, and corresponds to, roughly, “the true underlying state of the game”. An example I like to use is a game where you walk in one door, and right next to it is a second door, which requires you to traverse the space and find rewards and a key before you can open. Now, imagine that the observation of your agent is it looking at the door. If the game doesn’t have any on-screen representation of the fact that you’ve found the key, it won’t be present in your observations, and you’ll observe the same thing at the point you have just entered and once you found the key. However, the state of the game at these two points will be quite different, in that in the latter case, your next states might be “opening the door” rather than “going to collect rewards”. Scenarios like this are referred to broadly as Partially Observable games or environments. This paper wants to build a model of how the game evolves into the future, but it wants to build a model of *state-to-state* evolution, rather than observation-to-observation evolution, since observations are typically both higher-dimensionality and also more noisy/less informative. 2) Past research has typically focused on predicting each next-step observation, rather than teaching models to be able to directly predict a state many steps in the future, without having to roll out the entire sequence of intermediate predictions. This is arguably quite valuable for making models that can predict the long term consequences of their decision This paper approaches that with an approach inspired by the Temporal Difference framework used in much of RL, in which you update your past estimate of future rewards by forcing it to be consistent with the actual observed rewards you encounter in the future. Except, in this model, we sample two a state (z1) and then a state some distance into the future (z2), and try to make our backwards-looking prediction of the state at time 1, taking into account observations that happened in between, match what our prediction was with only the information at time one. An important mechanistic nuance here is the idea of a “belief state”, something that captures all of your knowledge about game history up to a certain point. We can then directly sample a state Zt given the belief state Bt at that point. This isn’t actually possible with a model where we predict a state at time T given the state at time T-1, because the state at time Z-1 is itself a sample, and so in order to get a full distribution of Zt, you have to sample Zt over the distribution of Zt-1, and in order to get the distribution of Zt-1 you have to sample over the distribution of Zt-2, and so on and so on. Instead, we have a separate non-state variable, Bt that is created conditional on all our past observations (through a RNN). https://i.imgur.com/N0Al42r.png All said and done, the mechanics of this model look like: 1) Pick two points along the sequence trajectory 2) Calculate the belief state at each point, and, from that, construct a distribution over states at each timestep using p(z|b) 3) Have an additional model that predicts z1 given z2, b1, and b2 (that is, the future beliefs and states), and push the distribution over z1 from this model to be close to the distribution over z1 given only the information available at time t1 4) Have a model that predicts Z2 given Z1 and the time interval ahead that we’re jumping, and try to have this model be predictive/have high likelihood over the data 5) And, have a model that predicts an observation at time T2 given the state Z2, and train that so that we can convert our way back to an observation, given a state They mostly test it on fairly simple environments, but it’s an interesting idea, and I’d be curious to see other people develop it in future. (A strange aspect of this model is that, as far as I can tell, it’s non-interventionist, in that we’re not actually conditioning over agent action, or trying to learn a policy for an agent. This is purely trying to learn the long term transitions between states) |
Meta-Learning Update Rules for Unsupervised Representation Learning
Luke Metz and Niru Maheswaranathan and Brian Cheung and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.NE, stat.ML
First published: 2018/03/31 (6 years ago)
Abstract: A major goal of unsupervised learning is to discover data representations that are useful for subsequent tasks, without access to supervised labels during training. Typically, this involves minimizing a surrogate objective, such as the negative log likelihood of a generative model, with the hope that representations useful for subsequent tasks will arise as a side effect. In this work, we propose instead to directly target later desired tasks by meta-learning an unsupervised learning rule which leads to representations useful for those tasks. Specifically, we target semi-supervised classification performance, and we meta-learn an algorithm -- an unsupervised weight update rule -- that produces representations useful for this task. Additionally, we constrain our unsupervised update rule to a be a biologically-motivated, neuron-local function, which enables it to generalize to different neural network architectures, datasets, and data modalities. We show that the meta-learned update rule produces useful features and sometimes outperforms existing unsupervised learning techniques. We further show that the meta-learned unsupervised update rule generalizes to train networks with different widths, depths, and nonlinearities. It also generalizes to train on data with randomly permuted input dimensions and even generalizes from image datasets to a text task.
more
less
Luke Metz and Niru Maheswaranathan and Brian Cheung and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.NE, stat.ML
First published: 2018/03/31 (6 years ago)
Abstract: A major goal of unsupervised learning is to discover data representations that are useful for subsequent tasks, without access to supervised labels during training. Typically, this involves minimizing a surrogate objective, such as the negative log likelihood of a generative model, with the hope that representations useful for subsequent tasks will arise as a side effect. In this work, we propose instead to directly target later desired tasks by meta-learning an unsupervised learning rule which leads to representations useful for those tasks. Specifically, we target semi-supervised classification performance, and we meta-learn an algorithm -- an unsupervised weight update rule -- that produces representations useful for this task. Additionally, we constrain our unsupervised update rule to a be a biologically-motivated, neuron-local function, which enables it to generalize to different neural network architectures, datasets, and data modalities. We show that the meta-learned update rule produces useful features and sometimes outperforms existing unsupervised learning techniques. We further show that the meta-learned unsupervised update rule generalizes to train networks with different widths, depths, and nonlinearities. It also generalizes to train on data with randomly permuted input dimensions and even generalizes from image datasets to a text task.
|
[link]
Unsupervised representation learning is a funny thing: our aspiration in learning representations from data is typically that they’ll be useful for future tasks, but, since we (by definition) don’t have access to labels, our approach has historically been to define heuristics, such as representing the data distribution in a low-dimensional space, and hope that those heuristics translate to useful learned representations. And, to a fair extent, they have. However, this paper’s goal is to attach this problem more directly, by explicitly meta-learning an unsupervised update rule so that performs well in future tasks. They do this by: https://i.imgur.com/EEkpW9g.png 1) Defining a parametrized weight update function, to slot into the role that Stochastic Gradient Descent on a label-defined loss function would play in a supervised network. This function calculates a “hidden state”, is defined for each neuron in each layer, and takes in the pre and post-nonlinearity activations for that batch, the hidden state of the next layer, and a set of learned per-layer “backwards weights”. The weight update for that neuron is then calculated using the current hidden state, the last batch's hidden state, and the current value of the weight. In the traditional way of people in this field who want to define some generic function, they instantiate these functions as a MLP. 2) Using that update rule on the data from a new task, taking the representing resulting from applying the update rule, and using it in a linear regression with a small number of samples. The generalization performance from this k-shot regression, taken in expectation over multiple tasks, acts as our meta training objective. By back-propagating from this objective, to the weight values of the representation, and from there to the parameters of the optimization step, they incentivize their updater to learn representations that are useful across some distribution of tasks. A slightly weird thing about this paper is that they train on image datasets, but shuffle the pixels and use a fully connected network rather than a conv net. I presume this has to do with the complexities of defining a weight update rule for a convolution, but it does make it harder to meaningfully compare with other image-based unsupervised systems, which are typically done using convolution. An interesting thing they note is that, early in meta-training on images, their update rules generalize fairly well to text data. However, later in training the update rules seem to have specialized to images, and generalize more poorly to images. |
Learning to Navigate in Cities Without a Map
Mirowski, Piotr and Grimes, Matthew Koichi and Malinowski, Mateusz and Hermann, Karl Moritz and Anderson, Keith and Teplyashin, Denis and Simonyan, Karen and Kavukcuoglu, Koray and Zisserman, Andrew and Hadsell, Raia
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Mirowski, Piotr and Grimes, Matthew Koichi and Malinowski, Mateusz and Hermann, Karl Moritz and Anderson, Keith and Teplyashin, Denis and Simonyan, Karen and Kavukcuoglu, Koray and Zisserman, Andrew and Hadsell, Raia
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper out of DeepMind used a Google StreetView dataset and set out to train a network capable of navigating to a given goal destination, without knowing where it was on any birds-eye map, and with its only input being photographic viewpoint images of its current location and orientation. This was done through a framework of reinforcement learning, where the model is conditioned on a representation of its goal, and given the image features of its current view of the world, and has to take actions like “turn left,” “turn sharply left”, “go forward”, etc, in order to navigate. Rather than lat-long, goals are specified in city-specific ways, in terms of the distance between the goal position and a reference set of landmarks. I don’t entirely understand the motivation behind this approach; the authors say it’s more scalable, but it wasn’t obvious to me why that would be the case. https://i.imgur.com/V3UATsK.png - The authors construct different architectures that combine these two fundamental pieces of input data - current image and the goal you’re trying to reach - in different ways. In the simplest model, called GoalNav, there’s a single LSTM that combines the goal information with the output of a convolutional encoder processing images of your current viewpoint. - In the next most complex, CityNav, there are two LSTMs: one for processing your goal, and the other for combining the output of the goal network with your convolutional inputs, in order to decide on an action. Notionally, this separation of tasks corresponds to “figure out what absolute to go in, given your goal”, and “figure out how to go in that absolute direction from where you are now”. As a way to support training, the goal network is trained with an auxiliary loss function where it needs to predict how far its current orientation is from North. Note that this does pass some amount of information about current location into the model (since the network gets to know its actual orientation relative to true north), but this is only available during training, with the hope that the model will have gotten good enough at predicting orientation to perform well. - The final model, similar to above, is called MultiCityNav, and is explicitly designed for transfer learning. Instead of training multiple cities on a single shared network, only the convolutional encoder and policy network (the “how do I go in the absolute direction needed to reach my goal” parts) are shared between cities, and the goal processing LSTM (the “which direction should I be going in” part) is re-trained per city. This is designed to allow for transfer in the parts of learning you would expect to generalize, but allow the network to learn a city-specific approach for converting between goal specifications (in terms of city landmarks) and direction. In order to get over the fact that reward in this setting is very sparse (i.e. you only get reward when you reach the goal), the authors (1) train in a curriculum fashion, starting with tasks very nearby the model’s starting point, and gradually getting longer, and (2) add a small amount of reward shaping, where you get rewarded for moving in the direction of the goal, but only if you’re within 200m of it. This last is a bit of a concession on the realism front, and the authors say as much, but it’s just quite hard to train RL with purely dense rewards, and it makes sense that reward shaping would help here. Ultimately, they were able to get performance (in terms of goal-reaching rewards) around ¾ as strong as an Oracle model, who had access to the full map and could calculate the true shortest path. |
Systematic Generalization: What Is Required and Can It Be Learned?
Dzmitry Bahdanau and Shikhar Murty and Michael Noukhovitch and Thien Huu Nguyen and Harm de Vries and Aaron Courville
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL, cs.AI
First published: 2018/11/30 (5 years ago)
Abstract: Numerous models for grounded language understanding have been recently proposed, including (i) generic models that can be easily adapted to any given task and (ii) intuitively appealing modular models that require background knowledge to be instantiated. We compare both types of models in how much they lend themselves to a particular form of systematic generalization. Using a synthetic VQA test, we evaluate which models are capable of reasoning about all possible object pairs after training on only a small subset of them. Our findings show that the generalization of modular models is much more systematic and that it is highly sensitive to the module layout, i.e. to how exactly the modules are connected. We furthermore investigate if modular models that generalize well could be made more end-to-end by learning their layout and parametrization. We find that end-to-end methods from prior work often learn inappropriate layouts or parametrizations that do not facilitate systematic generalization. Our results suggest that, in addition to modularity, systematic generalization in language understanding may require explicit regularizers or priors.
more
less
Dzmitry Bahdanau and Shikhar Murty and Michael Noukhovitch and Thien Huu Nguyen and Harm de Vries and Aaron Courville
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL, cs.AI
First published: 2018/11/30 (5 years ago)
Abstract: Numerous models for grounded language understanding have been recently proposed, including (i) generic models that can be easily adapted to any given task and (ii) intuitively appealing modular models that require background knowledge to be instantiated. We compare both types of models in how much they lend themselves to a particular form of systematic generalization. Using a synthetic VQA test, we evaluate which models are capable of reasoning about all possible object pairs after training on only a small subset of them. Our findings show that the generalization of modular models is much more systematic and that it is highly sensitive to the module layout, i.e. to how exactly the modules are connected. We furthermore investigate if modular models that generalize well could be made more end-to-end by learning their layout and parametrization. We find that end-to-end methods from prior work often learn inappropriate layouts or parametrizations that do not facilitate systematic generalization. Our results suggest that, in addition to modularity, systematic generalization in language understanding may require explicit regularizers or priors.
|
[link]
The paper discusses neural module network trees (NMN-trees). Here modules are composed in a tree structure to answer a question/task and modules are trained in different configurations to ensure they learn more core concepts and can generalize. Longer summary: How to perform systematic generalization? First we need to ask how good current models are at understanding language. Adversarial examples show how fragile these models can be. This leads us to conclude that systematic generalization is an issue that requires specific attention. Maybe we should rethink the modeling assumptions being made. We can think that samples can come from different data domains but are generated by some set of shared rules. If we correctly learned these rules then domain shift in the test data would not hurt model performance. Currently we can construct an experiment to introduce systematic bias in the data which causes the performance to suffer. From this experiment we can start to determine what the issue is. A recent new idea is to force a model to have more independent units is neural module network trees (NMN-trees). Here modules are composed in a tree structure to answer a question/task and modules are trained in different configurations to ensure they learn more core concepts and can generalize. |
Diversity is All You Need: Learning Skills without a Reward Function
Eysenbach, Benjamin and Gupta, Abhishek and Ibarz, Julian and Levine, Sergey
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Eysenbach, Benjamin and Gupta, Abhishek and Ibarz, Julian and Levine, Sergey
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
[I do occasionally wonder if people will look back on the “Is All You Need” with genuine confusion in a few years. “Really…all you need?”] This paper merges the ideas of curiosity-based learning and hierarchical reinforcement learning, to propose an architecture for learning distinctive skills based solely on an incentive to make those skills distinguishable from one another and relatively internally random, rather than because they’re directly useful in achieving some reward. The notion of hierarchical reinforcement learning is that, instead of learning a single joint policy, we learn some discrete number of subpolicies, and then treat the distribution over those subpolicies as you would a distribution over actions in a baseline RL policy. In order to achieve a reward, a model jointly optimizes the action distribution of the subpolicies, and also the distribution over subpolicies. One issue with this approach, which is raised by this paper (though I don’t really have strong enough domain background here to know how much of a problem this is in practice) is that this joint optimization process means that, early in the process, we choose subpolicies that are doing the best, and sample more from and thus improve those. This “early exploitation” problem (in the explore vs exploit frame) means that we might not learn skills that would be valuable to know later on, but that don’t give us any reward until we’ve developed them further. To address this, this paper proposes DIAYN, an algorithm which (1) samples discrete latent skill vectors according to a uniform, high-entropy prior, rather than according to how useful we think they are now, and (2) doesn’t even have a direct notion of usefulness, but instead incentivizes shaping of skills to be more distinct from one another, in terms of the states that are visited by each skill’s policy. The network then learns policies conditioned on each skill vector, and at each point operates according to whichever has been sampled. This idea of distinctiveness is encapsulated by saying “we want to have high mutual information between the states visited by a skill, and the discrete ID of that skill,” or, in more practical terms, “we want to be able to train a discriminator to do a good job predicting which skill we’re sampling from, based on the states it sees. (I swear, every time I read a paper where someone uses mutual information these days, it’s actually a discriminator under the hood). https://i.imgur.com/2a378Bo.png This incentivizes the model to take actions associated with each skill that will get it to states that are unlikely to occur in any of the existing skills. Depending on what set of observations you give the discriminator to work with, you can shape what axes your skills are incentivized to vary on; if you try to discriminate skills based solely on an agent’s center of mass, you’ll end up with policies that vary their center of mass more wildly. The paper shows that, at least on simple environments, agents can learn distinctive clusters of skills based on this objective. An interesting analogy here is to unsupervised pretraining of e.g. large language models and other similar settings, where we first train a model without (potentially costly) explicit reward, and this gives us a starting point set of representations that allow us to reach good performance more quickly once we start training on supervised reward signal. There is some evidence that this pretraining effect could be captured by this kind of purely-exploratory approach, as suggested by experiments done to take the learned skills or subpolicies, hold them fixed, and train a meta-controller to pick subpolicies according to an external reward, where the “pretrained” policy reaches high reward more quickly. |
Exploration by Random Network Distillation
Burda, Yuri and Edwards, Harrison and Storkey, Amos and Klimov, Oleg
- 2018 via Local Bibsonomy
Keywords: reinforcement-learning
Burda, Yuri and Edwards, Harrison and Storkey, Amos and Klimov, Oleg
- 2018 via Local Bibsonomy
Keywords: reinforcement-learning
|
[link]
Reward functions are a funny part of modern reinforcement learning: enormously salient from the inside, if you’re coding or working with RL systems, yet not as clearly visible from the outside perspective, where we just see agents playing games in what seem to be human-like ways. Just seeing things from this angle, it can be easy to imagine that the mechanisms being used to learn are human-like as well. And, it’s true that some of the Atari games being examined are cases where there is in fact a clear, explicit reward in the form of points, that human players would also be trying to optimize. But in most cases, the world isn’t really in the habit of producing clear reward signals, and it definitely doesn’t typically do so on time scales that account for most of the learning humans do. So, it’s generally hypothesized that in addition to updating on (sparse) environmental rewards, humans also operate according to certain pre-coded, possibly evolutionarily-engineered heuristics, of which one is curiosity. The intuition is: it sure seems like, especially early in life, humans learn by interacting with objects purely driven by curiosity, and we’d love to somehow harness that same drive to allow our learning systems to function in environments lacking dense, informative reward signals. One such environment is the video game Montezuma’s Revenge, which in addition to being amusingly difficult to search for, is a game with sparse, long-range rewards, on which typical reward-based agents have historically performed poorly, and on which this current paper focuses. A strong existing tradition of curiosity objectives focuses on incentivizing agents to be able to better predict the next observation, given the current observation and their action within it. Intuitively, by training such a network on historical observations, and giving agents a bonus according to that prediction’s error on a given observation. The theory behind this is that if an agent isn’t able to predict the observation-transition dynamics at a given state, that probably means it hasn’t visited many nearby states, and so we want to incentivize it doing so to gain information. If this sounds familiar to the classic “explore vs exploit” trade-off, it’s very much a similar idea: in cases of clear reward, we should take the reward, but in cases of low or uncertain reward, there’s value to exploration. One difficulty of systems like the one described above is that they reward the agent for being in environments where the next observation is difficult to predict from the current one. And while that could describe novel states about which the agent needs to gain information, it can also describe states that are inherently stochastic; the canonical example being random static on a TV screen. The agent has a lot of trouble predicting the next observation because it’s fundamentally non-deterministic to a greater degree than even the random-but-causal dynamics of most games. The proposed alternative of this paper is a little strange, but makes more sense in the context of responding to this stochasticity problem. The authors propose to create a random mapping, in the form of an initialized but untrained neural network, taking in observations and spitting out embedding vectors. Then, they incentivize their agent to go to places that have high prediction error on a network designed to predict these random embeddings. Since the output is just a function mapping, it’s deterministic with respect to observations. The idea here is that if you’ve seen observations similar to your current observation, you’ll be more able to predict the corresponding embedding, even if there’s no meaningful relationship that you’re learning. https://i.imgur.com/Ds5gHDE.png The authors found that this performed well on Montezuma’s Revenge and Private Eye, but only middlingly-well on other environments. I’m a bit torn on this paper overall. On one hand, it seems like a clever idea, and I’m in general interested in seeing more work on curiosity. It does clearly seem to be capturing something that corresponds to novelty-seeking, and the agent trained using it explores a higher number of rooms than alternative options. On the other, I’m a little skeptical of the fact that it only has consistent performance in two environments, and wish there had been more comparisons to simpler forms of observation similarity, since this really does just seem like a metric of “how similar of observation vectors to this have you seen before”. I find myself wondering if some sort of density modeling could even be effective here, especially if (as may be the case, I’m unsure) the input observations are metadata rather than pixels. |
Effective Ways to Build and Evaluate Individual Survival Distributions
Humza Haider and Bret Hoehn and Sarah Davis and Russell Greiner
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/11/28 (5 years ago)
Abstract: An accurate model of a patient's individual survival distribution can help determine the appropriate treatment for terminal patients. Unfortunately, risk scores (e.g., from Cox Proportional Hazard models) do not provide survival probabilities, single-time probability models (e.g., the Gail model, predicting 5 year probability) only provide for a single time point, and standard Kaplan-Meier survival curves provide only population averages for a large class of patients meaning they are not specific to individual patients. This motivates an alternative class of tools that can learn a model which provides an individual survival distribution which gives survival probabilities across all times - such as extensions to the Cox model, Accelerated Failure Time, an extension to Random Survival Forests, and Multi-Task Logistic Regression. This paper first motivates such "individual survival distribution" (ISD) models, and explains how they differ from standard models. It then discusses ways to evaluate such models - namely Concordance, 1-Calibration, Brier score, and various versions of L1-loss - and then motivates and defines a novel approach "D-Calibration", which determines whether a model's probability estimates are meaningful. We also discuss how these measures differ, and use them to evaluate several ISD prediction tools, over a range of survival datasets.
more
less
Humza Haider and Bret Hoehn and Sarah Davis and Russell Greiner
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/11/28 (5 years ago)
Abstract: An accurate model of a patient's individual survival distribution can help determine the appropriate treatment for terminal patients. Unfortunately, risk scores (e.g., from Cox Proportional Hazard models) do not provide survival probabilities, single-time probability models (e.g., the Gail model, predicting 5 year probability) only provide for a single time point, and standard Kaplan-Meier survival curves provide only population averages for a large class of patients meaning they are not specific to individual patients. This motivates an alternative class of tools that can learn a model which provides an individual survival distribution which gives survival probabilities across all times - such as extensions to the Cox model, Accelerated Failure Time, an extension to Random Survival Forests, and Multi-Task Logistic Regression. This paper first motivates such "individual survival distribution" (ISD) models, and explains how they differ from standard models. It then discusses ways to evaluate such models - namely Concordance, 1-Calibration, Brier score, and various versions of L1-loss - and then motivates and defines a novel approach "D-Calibration", which determines whether a model's probability estimates are meaningful. We also discuss how these measures differ, and use them to evaluate several ISD prediction tools, over a range of survival datasets.
|
[link]
The paper looks at approaches to predicting individual survival time distributions (isd). The motivation is shown in the figure below. Between two patients the survival time varies greatly so we should be able to predict a distribution like the red curve.
https://i.imgur.com/2r9JvUp.png
The paper studies the following methods:
- class-based survival curves Kaplan-Meier [31]
- Kalbfleisch-Prentice extension of the Cox (cox-kp) [29]
- Accelerated Failure Time (aft) model [29]
- Random Survival Forest model with Kaplan-Meier extensions (rsf-km)
- elastic net Cox (coxen-kp) [55]
- Multi-task Logistic Regression (mtlr) [57]
Looking at the predictions of these methods side by side we can observe some systematic differences between the methods:
https://i.imgur.com/vJoCL4a.png
The paper presents a "D-Calibration" metric (distributional calibration) which represents of the method answers this question:
Should the patient believe the predictions implied by the survival curve?
https://i.imgur.com/MX8CbZ7.png
|
On the Suitability of Lp-Norms for Creating and Preventing Adversarial Examples
Sharif, Mahmood and Bauer, Lujo and Reiter, Michael K.
Conference and Computer Vision and Pattern Recognition - 2018 via Local Bibsonomy
Keywords: dblp
Sharif, Mahmood and Bauer, Lujo and Reiter, Michael K.
Conference and Computer Vision and Pattern Recognition - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Sharif et al. study the effectiveness of $L_p$ norms for creating adversarial perturbations. In this context, their main discussion revolves around whether $L_p$ norms are sufficient and/or necessary for perceptual similarity. Their main conclusion is that $L_p$ norms are neither necessary nor sufficient to ensure perceptual similarity. For example, an adversarial example might be within a specific $L_p$ bal, but humans might still identify it as not similar enough to the originally attacked sample; on the other hand, there are also some imperceptible perturbations that usually extend beyond a reasonable $L_p$ ball. Such transformatons might for example include small rotations or translation. These findings are interesting because it indicates that our current model, or approximation, or perceptual similarity is not meaningful in all cases. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Deep k-Nearest Neighbors: Towards Confident, Interpretable and Robust Deep Learning
Nicolas Papernot and Patrick McDaniel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/03/13 (6 years ago)
Abstract: Deep neural networks (DNNs) enable innovative applications of machine learning like image recognition, machine translation, or malware detection. However, deep learning is often criticized for its lack of robustness in adversarial settings (e.g., vulnerability to adversarial inputs) and general inability to rationalize its predictions. In this work, we exploit the structure of deep learning to enable new learning-based inference and decision strategies that achieve desirable properties such as robustness and interpretability. We take a first step in this direction and introduce the Deep k-Nearest Neighbors (DkNN). This hybrid classifier combines the k-nearest neighbors algorithm with representations of the data learned by each layer of the DNN: a test input is compared to its neighboring training points according to the distance that separates them in the representations. We show the labels of these neighboring points afford confidence estimates for inputs outside the model's training manifold, including on malicious inputs like adversarial examples--and therein provides protections against inputs that are outside the models understanding. This is because the nearest neighbors can be used to estimate the nonconformity of, i.e., the lack of support for, a prediction in the training data. The neighbors also constitute human-interpretable explanations of predictions. We evaluate the DkNN algorithm on several datasets, and show the confidence estimates accurately identify inputs outside the model, and that the explanations provided by nearest neighbors are intuitive and useful in understanding model failures.
more
less
Nicolas Papernot and Patrick McDaniel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/03/13 (6 years ago)
Abstract: Deep neural networks (DNNs) enable innovative applications of machine learning like image recognition, machine translation, or malware detection. However, deep learning is often criticized for its lack of robustness in adversarial settings (e.g., vulnerability to adversarial inputs) and general inability to rationalize its predictions. In this work, we exploit the structure of deep learning to enable new learning-based inference and decision strategies that achieve desirable properties such as robustness and interpretability. We take a first step in this direction and introduce the Deep k-Nearest Neighbors (DkNN). This hybrid classifier combines the k-nearest neighbors algorithm with representations of the data learned by each layer of the DNN: a test input is compared to its neighboring training points according to the distance that separates them in the representations. We show the labels of these neighboring points afford confidence estimates for inputs outside the model's training manifold, including on malicious inputs like adversarial examples--and therein provides protections against inputs that are outside the models understanding. This is because the nearest neighbors can be used to estimate the nonconformity of, i.e., the lack of support for, a prediction in the training data. The neighbors also constitute human-interpretable explanations of predictions. We evaluate the DkNN algorithm on several datasets, and show the confidence estimates accurately identify inputs outside the model, and that the explanations provided by nearest neighbors are intuitive and useful in understanding model failures.
|
[link]
Papernot and McDaniel introduce deep k-nearest neighbors where nearest neighbors are found at each intermediate layer in order to improve interpretbaility and robustness. Personally, I really appreciated reading this paper; thus, I will not only discuss the actually proposed method but also highlight some ideas from their thorough survey and experimental results. First, Papernot and McDaniel provide a quite thorough survey of relevant work in three disciplines: confidence, interpretability and robustness. To the best of my knowledge, this is one of few papers that explicitly make the connection of these three disciplines. Especially the work on confidence is interesting in the light of robustness as Papernot and McDaniel also frequently distinguish between in-distribution and out-distribution samples. Here, it is commonly known that deep neural networks are over-confidence when moving away from the data distribution. The deep k-nearest neighbor approach is described in Algorithm 1 and summarized in the following. For a trained model and a training set of labeled samples, they first find k nearest neighbors for each intermediate layer of the network. The layer nonconformity with a specific label $j$, referred to as $\alpha$ in Algorithm 1, is computed as the number of labels that in the set of nearest neighbors that do not share this label. By comparing these nonconformity values to a set of reference values (computing over a set of labeled calibration data), the prediction can be refined. In particular, the probability for label $j$ can be computed as the fraction of reference nonconformity values that are higher than the computed one. See Algorthm 1 or the paper for details. https://i.imgur.com/RA6q1VI.png https://i.imgur.com/CkRf8ex.png Algorithm 1: The deep k-nearest neighbor algorithm and an illustration. Finally, they provide experimental results – again considering the three disciplines of confidence/credibility, interpretability and robustness. The main take-aways are that the resulting confidences are more reliable on out-of-distribution samples, which also include adversarial examples. Additioanlly, the nearest neighbor allow very basic interpretation of the predictions. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Towards Imperceptible and Robust Adversarial Example Attacks against Neural Networks
Bo Luo and Yannan Liu and Lingxiao Wei and Qiang Xu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML
First published: 2018/01/15 (6 years ago)
Abstract: Machine learning systems based on deep neural networks, being able to produce state-of-the-art results on various perception tasks, have gained mainstream adoption in many applications. However, they are shown to be vulnerable to adversarial example attack, which generates malicious output by adding slight perturbations to the input. Previous adversarial example crafting methods, however, use simple metrics to evaluate the distances between the original examples and the adversarial ones, which could be easily detected by human eyes. In addition, these attacks are often not robust due to the inevitable noises and deviation in the physical world. In this work, we present a new adversarial example attack crafting method, which takes the human perceptual system into consideration and maximizes the noise tolerance of the crafted adversarial example. Experimental results demonstrate the efficacy of the proposed technique.
more
less
Bo Luo and Yannan Liu and Lingxiao Wei and Qiang Xu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, stat.ML
First published: 2018/01/15 (6 years ago)
Abstract: Machine learning systems based on deep neural networks, being able to produce state-of-the-art results on various perception tasks, have gained mainstream adoption in many applications. However, they are shown to be vulnerable to adversarial example attack, which generates malicious output by adding slight perturbations to the input. Previous adversarial example crafting methods, however, use simple metrics to evaluate the distances between the original examples and the adversarial ones, which could be easily detected by human eyes. In addition, these attacks are often not robust due to the inevitable noises and deviation in the physical world. In this work, we present a new adversarial example attack crafting method, which takes the human perceptual system into consideration and maximizes the noise tolerance of the crafted adversarial example. Experimental results demonstrate the efficacy of the proposed technique.
|
[link]
Luo et al. Propose a method to compute less-perceptible adversarial examples compared to standard methods constrained in $L_p$ norms. In particular, they consider the local variation of the image and argue that humans are more likely to notice larger variations in low-variance regions than vice-versa. The sensitivity of a pixel is therefore defined as one over its local variance, meaning that it is more sensitive to perturbations. They propose a simple algorithm which iteratively sorts pixels by their sensitivity and then selects a subset to perturb each step. Personally, I wonder why they do not integrate the sensitivity into simple projected gradient descent attacks, where a Lagrange multiplier is used to enforce the $L_p$ norm of the sensitivity weighted perturbation. However, qualitative results show that their approach also works well and results in (partly) less perceptible changes, see Figure 1. https://i.imgur.com/M7Ile8Y.png Figure 1: Qualitative results including a comparison to other state-of-the-art attacks. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Spatially Transformed Adversarial Examples
Xiao, Chaowei and Zhu, Jun-Yan and Li, Bo and He, Warren and Liu, Mingyan and Song, Dawn
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Xiao, Chaowei and Zhu, Jun-Yan and Li, Bo and He, Warren and Liu, Mingyan and Song, Dawn
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Xiao et al. propose adversarial examples based on spatial transformations. Actually, this work is very similar to the adversarial deformations of [1]. In particular, a deformation flow field is optimized (allowing individual deformations per pixel) to cause a misclassification. The distance of the perturbation is computed on the flow field directly. Examples on MNIST are shown in Figure 1 – it can clearly be seen that most pixels are moved individually and no kind of smoothness is enforced. They also show that commonly used defense mechanisms are more or less useless against these attacks. Unfortunately, and in contrast to [1], they do not consider adversarial training on their own adversarial transformations as defense. https://i.imgur.com/uDfttMU.png Figure 1: Examples of the computed adversarial examples/transformations on MNIST for three different models. Note that these are targeted attacks. [1] R. Alaifair, G. S. Alberti, T. Gauksson. Adef: an Iterative Algorithm to Construct Adversarial Deformations. ArXiv, abs/1804.07729v2, 2018. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Robustness of Rotation-Equivariant Networks to Adversarial Perturbations
Dumont, Beranger and Maggio, Simona and Montalvo, Pablo
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Dumont, Beranger and Maggio, Simona and Montalvo, Pablo
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Dumont et al. Compare different adversarial transformation attacks (including rotations and translations) against common as well as rotation-invariant convolutional neural networks. On MNIST, CIFAR-10 and ImageNet, they consider translations, rotations as well as the attack of [1] based on spatial transformer networks. Additionally, they consider rotation-invariant convolutional neural networks – however, both the attacks and the networks are not discussed/introduced in detail. The results are interesting because translation- and rotation-based attacks are significantly more successful on CIFAR-10 compared to MNIST and ImageNet. The authors, however, do not give a satisfying explanation of this observation. [1] C. Xiao, J.-Y. Zhu, B. Li, W. H, M. Liu, D. Song. Spatially-Transformed Adversarial Examples. ICLR, 2018. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Athalye, Anish and Carlini, Nicholas and Wagner, David A.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Athalye, Anish and Carlini, Nicholas and Wagner, David A.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Athalye et al. propose methods to circumvent different types of defenses against adversarial example based on obfuscated gradients. In particular, they identify three types of obfuscated gradients: shattered gradients (e.g., caused by undifferentiable parts of a network or through numerical instability), stochastic gradients, and exploding and vanishing gradients. These phenomena all influence the effectiveness of gradient-based attacks. Athalye et al. Give several indicators of how to find out when obfuscated gradients occur. Personally, I find most of these points straight forward, but it is still beneficial to write these “debug strategies” down. The main contribution, however, is a comprehensive evaluation of all eight ICLR’18 defenses against state-of-the-art attacks. As all (except adversarial training) cause obfuscated gradients, Athalye et al. Discuss several strategies to “un-obfuscate” the gradients to successfully compute adversarial examples. Overall, they show that seven out of eight defenses are not reliable, only adversarial training with projected gradient descent can withstand attacks limited to $\epsilon\approx 0.3$. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
ADef: an Iterative Algorithm to Construct Adversarial Deformations
Alaifari, Rima and Alberti, Giovanni S. and Gauksson, Tandri
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Alaifari, Rima and Alberti, Giovanni S. and Gauksson, Tandri
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Alaifari et al. propose an iterative attack to construct adversarial deformations of images. In particular, and in contrast to general adversarial perturbations, adversarial deformations are described through a deformation vector field – and the corresponding norm of this vector field may be bounded; an illustration can be found in Figure 1. The adversarial deformation is computed iteratively where the deformation itself is expressed in a differentiable manner. In contrast to very simple transformations such as rotations and translations, the computed adversarial deformations may contain significantly more subtle deformations as shown in Figure 2. The authors show that such deformations can successful attack MNIST and ImageNet models. https://i.imgur.com/7N8rLaK.png Figure 1: Illustration of the advantage of using general pixel-level deformations compared to simple transformations such as translations or rotations. https://i.imgur.com/dCWBoI8.png Figure 2: Illustration of untargeted (top) and targeted (bottom) attacks on ImageNet. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
On the Robustness of the CVPR 2018 White-Box Adversarial Example Defenses
Athalye, Anish and Carlini, Nicholas
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Athalye, Anish and Carlini, Nicholas
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Athalye and Carlini present experiments showing that pixel deflection [1] and high-level guided denoiser [2] are ineffective as defense against adversarial examples. In particular, they show that these defenses are not effective against the (currently) strongest first-order attack, projected gradient descent. Here, they also comment on the right threat model to use and explicitly state that the attacker would know the employed defense – which intuitively makes much sense when evaluating defenses. [1] Prakash, Aaditya, Moran, Nick, Garber, Solomon, DiLillo, Antonella, and Storer, James. Deflecting adversarial at tacks with pixel deflection. In CVPR, 2018. [2] Liao, Fangzhou, Liang, Ming, Dong, Yinpeng, Pang, Tianyu, Zhu, Jun, and Hu, Xiaolin. Defense against adversarial attacks using high-level representation guided denoiser. In CVPR, 2018. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
There Is No Free Lunch In Adversarial Robustness (But There Are Unexpected Benefits)
Tsipras, Dimitris and Santurkar, Shibani and Engstrom, Logan and Turner, Alexander and Madry, Aleksander
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Tsipras, Dimitris and Santurkar, Shibani and Engstrom, Logan and Turner, Alexander and Madry, Aleksander
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Tsipras et al. investigate the trade-off between classification accuracy and adversarial robustness. In particular, on a very simple toy dataset, they proof that such a trade-off exists; this means that very accurate models will also have low robustness. Overall, on this dataset, they find that there exists a sweet-spot where the accuracy is 70% and the adversarial accuracy (i.e., accuracy on adversarial examples) is 70%. Using adversarial training to obtain robust networks, they additionally show that the robustness is increased by not using “fragile” features – features that are only weakly correlated with the actual classification tasks. Only focusing on few, but “robust” features also has the advantage of more interpretable gradients and sparser weights (or convolutional kernels). Due to the induced robustness, adversarial examples are perceptually significantly more different from the original examples, as illustrated in Figure 1 on MNIST. https://i.imgur.com/OP2TOOu.png Figure 1: Illustration of adversarial examples for a standard model, a model trained using $L_\infty$ adversarial training and $L_2$ adversarial training. Especially for the $L_2$ case it is visible that adversarial examples need to change important class characteristics to fool the network. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Protecting JPEG Images Against Adversarial Attacks
Prakash, Aaditya and Moran, Nick and Garber, Solomon and DiLillo, Antonella and Storer, James A.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Prakash, Aaditya and Moran, Nick and Garber, Solomon and DiLillo, Antonella and Storer, James A.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Motivated by JPEG compression, Prakash et al. propose an adaptive quantization scheme as defense against adversarial attacks. They argue that JPEG experimentally reduces adversarial noise; however, it is difficult to automatically decide on the level of compression as it also influences a classifier’s performance. Therefore, Prakash et al. use a saliency detector to identify background region, and then apply adaptive quantization – with coarser detail at the background – to reduce the impact of adversarial noise. In experiments, they demonstrate that this approach outperforms simple JPEG compression as defense while having less impact on the image quality. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Logit Pairing
Kannan, Harini and Kurakin, Alexey and Goodfellow, Ian J.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Kannan, Harini and Kurakin, Alexey and Goodfellow, Ian J.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Kannan et al. propose a defense against adversarial examples called adversarial logit pairing where the logits of clean and adversarial example are regularized to be similar. In particular, during adversarial training, they add a regularizer of the form $\lambda L(f(x), f(x’))$ were $L$ is, for example, the $L_2$ norm and $f(x’)$ the logits corresponding to adversarial example $x’$ (corresponding to clean example $x$). Intuitively, this is a very simple approach – adversarial training itself enforces the classification results of clean and corresponding adversarial examples to be the same and adversarial logit pairing enforces the internal representation, i.e., the logits, to be similar. In theory, this could also be applied to any set of activations within the network. In the paper, they conclude that “We hypothesize that adversarial logit pairing works well because it provides an additional prior that regularizes the model toward a more accurate understanding of the classes.” In experiments, they show that this approach slightly outperforms adversarial training alone on SVHN, MNIST as well as ImageNet. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Out-distribution training confers robustness to deep neural networks
Abbasi, Mahdieh and Gagné, Christian
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Abbasi, Mahdieh and Gagné, Christian
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Abbasi and Gagné propose explicit but natural out-distribution training as defense against adversarial examples. Specifically, as also illustrated on the toy dataset in Figure 1, they argue that networks commonly produce high-confident predictions in regions that are clearly outside of the data manifold (i.e., the training data distribution). As mitigation strategy, the authors propose to explicitly train on out-of-distribution data, allowing the network to additionally classify this data as “dustbin” data. On MNIST, for example, this data comes from NotMNIST, a dataset of letters A-J – on CIFA-10, this data could be CIFAR-100. Experiments show that this out-of-distribution training allow networks to identify adversarial examples as “dustbin” and thus improve robustness. https://i.imgur.com/nUSDZay.png Figure 1: Illustration of a naive model versus an augmented model, i.e., trained on out-of-distribution data, on a toy dataset (left) and on MNIST (right). Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Defense based on Structure-to-Signal Autoencoders
Folz, Joachim and Palacio, Sebastian and Hees, Jörn and Borth, Damian and Dengel, Andreas
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Folz, Joachim and Palacio, Sebastian and Hees, Jörn and Borth, Damian and Dengel, Andreas
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Folz et al. propose an auto-encoder based defense against adversarial examples. In particular, they propose structure-to-signal auto-encoders, S2SNets, as defense mechanism – this auto-encoder is first trained in an unsupervised fashion to reconstruct images (which can be done independent of attack models or the classification network under attack). Then, the network’s decoder is fine tuned using gradients from the classification network. Their main argumentation is that the gradients of the composite network – auto-encoder plus classification network – are not class specific anymore as only the decoder is fine-tuned but not the encoder (as the encoder is trained to encode any image independent of the classification task). Experimentally they show that the gradients are indeed less class-specific. Additionally, the authors highlight that this defense is independent of an attack model and can be applied to any pre-trained classification model. Unforutntely, the approach is not compared against other defense machenisms – while related work was mentioned, a comparison would have been useful. Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Improving MMD-GAN Training with Repulsive Loss Function
Wei Wang and Yuan Sun and Saman Halgamuge
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, stat.ML
First published: 2018/12/24 (5 years ago)
Abstract: Generative adversarial nets (GANs) are widely used to learn the data sampling process and their performance may heavily depend on the loss functions, given a limited computational budget. This study revisits MMD-GAN that uses the maximum mean discrepancy (MMD) as the loss function for GAN and makes two contributions. First, we argue that the existing MMD loss function may discourage the learning of fine details in data as it attempts to contract the discriminator outputs of real data. To address this issue, we propose a repulsive loss function to actively learn the difference among the real data by simply rearranging the terms in MMD. Second, inspired by the hinge loss, we propose a bounded Gaussian kernel to stabilize the training of MMD-GAN with the repulsive loss function. The proposed methods are applied to the unsupervised image generation tasks on CIFAR-10, STL-10, CelebA, and LSUN bedroom datasets. Results show that the repulsive loss function significantly improves over the MMD loss at no additional computational cost and outperforms other representative loss functions. The proposed methods achieve an FID score of 16.21 on the CIFAR-10 dataset using a single DCGAN network and spectral normalization.
more
less
Wei Wang and Yuan Sun and Saman Halgamuge
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CV, stat.ML
First published: 2018/12/24 (5 years ago)
Abstract: Generative adversarial nets (GANs) are widely used to learn the data sampling process and their performance may heavily depend on the loss functions, given a limited computational budget. This study revisits MMD-GAN that uses the maximum mean discrepancy (MMD) as the loss function for GAN and makes two contributions. First, we argue that the existing MMD loss function may discourage the learning of fine details in data as it attempts to contract the discriminator outputs of real data. To address this issue, we propose a repulsive loss function to actively learn the difference among the real data by simply rearranging the terms in MMD. Second, inspired by the hinge loss, we propose a bounded Gaussian kernel to stabilize the training of MMD-GAN with the repulsive loss function. The proposed methods are applied to the unsupervised image generation tasks on CIFAR-10, STL-10, CelebA, and LSUN bedroom datasets. Results show that the repulsive loss function significantly improves over the MMD loss at no additional computational cost and outperforms other representative loss functions. The proposed methods achieve an FID score of 16.21 on the CIFAR-10 dataset using a single DCGAN network and spectral normalization.
|
[link]
**TL;DR**: Rearranging the terms in Maximum Mean Discrepancy yields a much better loss function for the discriminator of Generative Adversarial Nets.
**Keywords**: Generative adversarial nets, Maximum Mean Discrepancy, spectral normalization, convolutional neural networks, Gaussian kernel, local stability.
**Summary**
Generative adversarial nets (GANs) are widely used to learn the data sampling process and are notoriously difficult to train. The training of GANs may be improved from three aspects: loss function, network architecture, and training process.
This study focuses on a loss function called the Maximum Mean Discrepancy (MMD), defined as:
$$
MMD^2(P_X,P_G)=\mathbb{E}_{P_X}k_{D}(x,x')+\mathbb{E}_{P_G}k_{D}(y,y')-2\mathbb{E}_{P_X,P_G}k_{D}(x,y)
$$
where $G,D$ are the generator and discriminator networks, $x,x'$ are real samples, $y,y'$ are generated samples, $k_D=k\circ D$ is a learned kernel that calculates the similariy between two samples. Overall, MMD calculates the distance between the real and the generated sample distributions. Thus, traditionally, the generator is trained to minimize $L_G=MMD^2(P_X,P_G)$, while the discriminator minimizes $L_D=-MMD^2(P_X,P_G)$.
This study makes three contributions:
- It argues that $L_D$ encourages the discriminator to ignores the fine details in real data. By minimizing $L_D$, $D$ attempts to maximize $\mathbb{E}_{P_X}k_{D}(x,x')$, the similarity between real samples scores. Thus, $D$ has to focus on common features shared by real samples rather than fine details that separate them. This may slow down training. Instead, a repulsive loss is proposed, with no additional computational cost to MMD:
$$
L_D^{rep}=\mathbb{E}_{P_X}k_{D}(x,x')-\mathbb{E}_{P_G}k_{D}(y,y')
$$
- Inspired by the hinge loss, this study proposes a bounded Gaussian kernel for the discriminator to facilitate stable training of MMD-GAN.
- The spectral normalization method divides the weight matrix at each layer by its spectral norm to enforce that each layer is Lipschitz continuous. This study proposes a simple method to calculate the spectral norm of a convolutional kernel.
The results show the efficiency of proposed methods on CIFAR-10, STL-10, CelebA and LSUN-bedroom datasets. In Appendix, we prove that MMD-GAN training using gradient method is locally exponentially stable (a property that the Wasserstein loss does not have), and show that the repulsive loss works well with gradient penalty.
The paper has been accepted at ICLR 2019 ([OpenReview link](https://openreview.net/forum?id=HygjqjR9Km)). The code is available at [GitHub link](https://github.com/richardwth/MMD-GAN).
|

Learning a SAT Solver from Single-Bit Supervision
Selsam, Daniel and Lamm, Matthew and Bünz, Benedikt and Liang, Percy and de Moura, Leonardo and Dill, David L.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Selsam, Daniel and Lamm, Matthew and Bünz, Benedikt and Liang, Percy and de Moura, Leonardo and Dill, David L.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
The goal is to solve SAT problems with weak supervision: In that case a model is trained only to predict ***the satisfiability*** of a formula in conjunctive normal form. As a byproduct, when the formula is satisfiable, an actual satisfying assignment can be worked out by clustering the network's activations in most cases.
* **Pros (+):** Weak supervision, interesting structured architecture, seems to generalize nicely to harder problems by increasing the number message passing iterations.
* **Cons (-):** Limited practical applicability since it is outperfomed by classical SAT solvers.
---
# NeuroSAT
## Inputs
We consider Boolean logic formulas in their ***conjunctive normal form*** (CNF), i.e. each input formula is represented as a conjunction ($\land$) of **clauses**, which are themselves disjunctions ($\lor$) of litterals (positive or negative instances of variables). The goal is to learn a classifier to predict whether such a formula is satisfiable.
A first problem is how to encode the input formula in such a way that it preserves the CNF invariances (invariance to negating a litteral in all clauses, invariance to permutations in $\lor$ and $\land$ etc.). The authors use an ***undirected graph representation*** where:
* $\mathcal V$: vertices are the litterals (positive and negative form of variables, denoted as $x$ and $\bar x$) and the clauses occuring in the input formula
* $\mathcal E$: Edges are added to connect (i) the litterals with clauses they appear in and (ii) each litteral to its negative counterpart.
The graph relations are encoded as an ***adjacency matrix***, $A$, with as many rows as there are litterals and as many columns as there are clauses. In particular, this structure does not constrain the vertices ordering, and does not make any preferential treatment between positive or negative litterals. However it still has some caveats, which can be avoided by pre-processing the formula. For instance when there are disconnected components in the graph, the averaging decision rule (see next paragraph) can lead to false positives.
## Message-passing model
In a high-level view, the model keeps track of an embedding for each vertex (litterals, $L^t$ and clauses, $C^t$), updated via ***message-passing on the graph***, and combined via a Multi Layer perceptrion (MLP) to output the model prediction of the formula's satisfiability. The model updates are as follow:
$$
\begin{align}
C^t, h_C^t &= \texttt{LSTM}_\texttt{C}(h_C^{t - 1}, A^T \texttt{MLP}_{\texttt{L}}(L^{t - 1}) )\ \ \ \ \ \ \ \ \ \ \ (1)\\
L^t, h_L^t &= \texttt{LSTM}_\texttt{L}(h_L^{t - 1}, \overline{L^{t - 1}}, A\ \texttt{MLP}_{\texttt{C}}(C^{t }) )\ \ \ \ \ \ (2)
\end{align}
$$
where $h$ designates a hidden context vector for the LSTMs. The operator $L \mapsto \bar{L}$ returns $\overline{L}$, the embedding matrix $L$ where the row of each litteral is swapped with the one corresponding to the litteral's negation.
In other words, in **(1)** each clause embedding is updated based on the litteral that composes it, while in **(2)** each litteral embedding is updated based on the clauses it appears in and its negated counterpart.
After $T$ iterations of this message-passing scheme, the model computes a ***logit for the satisfiability classification problem***, which is trained via sigmoid cross-entropy:
$$
\begin{align}
L^t_{\mbox{vote}} &= \texttt{MLP}_{\texttt{vote}}(L^t)\\
y^t &= \mbox{mean}(L^t_{\mbox{vote}})
\end{align}
$$
---
# Training and Inference
## Training Set
The training set is built such that for any satisfiable training formula $S$, it also includes an unsatisfiable counterpart $S'$ which differs from $S$ ***only by negating one litteral in one clause***. These carefully curated samples should constrain the model to pick up substantial characteristics of the formula. In practice, the model is trained on formulas containing up to ***40 variables***, and on average ***200 clauses***. At this size, the SAT problem can still be solved by state-of-the-art solvers (yielding the supervision) but are large enough they prove challenging for Machine Learning models.
## Inferring the SAT assignment
When a formula is satisfiable, one often also wants to know a ***valuation*** (variable assignment) that satisfies it.
Recall that $L^t_{\mbox{vote}}$ encodes a "vote" for every litteral and its negative counterpart. Qualitative experiments show that thoses scores cannot be directly used for inferring the variable assignment, however they do induce a nice clustering of the variables (once the message passing has converged). Hence an assignment can be found as follows:
* (1) Reshape $L^T_{\mbox{vote}}$ to size $(n, 2)$ where $n$ is the number of litterals.
* (2) Cluster the litterals into two clusters with centers $\Delta_1$ and $\Delta_2$ using the following criterion:
\begin{align}
\|x_i - \Delta_1\|^2 + \|\overline{x_i} - \Delta_2\|^2 \leq \|x_i - \Delta_2\|^2 + \|\overline{x_i} - \Delta_1\|^2
\end{align}
* (3) Try the two resulting assignments (set $\Delta_1$ to true and $\Delta_2$ to false, or vice-versa) and choose the one that yields satisfiability if any.
In practice, this method retrieves a satistifiability assignment for over 70% of the satisfiable test formulas.
---
# Experiments
In practice, the ***NeuroSAT*** model is trained with embeddings of dimension 128 and 26 message passing iterations using standard MLPs: 3 layers followed by ReLU activations. The final model obtains 85% accuracy in predicting a formula's satisfiability on the test set.
It also can generalize to ***larger problems***, requiring to increase the number of message passing iterations, although the classification performance decreases as the problem size grows (e.g. 25% for 200 variables).
Interestingly, the model also generalizes well to other classes of problems that were first ***reduced to SAT***, although they have different structure than the random formulas generated for training, which seems to show that the model does learn some general structural characteristics of Boolean formulas.
|

Data Augmentation for Skin Lesion Analysis
Fábio Perez and Cristina Vasconcelos and Sandra Avila and Eduardo Valle
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/09/05 (5 years ago)
Abstract: Deep learning models show remarkable results in automated skin lesion analysis. However, these models demand considerable amounts of data, while the availability of annotated skin lesion images is often limited. Data augmentation can expand the training dataset by transforming input images. In this work, we investigate the impact of 13 data augmentation scenarios for melanoma classification trained on three CNNs (Inception-v4, ResNet, and DenseNet). Scenarios include traditional color and geometric transforms, and more unusual augmentations such as elastic transforms, random erasing and a novel augmentation that mixes different lesions. We also explore the use of data augmentation at test-time and the impact of data augmentation on various dataset sizes. Our results confirm the importance of data augmentation in both training and testing and show that it can lead to more performance gains than obtaining new images. The best scenario results in an AUC of 0.882 for melanoma classification without using external data, outperforming the top-ranked submission (0.874) for the ISIC Challenge 2017, which was trained with additional data.
more
less
Fábio Perez and Cristina Vasconcelos and Sandra Avila and Eduardo Valle
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/09/05 (5 years ago)
Abstract: Deep learning models show remarkable results in automated skin lesion analysis. However, these models demand considerable amounts of data, while the availability of annotated skin lesion images is often limited. Data augmentation can expand the training dataset by transforming input images. In this work, we investigate the impact of 13 data augmentation scenarios for melanoma classification trained on three CNNs (Inception-v4, ResNet, and DenseNet). Scenarios include traditional color and geometric transforms, and more unusual augmentations such as elastic transforms, random erasing and a novel augmentation that mixes different lesions. We also explore the use of data augmentation at test-time and the impact of data augmentation on various dataset sizes. Our results confirm the importance of data augmentation in both training and testing and show that it can lead to more performance gains than obtaining new images. The best scenario results in an AUC of 0.882 for melanoma classification without using external data, outperforming the top-ranked submission (0.874) for the ISIC Challenge 2017, which was trained with additional data.
|
[link]
_Disclaimer: I'm the first author of this paper._ The code for this paper can be found at https://github.com/fabioperez/skin-data-augmentation. In this work, we wanted to compare different data augmentation scenarios for skin lesion analysis. We tried 13 scenarios, including commonly used augmentation techniques (color and geometry transformations), unusual ones (random erasing, elastic transformation, and a novel lesion mix to simulate collision lesions), and a combination of those. Examples of the augmentation scenarios: https://i.imgur.com/TpgxzLZ.png a) no augmentation b) color (saturation, contrast, and brightness) c) color (saturation, contrast, brightness, and hue) d) affine (rotation, shear, scaling) e) random flips f) random crops g) random erasing h) elastic i) lesion mix j) basic set (f, d, e, c) k) basic set + erasing (f, g, d, e, c) l) basic set + elastic (f, d, h, e, c) m) basic set + mix (i, f, d, e, c) --- We used the ISIC 2017 Challenge dataset (2000 training images, 150 validation images, and 600 test images). We tried three network architectures: Inception-v4, ResNet-152, and DenseNet-161. We also compared different test-time data augmentation methods: a) no augmentation; b) 144-crops; c) same data augmentation as training (64 augmented copies of the original image). Final prediction was the average of all augmented predictions. ## Results https://i.imgur.com/WK5VKUf.png * Basic set (combination of commonly used augmentations) is the best scenario. * Data augmentation at test-time is very beneficial. * Elastic is better than no augmentation, but when compared incorporated to the basic set, decreases the performance. * The best result was better than the winner of the challenge in 2017, without using ensembling. * Test data augmentation is very similar with 144-crop, but takes less images during prediction (64 vs 144), so it's faster. # Impact of data augmentation on dataset sizes We also used the basic set scenarios on different dataset sizes by sampling random subsets of the original dataset, with sizes 1500, 1000, 500, 250 and 125. https://i.imgur.com/m3Ut6ht.png ## Results * Using data augmentation can be better than using more data (but you should always use more data since the model can benefit from both). For instance, using 500 images with data augmentation on training and test for Inception is better than training with no data augmentation with 2000 images. * ResNet and DenseNet works better than Inception for less data. * Test-time data augmentation is always better than not augmenting on test-time. * Using data augmentation on train only was worse than not augmenting at all in some cases. |

Investigating Human Priors for Playing Video Games
Rachit Dubey and Pulkit Agrawal and Deepak Pathak and Thomas L. Griffiths and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG
First published: 2018/02/28 (6 years ago)
Abstract: What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors on human performance. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play. Videos and the game manipulations are available at https://rach0012.github.io/humanRL_website/
more
less
Rachit Dubey and Pulkit Agrawal and Deepak Pathak and Thomas L. Griffiths and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG
First published: 2018/02/28 (6 years ago)
Abstract: What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors on human performance. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play. Videos and the game manipulations are available at https://rach0012.github.io/humanRL_website/
|
[link]
Authors investigated why humans play some video games better than machines. That is the case for games that do not have continuous rewards (e.g., scores). They experimented with a game -- inspired by _Montezuma's Revenge_ -- in which the player has to climb stairs, collect keys and jump over enemies. RL algorithms can only know if they succeed if they finish the game, as there is no rewards during the gameplay, so they tend to do much worse than humans in these games. To compare between humans and machines, they set up RL algorithms and recruite players from Amazon Mechanical Turk. Humans did much better than machines for the original game setup. However, authors wanted to check the impact of semantics and prior knowledge on humans performance. They set up scenarios with different levels of reduced semantic information, as shown in Figure 2. https://i.imgur.com/e0Dq1WO.png This is what the game originally looked like: https://rach0012.github.io/humanRL_website/main.gif And this is the version with lesser semantic clues: https://rach0012.github.io/humanRL_website/random2.gif You can try yourself in the [paper's website](https://rach0012.github.io/humanRL_website/). Not surprisingly, humans took much more time to complete the game in scenarios with less semantic information, indicating that humans strongly rely on prior knowledge to play video games. The authors argue that this prior knowledge should also be somehow included into RL algorithms in order to move their efficiency towards the human level. ## Additional reading [Why humans learn faster than AI—for now](https://www.technologyreview.com/s/610434/why-humans-learn-faster-than-ai-for-now/). [OpenReview submission](https://openreview.net/forum?id=Hk91SGWR-) |
Neural Ordinary Differential Equations
Ricky T. Q. Chen and Yulia Rubanova and Jesse Bettencourt and David Duvenaud
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/06/19 (6 years ago)
Abstract: We introduce a new family of deep neural network models. Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network. The output of the network is computed using a black-box differential equation solver. These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed. We demonstrate these properties in continuous-depth residual networks and continuous-time latent variable models. We also construct continuous normalizing flows, a generative model that can train by maximum likelihood, without partitioning or ordering the data dimensions. For training, we show how to scalably backpropagate through any ODE solver, without access to its internal operations. This allows end-to-end training of ODEs within larger models.
more
less
Ricky T. Q. Chen and Yulia Rubanova and Jesse Bettencourt and David Duvenaud
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/06/19 (6 years ago)
Abstract: We introduce a new family of deep neural network models. Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network. The output of the network is computed using a black-box differential equation solver. These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed. We demonstrate these properties in continuous-depth residual networks and continuous-time latent variable models. We also construct continuous normalizing flows, a generative model that can train by maximum likelihood, without partitioning or ordering the data dimensions. For training, we show how to scalably backpropagate through any ODE solver, without access to its internal operations. This allows end-to-end training of ODEs within larger models.
|
[link]
Summary by senior author [duvenaud on hackernews](https://news.ycombinator.com/item?id=18678078).
A few years ago, everyone switched their deep nets to "residual nets". Instead of building deep models like this:
h1 = f1(x)
h2 = f2(h1)
h3 = f3(h2)
h4 = f3(h3)
y = f5(h4)
They now build them like this:
h1 = f1(x) + x
h2 = f2(h1) + h1
h3 = f3(h2) + h2
h4 = f4(h3) + h3
y = f5(h4) + h4
Where f1, f2, etc are neural net layers. The idea is that it's easier to model a small change to an almost-correct answer than to output the whole improved answer at once.
In the last couple of years a few different groups noticed that this looks like a primitive ODE solver (Euler's method) that solves the trajectory of a system by just taking small steps in the direction of the system dynamics and adding them up. They used this connection to propose things like better training methods.
We just took this idea to its logical extreme: What if we _define_ a deep net as a continuously evolving system? So instead of updating the hidden units layer by layer, we define their derivative with respect to depth instead. We call this an ODE net.
Now, we can use off-the-shelf adaptive ODE solvers to compute the final state of these dynamics, and call that the output of the neural network. This has drawbacks (it's slower to train) but lots of advantages too: We can loosen the numerical tolerance of the solver to make our nets faster at test time. We can also handle continuous-time models a lot more naturally. It turns out that there is also a simpler version of the change of variables formula (for density modeling) when you move to continuous time.
|

Do Deep Generative Models Know What They Don't Know?
Eric Nalisnick and Akihiro Matsukawa and Yee Whye Teh and Dilan Gorur and Balaji Lakshminarayanan
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/22 (5 years ago)
Abstract: A neural network deployed in the wild may be asked to make predictions for inputs that were drawn from a different distribution than that of the training data. A plethora of work has demonstrated that it is easy to find or synthesize inputs for which a neural network is highly confident yet wrong. Generative models are widely viewed to be robust to such mistaken confidence as modeling the density of the input features can be used to detect novel, out-of-distribution inputs. In this paper we challenge this assumption. We find that the density learned by flow-based models, VAEs, and PixelCNNs cannot distinguish images of common objects such as dogs, trucks, and horses (i.e. CIFAR-10) from those of house numbers (i.e. SVHN), assigning a higher likelihood to the latter when the model is trained on the former. Moreover, we find evidence of this phenomenon when pairing several popular image data sets: FashionMNIST vs MNIST, CelebA vs SVHN, ImageNet vs CIFAR-10 / CIFAR-100 / SVHN. To investigate this curious behavior, we focus analysis on flow-based generative models in particular since they are trained and evaluated via the exact marginal likelihood. We find such behavior persists even when we restrict the flow models to constant-volume transformations. These transformations admit some theoretical analysis, and we show that the difference in likelihoods can be explained by the location and variances of the data and the model curvature. Our results caution against using the density estimates from deep generative models to identify inputs similar to the training distribution until their behavior for out-of-distribution inputs is better understood.
more
less
Eric Nalisnick and Akihiro Matsukawa and Yee Whye Teh and Dilan Gorur and Balaji Lakshminarayanan
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/10/22 (5 years ago)
Abstract: A neural network deployed in the wild may be asked to make predictions for inputs that were drawn from a different distribution than that of the training data. A plethora of work has demonstrated that it is easy to find or synthesize inputs for which a neural network is highly confident yet wrong. Generative models are widely viewed to be robust to such mistaken confidence as modeling the density of the input features can be used to detect novel, out-of-distribution inputs. In this paper we challenge this assumption. We find that the density learned by flow-based models, VAEs, and PixelCNNs cannot distinguish images of common objects such as dogs, trucks, and horses (i.e. CIFAR-10) from those of house numbers (i.e. SVHN), assigning a higher likelihood to the latter when the model is trained on the former. Moreover, we find evidence of this phenomenon when pairing several popular image data sets: FashionMNIST vs MNIST, CelebA vs SVHN, ImageNet vs CIFAR-10 / CIFAR-100 / SVHN. To investigate this curious behavior, we focus analysis on flow-based generative models in particular since they are trained and evaluated via the exact marginal likelihood. We find such behavior persists even when we restrict the flow models to constant-volume transformations. These transformations admit some theoretical analysis, and we show that the difference in likelihoods can be explained by the location and variances of the data and the model curvature. Our results caution against using the density estimates from deep generative models to identify inputs similar to the training distribution until their behavior for out-of-distribution inputs is better understood.
|
[link]
CNNs predictions are known to be very sensitive to adversarial examples, which are samples generated to be wrongly classifiied with high confidence. On the other hand, probabilistic generative models such as `PixelCNN` and `VAEs` learn a distribution over the input domain hence could be used to detect ***out-of-distribution inputs***, e.g., by estimating their likelihood under the data distribution. This paper provides interesting results showing that distributions learned by generative models are not robust enough yet to employ them in this way.
* **Pros (+):** convincing experiments on multiple generative models, more detailed analysis in the invertible flow case, interesting negative results.
* **Cons (-):** It would be interesting to provide further results for different datasets / domain shifts to observe if this property can be quanitfied as a characteristics of the model or of the input data.
---
## Experimental negative result
Three classes of generative models are considered in this paper:
* **Auto-regressive** models such as `PixelCNN` [1]
* **Latent variable** models, such as `VAEs` [2]
* Generative models with **invertible flows** [3], in particular `Glow` [4].
The authors train a generative model $G$ on input data $\mathcal X$ and then use it to evaluate the likelihood on both the training domain $\mathcal X$ and a different domain $\tilde{\mathcal X}$. Their main (negative) result is showing that **a model trained on the CIFAR-10 dataset yields a higher likelihood when evaluated on the SVHN test dataset than on the CIFAR-10 test (or even train) split**. Interestingly, the converse, when training on SVHN and evaluating on CIFAR, is not true.
This result was consistantly observed for various architectures including [1], [2] and [4], although it is of lesser effect in the `PixelCNN` case.
Intuitively, this could come from the fact that both of these datasets contain natural images and that CIFAR-10 is strictly more diverse than SVHN in terms of semantic content. Nonetheless, these datasets vastly differ in appearance, and this result is counter-intuitive as it goes against the direction that generative models can reliably be use to detect out-of-distribution samples. Furthermore, this observation also confirms the general idea that higher likelihoods does not necessarily coincide with better generated samples [5].
---
## Further analysis for invertible flow models
The authors further study this phenomenon in the invertible flow models case as they provide a more rigorous analytical framework (exact likelihood inference unlike VAE which only provide a bound on the true likelihood).
More specifically invertible flow models are characterized with a ***diffeomorphism*** (invertible function), $f(x; \phi)$, between input space $\mathcal X$ and latent space $\mathcal Z$, and choice of the latent distribution $p(z; \psi)$. The ***change of variable formula*** links the density of $x$ and $z$ as follows:
$$
\int_x p_x(x)d_x = \int_x p_z(f(x)) \left| \frac{\partial f}{\partial x} \right| dx
$$
And the training objective under this transformation becomes
$$
\arg\max_{\theta} \log p_x(\mathbf{x}; \theta) = \arg\max_{\phi, \psi} \sum_i \log p_z(f(x_i; \phi); \psi) + \log \left| \frac{\partial f_{\phi}}{\partial x_i} \right|
$$
Typically, $p_z$ is chosen to be Gaussian, and samples are build by inverting $f$, i.e.,$z \sim p(\mathbf z),\ x = f^{-1}(z)$. And $f_{\phi}$ is build such that computing the log determinant of the Jacabian in the previous equation can be done efficiently.
First, they observe that contribution of the flow can be decomposed in a ***density*** element (left term) and a ***volume*** element (right term), resulting from the change of variables formula. Experiment results with Glow [4] show that the higher density on SVHN mostly comes from the ***volume element contribution***.
Secondly, they try to directly analyze the difference in likelihood between two domains $\mathcal X$ and $\tilde{\mathcal X}$; which can be done by a second-order expansion of the log-likelihood locally around the expectation of the distribution (assuming $\mathbb{E} (\mathcal X) \sim \mathbb{E}(\tilde{\mathcal X})$). For the constant volume Glow module, the resulting analytical formula indeed confirms that the log-likelihood of SVHN should be higher than CIFAR's, as observed in practice.
---
## References
* [1] Conditional Image Generation with PixelCNN Decoders, van den Oord et al, 2016
* [2] Auto-Encoding Variational Bayes, Kingma and Welling, 2013
* [3] Density estimation using Real NVP, Dinh et al., ICLR 2015
* [4] Glow: Generative Flow with Invertible 1x1 Convolutions, Kingma and Dhariwal
* [5] A Note on the Evaluation of Generative Models, Theis et al., ICLR 2016
|
Learning Confidence for Out-of-Distribution Detection in Neural Networks
Terrance DeVries and Graham W. Taylor
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/02/13 (6 years ago)
Abstract: Modern neural networks are very powerful predictive models, but they are often incapable of recognizing when their predictions may be wrong. Closely related to this is the task of out-of-distribution detection, where a network must determine whether or not an input is outside of the set on which it is expected to safely perform. To jointly address these issues, we propose a method of learning confidence estimates for neural networks that is simple to implement and produces intuitively interpretable outputs. We demonstrate that on the task of out-of-distribution detection, our technique surpasses recently proposed techniques which construct confidence based on the network's output distribution, without requiring any additional labels or access to out-of-distribution examples. Additionally, we address the problem of calibrating out-of-distribution detectors, where we demonstrate that misclassified in-distribution examples can be used as a proxy for out-of-distribution examples.
more
less
Terrance DeVries and Graham W. Taylor
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/02/13 (6 years ago)
Abstract: Modern neural networks are very powerful predictive models, but they are often incapable of recognizing when their predictions may be wrong. Closely related to this is the task of out-of-distribution detection, where a network must determine whether or not an input is outside of the set on which it is expected to safely perform. To jointly address these issues, we propose a method of learning confidence estimates for neural networks that is simple to implement and produces intuitively interpretable outputs. We demonstrate that on the task of out-of-distribution detection, our technique surpasses recently proposed techniques which construct confidence based on the network's output distribution, without requiring any additional labels or access to out-of-distribution examples. Additionally, we address the problem of calibrating out-of-distribution detectors, where we demonstrate that misclassified in-distribution examples can be used as a proxy for out-of-distribution examples.
|
[link]
## Summary
In a prior work 'On Calibration of Modern Nueral Networks', temperature scailing is used for outputing confidence. This is done at inference stage, and does not change the existing classifier. This paper considers the confidence at training stage, and directly outputs the confidence from the network.
## Architecture
An additional branch for confidence is added after the penultimate layer, in parallel to logits and probs (Figure 2).
https://i.imgur.com/vtKq9g0.png
## Training
The network outputs the prob $p$ and the confidence $c$ which is a single scalar. The modified prob $p'=c*p+(1-c)y$ where $y$ is the label (hint). The confidence loss is $\mathcal{L}_c=-\log c$, the NLL is $\mathcal{L}_t= -\sum \log(p'_i)y_i$.
### Budget Parameter
The authors introduced the confidence loss weight $\lambda$ and a budget $\beta$. If $\mathcal{L}_c>\beta$, increase $\lambda$, if $\mathcal{L}_c<\beta$, decrease $\lambda$. $\beta$ is found reasonable in [0.1,1.0].
### Hinting with 50%
Sometimes the model relies on the free label ($c=0$) and does not fit the complicated structure of data. The authors give hints with 50% so the model cannot rely 100% on the hint. They used $p'$ for only half of the bathes for each epoch.
### Misclassified Examples
A high-capacity network with small dataset overfits well, and mis-classified samples are required to learn the confidence. The network likely assigns low confidence to samples. The paper used an aggressive data augmentation to create difficult examples.
## Inference
Reject if $c\le\delta$.
For out-of-distribution detection, they used the same input perturbation as in ODIN (2018). ODIN used temperature scailing and used the max prob, while this paper does not need temperature scailing since it directly outputs $c$. In evaluation, this paper outperformed ODIN.
## Reference
ODIN: [Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks](http://www.shortscience.org/paper?bibtexKey=journals/corr/1706.02690#elbaro)
|

Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning
Supasorn Suwajanakorn and Noah Snavely and Jonathan Tompson and Mohammad Norouzi
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/07/05 (6 years ago)
Abstract: This paper presents KeypointNet, an end-to-end geometric reasoning framework to learn an optimal set of category-specific 3D keypoints, along with their detectors. Given a single image, KeypointNet extracts 3D keypoints that are optimized for a downstream task. We demonstrate this framework on 3D pose estimation by proposing a differentiable objective that seeks the optimal set of keypoints for recovering the relative pose between two views of an object. Our model discovers geometrically and semantically consistent keypoints across viewing angles and instances of an object category. Importantly, we find that our end-to-end framework using no ground-truth keypoint annotations outperforms a fully supervised baseline using the same neural network architecture on the task of pose estimation. The discovered 3D keypoints on the car, chair, and plane categories of ShapeNet are visualized at http://keypointnet.github.io/.
more
less
Supasorn Suwajanakorn and Noah Snavely and Jonathan Tompson and Mohammad Norouzi
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/07/05 (6 years ago)
Abstract: This paper presents KeypointNet, an end-to-end geometric reasoning framework to learn an optimal set of category-specific 3D keypoints, along with their detectors. Given a single image, KeypointNet extracts 3D keypoints that are optimized for a downstream task. We demonstrate this framework on 3D pose estimation by proposing a differentiable objective that seeks the optimal set of keypoints for recovering the relative pose between two views of an object. Our model discovers geometrically and semantically consistent keypoints across viewing angles and instances of an object category. Importantly, we find that our end-to-end framework using no ground-truth keypoint annotations outperforms a fully supervised baseline using the same neural network architecture on the task of pose estimation. The discovered 3D keypoints on the car, chair, and plane categories of ShapeNet are visualized at http://keypointnet.github.io/.
|
[link]
What the paper is about: KeypointNet learns the optimal set of 3D keypoints and their 2D detectors for a specified downstream task. The authors demonstrate this by extracting 3D keypoints and their 2D detectors for the task of relative pose estimation across views. They show that, using keypoints extracted by KeypointNet, relative pose estimates are superior to ones that are obtained from a supervised set of keypoints. Approach: Training samples for KeypointNet comprise two views (images) of an object. The task is to then produce an ordered list of 3D keypoints that, upon orthogonal procrustes alignment, produce the true relative 3D pose across those views. The network has N heads, each of which extracts one (3D) keypoint (from a 2D image). There are two primary loss terms. A multi-view consistency loss measures the discrepancy between the two sets of extracted keypoints under the ground-truth transform. A relative-pose estimation loss penalizes the angular discrepency (under orthogonal procrustes) of the estimated transform using the extracted keypoints vs the GT transform. Additionally, they require keypoints to be distant from each other, and to lie within the object silhouette. |

Learning Latent Dynamics for Planning from Pixels
Danijar Hafner and Timothy Lillicrap and Ian Fischer and Ruben Villegas and David Ha and Honglak Lee and James Davidson
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/11/12 (5 years ago)
Abstract: Planning has been very successful for control tasks with known environment dynamics. To leverage planning in unknown environments, the agent needs to learn the dynamics from interactions with the world. However, learning dynamics models that are accurate enough for planning has been a long-standing challenge, especially in image-based domains. We propose the Deep Planning Network (PlaNet), a purely model-based agent that learns the environment dynamics from pixels and chooses actions through online planning in latent space. To achieve high performance, the dynamics model must accurately predict the rewards ahead for multiple time steps. We approach this problem using a latent dynamics model with both deterministic and stochastic transition function and a generalized variational inference objective that we name latent overshooting. Using only pixel observations, our agent solves continuous control tasks with contact dynamics, partial observability, and sparse rewards. PlaNet uses significantly fewer episodes and reaches final performance close to and sometimes higher than top model-free algorithms.
more
less
Danijar Hafner and Timothy Lillicrap and Ian Fischer and Ruben Villegas and David Ha and Honglak Lee and James Davidson
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/11/12 (5 years ago)
Abstract: Planning has been very successful for control tasks with known environment dynamics. To leverage planning in unknown environments, the agent needs to learn the dynamics from interactions with the world. However, learning dynamics models that are accurate enough for planning has been a long-standing challenge, especially in image-based domains. We propose the Deep Planning Network (PlaNet), a purely model-based agent that learns the environment dynamics from pixels and chooses actions through online planning in latent space. To achieve high performance, the dynamics model must accurately predict the rewards ahead for multiple time steps. We approach this problem using a latent dynamics model with both deterministic and stochastic transition function and a generalized variational inference objective that we name latent overshooting. Using only pixel observations, our agent solves continuous control tasks with contact dynamics, partial observability, and sparse rewards. PlaNet uses significantly fewer episodes and reaches final performance close to and sometimes higher than top model-free algorithms.
|
[link]
**Summary**: This paper presents three tricks that make model-based reinforcement more reliable when tested in tasks that require walking and balancing. The tricks are 1) are planning based on features, 2) using a recursive network that mixes probabilistic and deterministic information, and 3) looking forward multiple steps. **Longer summary** Imagine playing pool, armed with a tablet that can predict exactly where the ball will bounce, and the next bounce, and so on. That would be a huge advantage to someone learning pool, however small inaccuracies in the model could mislead you especially when thinking ahead to the 2nd and third bounce. The tablet is analogous to the dynamics model in model-based reinforcement learning (RL). Model based RL promises to solve a lot of the open problems with RL, letting the agent learn with less experience, transfer well, dream, and many others advantages. Despite the promise, dynamics models are hard to get working: they often suffer from even small inaccuracies, and need to be redesigned for specific tasks. Enter PlaNet, a clever name, and a net that plans well in range of environments. To increase the challenge the model must predict directly from pixels in fairly difficult tasks such as teaching a cheetah to run or balancing a ball in a cup. How do they do this? Three main tricks. - Planning in latest space: this means that the policy network doesn't need to look at the raw image, but looks at a summary of it as represented by a feature vector. - Recurrent state space models: They found that probabilistic information helps describe the space of possibilities but makes it harder for their RNN based model to look back multiple steps. However mixing probabilistic information and deterministic information gives it the best of both worlds, and they have results that show a starting performance increase when both compared to just one. - Latent overshooting: They train the model to look more than one step ahead, this helps prevent errors that build up over time Overall this paper shows great results that tackle the shortfalls of model based RL. I hope the results remain when tested on different and more complex environments. |
Gradient Reversal Against Discrimination
Edward Raff and Jared Sylvester
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG
First published: 2018/07/01 (6 years ago)
Abstract: No methods currently exist for making arbitrary neural networks fair. In this work we introduce GRAD, a new and simplified method to producing fair neural networks that can be used for auto-encoding fair representations or directly with predictive networks. It is easy to implement and add to existing architectures, has only one (insensitive) hyper-parameter, and provides improved individual and group fairness. We use the flexibility of GRAD to demonstrate multi-attribute protection.
more
less
Edward Raff and Jared Sylvester
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG
First published: 2018/07/01 (6 years ago)
Abstract: No methods currently exist for making arbitrary neural networks fair. In this work we introduce GRAD, a new and simplified method to producing fair neural networks that can be used for auto-encoding fair representations or directly with predictive networks. It is easy to implement and add to existing architectures, has only one (insensitive) hyper-parameter, and provides improved individual and group fairness. We use the flexibility of GRAD to demonstrate multi-attribute protection.
|
[link]
Given some input data $x$ and attribute $a_p$, the task is to predict label $y$ from $x$ while making $a_p$ *protected*, in other words, such that the model predictions are invariant to changes in $a_p$.
* **Pros (+)**: Simple and intuitive idea, easy to train, naturally extended to protecting multiple attributes.
* **Cons (-)**: Comparison to baselines could be more detailed / comprehensive, in particular the comparison to ALFR [4] which also relies on adversarial training.
---
## Proposed Method
**Domain adversarial networks.**
The proposed model builds on the *Domain Adversarial Network* [1], originally introduced for unsupervised domain adaptation. Given some labeled data $(x, y) \sim \mathcal X
\times \mathcal Y$, and some unlabeled data $\tilde x \sim \tilde{\mathcal X}$, the goal is to learn a network that solves both classification tasks $\mathcal X \rightarrow \mathcal Y$ and $\tilde{\mathcal X} \rightarrow \mathcal Y$ while learning a shared representation between $\mathcal X$ and $\tilde{\mathcal X}$.
The model is composed of a feature extractor $G_f$ which then branches off into a *target* branch, $G_t$, to predict the target label, and a *domain* branch, $G_d$, predicting whether the input data comes either from domain $\mathcal X$ or $\tilde{\mathcal X}$. The model parameters are trained with the following objective:
$$
\begin{align}
(\theta_{G_f}, \theta_{G_t} ) &= \arg\min \mathbb E_{(x, y) \sim \mathcal X \times \mathcal Y}\ \ell_t \left( G_t \circ G_f(x), y \right)\\
\theta_{G_d} &= \arg\max \mathbb E_{x \sim \mathcal X} \ \ell_d\left( G_d \circ G_f(x), 1 \right) + \mathbb E_{\tilde x \sim \tilde{\mathcal X}}\ \ell_d \left(G_d \circ G_f(\tilde x), 0\right)\\
\mbox{where } &\ell_t \mbox{ and } \ell_d \mbox{ are classification losses}
\end{align}
$$
The gradient updates for this saddle point problem can be efficiently implemented using the Gradient Reversal Layer introduced in [1]
**GRAD-pred.** In **G**radient **R**eversal **A**gainst **D**iscrimination, samples come only from one domain $\mathcal X$, and the domain classifier $G_d$ is replaced by an *attribute* classifier, $G_p$, whose goal is to predict the value of the protected attribute $a_p$.
In other words, the training objective strives to build a feature representation of $x$ that is good enough to predict the correct label $y$ but such that $a_p$ cannot easily be deduced from it.
On the contrary, directly learning classification network $G_y \circ G_f$ penalized when predicting the correct value of attribute $a_p$ could instead lead to a model that learns $a_p$ and trivially outputs an incorrect value. This situation is prevented by the adversarial training scheme here.
**GRAD-auto.** The authors also consider a variant of the described model where the target branch $G_t$ instead solves the auto-encoding/reconstruction task. The features learned by the encoder $G_f$ can then later be used as entry point of a smaller network for classification or any other task.
---
## Experiments
**Evaluation metrics.** The model is evaluated on four metrics to qualify both accuracy and fairness, following the protocol in [2]:
* *Accuracy*, the proportion of correct classifications
* *Discrimination*, the average score differences (logits of the ground-truth class) between samples with $a_p = + 1$ and $a_p = -1 $ (assuming a binary attribute)
* *Consistency*, the average difference between a sample score and the mean of its nearest neighbors' score.
* *Delta = Accuracy - Discrimination*, a penalized version of accuracy
**Baselines.**
* **Vanilla** CNN trained without the protected attribute protection branch
* **LFR** [2]: A classifier with an intermediate latent code $Z \in \{1 \dots K\}$ is trained with an objective that combines a classification loss (the model should accurately classify $x$), a reconstruction loss (the learned representation should encode enough information about the input to reconstruct it accurately) and a parity loss (estimate the probability $P(Z=z | x)$ for both populations with $a_p = 1$ and $a_p = -1$ and strive to make them equal)
* **VFA** [3]: A VAE where the protected attribute $a_p$ is factorized out of the latent code $z$, and additional invariance is imposed via a MMD objective which tries to match the moments of the posterior distributions $q(z|a_p = -1)$ and $q(z| a_p = 1)$.
* **ALFR** [4] : As in LFR, this paper proposes a model trained with a reconstruction loss and a classification loss. Additionally, they propose to quantify the dependence between the learned representation and the protected attribute by adding an adversary classifier that tries to extract the attribute value from the representation, formulated and trained as in the Generative Adversarial Network (GAN) setting.
**Results.** GRAD always reaches highest consistency compared to baselines. For the other metrics, the results are more mitigated, although it usually achieves best or second best results. It's also not clear how to choose between GRAD-pred and GRAD-auto as there does not seem to be a clear winner, although GRAD-pred seems more intuitive when supervision is available, as it directly solves the classification task.
Authors also report a small experiment showing that protecting several attributes at the same time can be more beneficial than protecting a single attribute. This can be expected as some attributes are highly correlated or interact in meaningful way.
In particular, protecting several attributes at once can easily be done in the GRAD framework by making the attribute prediction branch multi-class for instance: however it is not clear in the paper how it is actually done in practice, nor whether the same idea could also be integrated in the baselines for further comparison.
---
## References
* [1] Domain-Adversarial Training of Neural Networks, Ganin et al, JMRL 2016
* [2] Learning Fair Representations, Zemel et al, ICML 2013
* [3] The Variational Fair Autoencoder, Louizos et al, 2016
* [4] Censoring Representations with an Adversary, Edwards and Storkey, ICLR 2016
|
BSN: Boundary Sensitive Network for Temporal Action Proposal Generation
Tianwei Lin and Xu Zhao and Haisheng Su and Chongjing Wang and Ming Yang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/06/08 (6 years ago)
Abstract: Temporal action proposal generation is an important yet challenging problem, since temporal proposals with rich action content are indispensable for analysing real-world videos with long duration and high proportion irrelevant content. This problem requires methods not only generating proposals with precise temporal boundaries, but also retrieving proposals to cover truth action instances with high recall and high overlap using relatively fewer proposals. To address these difficulties, we introduce an effective proposal generation method, named Boundary-Sensitive Network (BSN), which adopts "local to global" fashion. Locally, BSN first locates temporal boundaries with high probabilities, then directly combines these boundaries as proposals. Globally, with Boundary-Sensitive Proposal feature, BSN retrieves proposals by evaluating the confidence of whether a proposal contains an action within its region. We conduct experiments on two challenging datasets: ActivityNet-1.3 and THUMOS14, where BSN outperforms other state-of-the-art temporal action proposal generation methods with high recall and high temporal precision. Finally, further experiments demonstrate that by combining existing action classifiers, our method significantly improves the state-of-the-art temporal action detection performance.
more
less
Tianwei Lin and Xu Zhao and Haisheng Su and Chongjing Wang and Ming Yang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/06/08 (6 years ago)
Abstract: Temporal action proposal generation is an important yet challenging problem, since temporal proposals with rich action content are indispensable for analysing real-world videos with long duration and high proportion irrelevant content. This problem requires methods not only generating proposals with precise temporal boundaries, but also retrieving proposals to cover truth action instances with high recall and high overlap using relatively fewer proposals. To address these difficulties, we introduce an effective proposal generation method, named Boundary-Sensitive Network (BSN), which adopts "local to global" fashion. Locally, BSN first locates temporal boundaries with high probabilities, then directly combines these boundaries as proposals. Globally, with Boundary-Sensitive Proposal feature, BSN retrieves proposals by evaluating the confidence of whether a proposal contains an action within its region. We conduct experiments on two challenging datasets: ActivityNet-1.3 and THUMOS14, where BSN outperforms other state-of-the-art temporal action proposal generation methods with high recall and high temporal precision. Finally, further experiments demonstrate that by combining existing action classifiers, our method significantly improves the state-of-the-art temporal action detection performance.
|
[link]
## Boundary sensitive network
### **keyword**: action detection in video; accurate proposal
**Summary**: In order to generate precise temporal boundaries and improve recall with lesses proposals, Tianwei Lin et al use BSN which first combine temporal boundaries with high probability to form proposals and then select proposals by evaluating whether a proposal contains an action(confidence score+ boundary probability).
**Model**:
1. video feature encoding: use the two-stream extractor to form the input of BSN. $F = \{f_{tn}\}_{n=1}^{l_s} = \{(f_{S,Tn}, f_{T,t_n}\}_{n=1}^{l_s)} $
2. BSN:
* temporal evaluation: input feature sequence, using 3-layer CNN+3 fiter with sigmoid, to generate start, end, and actioness probability
* proposal generation: 1.combine bound with high start/end probability or if probility peak to form proposal; 2. use actioness probability to generate proposal feature for each proposal by sampling the actioness probability during proposal region.
* proposal evaluation: using 1 hidden layer perceptron to evaluate confidence score based on proposal features.
proposal $\varphi =(t_s,t_e,p_{conf},p_{t_s}^s,p_{t_e}^e) $ $p_{t_e}^e$ is the end probability,and $p_{conf}$ is confidence score
https://i.imgur.com/VjJLQDc.png
**Training**:
* **Learn to generate probility curve**:
In order to calculate the accuracy of proposals the loss in the temporal evaluation is calculated as following:
$L_{TEM} = \lambda L^{action} + L ^{start} + L^{end}$;
$L = \frac{1}{l_w} \sum_{i =1}^{l_w}(\frac{l_w}{l_w-\sum_i g_i} b_i*log(p_i)+\frac{l_w}{\sum_i g_i} (1-b_i)*log(1-p_i))$
$ b_i = sign(g_i-\theta_{IoP})$
Thus, if start region proposal is highly overlapped with ground truth, the start point probability should increase to lower the loss, after training, the information of ground truth region could be leveraged to predict the accurate probability for start. actions and end probability could apply the same rule.
* **Learn to choose right proposal**:
In order to choose the right proposal based on confidence score, push confidence score to match with IOU of the groud truth and proposal is important. So the loss to do this is described as follow:
$L_p = \frac{1}{N_{train}} \sum_{i=1}^{N_{train}} (p_{conf,i}-g_{iou,i})^2$. $N_{train}$ is number of training proposals and among it the ratio of positive to negative proposal is 1:2.$g_{iou,i}$ is the ith proposal's overlap with its corresponding ground truth.
During test and prediction, the final confidence is calculated to fetch and suppress proposals using gaussian decaying soft-NMS. and final confidence score for each proposal is $p_f = p_{conf}p_{ts}^sp_{te}^e$
Thus, after training, the confidence score should reveal the iou between the proposal and its corresponding ground truth based on the proposal feature which is generated through actionness probability, whereas final proposal is achieved by ranking final confidence score.
**Conclusion**: Different with segment proposal or use RNN to decide where to look next, this paper generate proposals with boundary probability and select them using the confidence score-- the IOU between the proposal and corresponding ground truth. with sufficient data, it can provide right bound probability and confidence score. and the highlight of the paper is it can be very accurate within feature sequence.
*However, it only samples part of the video for feature sequence. so it is possible it will jump over the boundary point. if an accurate policy to decide where to sample is used, accuracy should be further boosted. *
* **computation complexity**: within this network, computation includes
1. two-stream feature extractor for video samples
2. probility generation module: 3-layers cnn for the generated sequence
3. proposal generation using combination
4. sampler to generate proposal feature
5. 1-hidden layer perceptron to generate confidence score.
major computing complexity should attribute to feature extractor(1') and proposal relate module if lots of proposals are generated(3',4')
**Performance**: when combined with SCNN-classifier, it reach map@0.5 = 36.9 on THUMOS14 dataset
|

Relational Forward Models for Multi-Agent Learning
Andrea Tacchetti and H. Francis Song and Pedro A. M. Mediano and Vinicius Zambaldi and Neil C. Rabinowitz and Thore Graepel and Matthew Botvinick and Peter W. Battaglia
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.MA, stat.ML
First published: 2018/09/28 (5 years ago)
Abstract: The behavioral dynamics of multi-agent systems have a rich and orderly structure, which can be leveraged to understand these systems, and to improve how artificial agents learn to operate in them. Here we introduce Relational Forward Models (RFM) for multi-agent learning, networks that can learn to make accurate predictions of agents' future behavior in multi-agent environments. Because these models operate on the discrete entities and relations present in the environment, they produce interpretable intermediate representations which offer insights into what drives agents' behavior, and what events mediate the intensity and valence of social interactions. Furthermore, we show that embedding RFM modules inside agents results in faster learning systems compared to non-augmented baselines. As more and more of the autonomous systems we develop and interact with become multi-agent in nature, developing richer analysis tools for characterizing how and why agents make decisions is increasingly necessary. Moreover, developing artificial agents that quickly and safely learn to coordinate with one another, and with humans in shared environments, is crucial.
more
less
Andrea Tacchetti and H. Francis Song and Pedro A. M. Mediano and Vinicius Zambaldi and Neil C. Rabinowitz and Thore Graepel and Matthew Botvinick and Peter W. Battaglia
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.MA, stat.ML
First published: 2018/09/28 (5 years ago)
Abstract: The behavioral dynamics of multi-agent systems have a rich and orderly structure, which can be leveraged to understand these systems, and to improve how artificial agents learn to operate in them. Here we introduce Relational Forward Models (RFM) for multi-agent learning, networks that can learn to make accurate predictions of agents' future behavior in multi-agent environments. Because these models operate on the discrete entities and relations present in the environment, they produce interpretable intermediate representations which offer insights into what drives agents' behavior, and what events mediate the intensity and valence of social interactions. Furthermore, we show that embedding RFM modules inside agents results in faster learning systems compared to non-augmented baselines. As more and more of the autonomous systems we develop and interact with become multi-agent in nature, developing richer analysis tools for characterizing how and why agents make decisions is increasingly necessary. Moreover, developing artificial agents that quickly and safely learn to coordinate with one another, and with humans in shared environments, is crucial.
|
[link]
One of the dominant narratives of the deep learning renaissance has been the value of well-designed inductive bias - structural choices that shape what a model learns. The biggest example of this can be found in convolutional networks, where models achieve a dramatic parameter reduction by having features maps learn local patterns, which can then be re-used across the whole image. This is based on the prior belief that patterns in local images are generally locally contiguous, and so having feature maps that focus only on small (and gradually larger) local areas is a good fit for that prior. This paper operates in a similar spirit, except its input data isn’t in the form of an image, but a graph: the social graph of multiple agents operating within a Multi Agent RL Setting. In some sense, a graph is just a more general form of a pixel image: where a pixel within an image has a fixed number of neighbors, which have fixed discrete relationships to it (up, down, left, right), nodes within graphs have an arbitrary number of nodes, which can have arbitrary numbers and types of attributes attached to that relationship. The authors of this paper use graph networks as a sort of auxiliary information processing system alongside a more typical policy learning framework, on tasks that require group coordination and knowledge sharing to complete successfully. For example, each agent might be rewarded based on the aggregate reward of all agents together, and, in the stag hunt, it might require collaborative effort by multiple agents to successfully “capture” a reward. Because of this, you might imagine that it would be valuable to be able to predict what other agents within the game are going to do under certain circumstances, so that you can shape your strategy accordingly. The graph network used in this model represents both agents and objects in the environment as nodes, which have attributes including their position, whether they’re available or not (for capture-able objects), and what their last action was. As best I can tell, all agents start out with directed connections going both ways to all other agents, and to all objects in the environment, with the only edge attribute being whether the players are on the same team, for competitive environments. Given this setup, the graph network works through a sort of “diffusion” of information, analogous to a message passing algorithm. At each iteration (analogous to a layer), the edge features pull in information from their past value and sender and receiver nodes, as well as from a “global feature”. Then, all of the nodes pull in information from their edges, and their own past value. Finally, this “global attribute” gets updated based on summations over the newly-updated node and edge information. (If you were predicting attributes that were graph-level attributes, this global attribute might be where you’d do that prediction. However, in this case, we’re just interested in predicting agent-level actions). https://i.imgur.com/luFlhfJ.png All of this has the effect of explicitly modeling agents as entities that both have information, and have connections to other entities. One benefit the authors claim of this structure is that it allows them more interpretability: when they “play out” the values of their graph network, which they call a Relational Forward Model or RFM, they observe edge values for two agents go up if those agents are about to collaborate on an action, and observe edge values for an agent and an object go up before that object is captured. Because this information is carefully shaped and structured, it makes it easier for humans to understand, and, in the tests the authors ran, appears to also help agents do better in collaborative games. https://i.imgur.com/BCKSmIb.png While I find graph networks quite interesting, and multi-agent learning quite interesting, I’m a little more uncertain about the inherent “graphiness” of this problem, since there aren’t really meaningful inherent edges between agents. One thing I am curious about here is how methods like these would work in situations of sparser graphs, or, places where the connectivity level between a node’s neighbors, and the average other node in the graph is more distinct. Here, every node is connected to every other node, so the explicit information localization function of graph networks is less pronounced. I might naively think that - to whatever extent the graph is designed in a way that captures information meaningful to the task - explicit graph methods would have an even greater comparative advantage in this setting. |
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search
Lars Buesing and Theophane Weber and Yori Zwols and Sebastien Racaniere and Arthur Guez and Jean-Baptiste Lespiau and Nicolas Heess
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/11/15 (5 years ago)
Abstract: Learning policies on data synthesized by models can in principle quench the thirst of reinforcement learning algorithms for large amounts of real experience, which is often costly to acquire. However, simulating plausible experience de novo is a hard problem for many complex environments, often resulting in biases for model-based policy evaluation and search. Instead of de novo synthesis of data, here we assume logged, real experience and model alternative outcomes of this experience under counterfactual actions, actions that were not actually taken. Based on this, we propose the Counterfactually-Guided Policy Search (CF-GPS) algorithm for learning policies in POMDPs from off-policy experience. It leverages structural causal models for counterfactual evaluation of arbitrary policies on individual off-policy episodes. CF-GPS can improve on vanilla model-based RL algorithms by making use of available logged data to de-bias model predictions. In contrast to off-policy algorithms based on Importance Sampling which re-weight data, CF-GPS leverages a model to explicitly consider alternative outcomes, allowing the algorithm to make better use of experience data. We find empirically that these advantages translate into improved policy evaluation and search results on a non-trivial grid-world task. Finally, we show that CF-GPS generalizes the previously proposed Guided Policy Search and that reparameterization-based algorithms such Stochastic Value Gradient can be interpreted as counterfactual methods.
more
less
Lars Buesing and Theophane Weber and Yori Zwols and Sebastien Racaniere and Arthur Guez and Jean-Baptiste Lespiau and Nicolas Heess
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/11/15 (5 years ago)
Abstract: Learning policies on data synthesized by models can in principle quench the thirst of reinforcement learning algorithms for large amounts of real experience, which is often costly to acquire. However, simulating plausible experience de novo is a hard problem for many complex environments, often resulting in biases for model-based policy evaluation and search. Instead of de novo synthesis of data, here we assume logged, real experience and model alternative outcomes of this experience under counterfactual actions, actions that were not actually taken. Based on this, we propose the Counterfactually-Guided Policy Search (CF-GPS) algorithm for learning policies in POMDPs from off-policy experience. It leverages structural causal models for counterfactual evaluation of arbitrary policies on individual off-policy episodes. CF-GPS can improve on vanilla model-based RL algorithms by making use of available logged data to de-bias model predictions. In contrast to off-policy algorithms based on Importance Sampling which re-weight data, CF-GPS leverages a model to explicitly consider alternative outcomes, allowing the algorithm to make better use of experience data. We find empirically that these advantages translate into improved policy evaluation and search results on a non-trivial grid-world task. Finally, we show that CF-GPS generalizes the previously proposed Guided Policy Search and that reparameterization-based algorithms such Stochastic Value Gradient can be interpreted as counterfactual methods.
|
[link]
It is a fact universally acknowledged that a reinforcement learning algorithm not in possession of a model must be in want of more data. Because they generally are. Joking aside, it is broadly understood that model-free RL takes a lot of data to train, and, even when you can design them to use off-policy trajectories, collecting data in the real environment might still be too costly. Under those conditions, we might want to learn a model of the environment and generate synthesized trajectories, and train on those. This has the advantage of not needing us to run the actual environment, but the obvious disadvantage that any model will be a simplification of the true environment, and potentially an inaccurate one. These authors seek to answer the question of: “is there a way to generate trajectories that has higher fidelity to the true environment.” As you might infer from the fact that they published a paper, and that I’m now writing about it, they argue that, yes, there is, and it’s through explicit causal/counterfactual modeling. Causal modeling is one of those areas of statistics that seems straightforward at its highest level of abstraction, but tends to get mathematically messy and unintuitive when you dive into the math. So, rather than starting with equations, I’m going to try to verbally give some intuitions for the way causal modeling is framed here. Imagine you’re trying to understand what would happen if a person had gone to college. There’s some set of information you know about them, and some set of information you don’t, that’s just random true facts about them and about the universe. If, in the real world, they did go to college, and you want to simulate what would have happened if they didn’t, it’s not enough to just know the observed facts about them, you want to actually isolate all of the random other facts (about them, about the world) that weren’t specifically “the choice to go to college”, and condition on those as well. Obviously, in the example given here, it isn’t really practically possible to isolate all the specific unseen factors that influence someone’s outcome. But, conceptually, this quantity, is what we’re going to focus on in this paper. Now, imagine a situation where a RL agent has been dropped into a maze-like puzzle. It has some set of dynamics, not immediately visible to the player, that make it difficult, but ultimately solvable. The best kind of simulated data, the paper argues, would be to keep that state of the world (which is partially unobservable) fixed, and sample different sets of actions the agent might take in that space. Thus, “counterfactual modeling”: for a given configuration of random states in the world, sampling different actions within it. To do this, you first have to infer the random state the agent is experiencing. In the normal model-based case, you’d have some prior over world states, and just sample from it. However, if you use the experience of the agent’s trajectory, you can make a better guess as to what world configuration it was dropped into. If you can do this, which is, technically speaking, sampling from the posterior over unseen context, conditional on an agent’s experience, then the paper suggests you’ll be able to generate data that’s more realistic, because the trajectories will be direct counterfactuals of “real world” scenarios, rather than potentially-unsolvable or unrealistic draws from the prior. This is, essentially, the approach proposed by the paper: during training, they make this “world state” visible to the agent, and let it learn a model predicting what state it started with, given some trajectory of experience. They also learn a model that predicts the outcome and ultimately the value of actions taken, conditioned on this random context (as well as visible context, and the agent’s prior actions). They start out by using this as a tool for policy evaluation, which is a nice problem setup because you can actually check how well you’re doing against some baseline: if you want to know how good your simulated data is at replicating the policy reward on real data, you can just try it out on real data and see. The authors find that they reduce policy reward estimation error pretty substantially by adding steps of experience (in Bayesian terms, bit of evidence moving them from the prior, towards the posterior). https://i.imgur.com/sNAcGjZ.png They also experiment with using this for actual policy search, but, honestly, I didn’t quite follow the intuitions behind Guided Policy Search, so I’m just going to not dive into that for now, since I think a lot of the key contributions of the paper are wrapped up in the idea of “estimate the reward of a policy by simulating data from a counterfactual trajectory” |
Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference
Matthew Riemer and Ignacio Cases and Robert Ajemian and Miao Liu and Irina Rish and Yuhai Tu and Gerald Tesauro
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/10/29 (5 years ago)
Abstract: Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.
more
less
Matthew Riemer and Ignacio Cases and Robert Ajemian and Miao Liu and Irina Rish and Yuhai Tu and Gerald Tesauro
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/10/29 (5 years ago)
Abstract: Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.
|
[link]
Catastrophic forgetting is the tendency of an neural network to forget previously learned information when learning new information. This paper combats that by keeping a buffer of experience and applying meta-learning to it. They call their new module Meta Experience Replay or MER. How does this work? At each update they compute multiple possible updates to the model weights. One for the new batch of information and some more updates for batches of previous experience. Then they apply meta-learning using the REPTILE algorithm, here the meta-model sees each possible update and has to predict the output which combines them with the least interference. This is done by predicting an update vector that maximizes the dot product between the new and old update vectors, that way it transfers as much learning as possible from the new update without interfering with the old updates. https://i.imgur.com/TG4mZOn.png Does it work? Yes, while it may take longer to train, the results show that it generalizes better and needs a much smaller buffer of experience than the popular approach of using replay buffers. |
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
Rosanne Liu and Joel Lehman and Piero Molino and Felipe Petroski Such and Eric Frank and Alex Sergeev and Jason Yosinski
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/07/09 (6 years ago)
Abstract: Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. In this paper we show a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, we show that they fail spectacularly. We demonstrate and carefully analyze the failure first on a toy problem, at which point a simple fix becomes obvious. We call this solution CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels. Without sacrificing the computational and parametric efficiency of ordinary convolution, CoordConv allows networks to learn either perfect translation invariance or varying degrees of translation dependence, as required by the task. CoordConv solves the coordinate transform problem with perfect generalization and 150 times faster with 10--100 times fewer parameters than convolution. This stark contrast raises the question: to what extent has this inability of convolution persisted insidiously inside other tasks, subtly hampering performance from within? A complete answer to this question will require further investigation, but we show preliminary evidence that swapping convolution for CoordConv can improve models on a diverse set of tasks. Using CoordConv in a GAN produced less mode collapse as the transform between high-level spatial latents and pixels becomes easier to learn. A Faster R-CNN detection model trained on MNIST detection showed 24% better IOU when using CoordConv, and in the RL domain agents playing Atari games benefit significantly from the use of CoordConv layers.
more
less
Rosanne Liu and Joel Lehman and Piero Molino and Felipe Petroski Such and Eric Frank and Alex Sergeev and Jason Yosinski
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, stat.ML
First published: 2018/07/09 (6 years ago)
Abstract: Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. In this paper we show a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, we show that they fail spectacularly. We demonstrate and carefully analyze the failure first on a toy problem, at which point a simple fix becomes obvious. We call this solution CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels. Without sacrificing the computational and parametric efficiency of ordinary convolution, CoordConv allows networks to learn either perfect translation invariance or varying degrees of translation dependence, as required by the task. CoordConv solves the coordinate transform problem with perfect generalization and 150 times faster with 10--100 times fewer parameters than convolution. This stark contrast raises the question: to what extent has this inability of convolution persisted insidiously inside other tasks, subtly hampering performance from within? A complete answer to this question will require further investigation, but we show preliminary evidence that swapping convolution for CoordConv can improve models on a diverse set of tasks. Using CoordConv in a GAN produced less mode collapse as the transform between high-level spatial latents and pixels becomes easier to learn. A Faster R-CNN detection model trained on MNIST detection showed 24% better IOU when using CoordConv, and in the RL domain agents playing Atari games benefit significantly from the use of CoordConv layers.
|
[link]
This is a paper where I keep being torn between the response of “this is so simple it’s brilliant; why haven’t people done it before,” and “this is so simple it’s almost tautological, and the results I’m seeing aren’t actually that surprising”. The basic observation this paper makes is one made frequently before, most recently to my memory by Geoff Hinton in his Capsule Net paper: sometimes the translation invariance of convolutional networks can be a bad thing, and lead to worse performance. In a lot of ways, translation invariance is one of the benefits of using a convolutional architecture in the first place: instead of having to learn separate feature detectors for “a frog in this corner” and “a frog in that corner,” we can instead use the same feature detector, and just move it over different areas of the image. However, this paper argues, this makes convolutional networks perform worse than might naively be expected at tasks that require them to remember or act in accordance with coordinates of elements within an image. For example, they find that normal convolutional networks take nearly an hour and 200K worth of parameters to learn to “predict” the one-hot encoding of a pixel, when given the (x,y) coordinates of that pixel as input, and only get up to about 80% accuracy. Similarly, trying to take an input image with only one pixel active, and predict the (x,y) coordinates as output, is something the network is able to do successfully, but only when the test points are sampled from the same spatial region as the training points: if the test points are from a held-out quadrant, the model can’t extrapolate to the (x, y) coordinates there, and totally falls apart. https://i.imgur.com/x6phN4p.png The solution proposed by the authors is a really simple one: at one or more layers within the network, in addition to the feature channels sent up from the prior layer, add two addition channels: one with a with deterministic values going from -1 (left) to 1 (right), and the other going top to bottom. This essentially adds two fixed “features” to each pixel, which jointly carry information about where it is in space. Just by adding this small change, we give the network the ability to use spatial information or not, as it sees fit. If these features don’t prove useful, their weights will stay around their initialization values of expectation-zero, and the behavior should be much like a normal convolutional net. However, if it proves useful, convolution filters at the next layer can take position information into account. It’s easy to see how this would be useful for this paper’s toy problems: you can just create a feature detector for “if this pixel is active, pass forward information about it’s spatial position,” and predict the (x, y) coordinates out easily. You can also imagine this capability helping with more typical image classification problems, by having feature filters that carry with them not only content information, but information about where a pattern was found spatially. The authors do indeed find comparable performance or small benefits to ImageNet, MNIST, and Atari RL, when applying their layers in lieu of normal convolutional layer. On GANs in particular, they find less mode collapse, though I don’t yet 100% follow the intuition of why this would be the case. https://i.imgur.com/wu7wQZr.png |
Adversarial Reprogramming of Neural Networks
Gamaleldin F. Elsayed and Ian Goodfellow and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, cs.CV, stat.ML
First published: 2018/06/28 (6 years ago)
Abstract: Deep neural networks are susceptible to adversarial attacks. In computer vision, well-crafted perturbations to images can cause neural networks to make mistakes such as identifying a panda as a gibbon or confusing a cat with a computer. Previous adversarial examples have been designed to degrade performance of models or cause machine learning models to produce specific outputs chosen ahead of time by the attacker. We introduce adversarial attacks that instead reprogram the target model to perform a task chosen by the attacker---without the attacker needing to specify or compute the desired output for each test-time input. This attack is accomplished by optimizing for a single adversarial perturbation, of unrestricted magnitude, that can be added to all test-time inputs to a machine learning model in order to cause the model to perform a task chosen by the adversary when processing these inputs---even if the model was not trained to do this task. These perturbations can be thus considered a program for the new task. We demonstrate adversarial reprogramming on six ImageNet classification models, repurposing these models to perform a counting task, as well as two classification tasks: classification of MNIST and CIFAR-10 examples presented within the input to the ImageNet model.
more
less
Gamaleldin F. Elsayed and Ian Goodfellow and Jascha Sohl-Dickstein
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, cs.CV, stat.ML
First published: 2018/06/28 (6 years ago)
Abstract: Deep neural networks are susceptible to adversarial attacks. In computer vision, well-crafted perturbations to images can cause neural networks to make mistakes such as identifying a panda as a gibbon or confusing a cat with a computer. Previous adversarial examples have been designed to degrade performance of models or cause machine learning models to produce specific outputs chosen ahead of time by the attacker. We introduce adversarial attacks that instead reprogram the target model to perform a task chosen by the attacker---without the attacker needing to specify or compute the desired output for each test-time input. This attack is accomplished by optimizing for a single adversarial perturbation, of unrestricted magnitude, that can be added to all test-time inputs to a machine learning model in order to cause the model to perform a task chosen by the adversary when processing these inputs---even if the model was not trained to do this task. These perturbations can be thus considered a program for the new task. We demonstrate adversarial reprogramming on six ImageNet classification models, repurposing these models to perform a counting task, as well as two classification tasks: classification of MNIST and CIFAR-10 examples presented within the input to the ImageNet model.
|
[link]
In the literature of adversarial examples, there’s this (to me) constant question: is it the case that adversarial examples are causing the model to objectively make a mistake, or just displaying behavior that is deeply weird, and unintuitive relative to our sense of what these models “should” be doing. A lot of the former question seems to come down to arguing over about what’s technically “out of distribution”, which has an occasional angels-dancing-on-a-pin quality, but it’s pretty unambiguously clear that the behavior displayed in this paper is weird, and beyond what I naively expected a network to be able to be manipulated to do. The goal these authors set for themselves is what they call “reprogramming” of a network; they want the ability to essentially hijack the network’s computational engine to perform a different task, predicting a different set of labels, on a different set of inputs than the ones the model was trained on. For example, one task they perform is feeding in MNIST images at the center of a bunch of (what appear to be random, but are actually carefully optimized) pixels, and getting a network that can predict MNIST labels out the other end. Obviously, it’s not literally possible to change the number of outputs that a network produces once it’s trained, so the authors would arbitrarily map ImageNet outputs to MNIST categories (like, “when this model predicts Husky, that actually means the digit 7”) and then judge how well this mapped output performs as a MNIST classifier. I enjoyed the authors’ wry commentary here about the arbitrariness of the mapping, remarking that “a ‘White Shark’ has nothing to do with counting 3 squares in an image, and an ‘Ostrich’ does not at all resemble 10 squares”. https://i.imgur.com/K02cwK0.png This paper assumes a white box attack model, which implies visibility of all of the parameters, and ability to directly calculate gradients through the model. So, given this setup of a input surrounded by modifiable pixel weights, and a desire to assign your “MNIST Labels” correctly, this becomes a straightforward optimization problem: modify the values of your input weights so as to maximize your MNIST accuracy. An important point to note here is that the same input mask of pixel values is applied for every new-task image, and so these values are optimized over a full training set of inserted images, the way that normal weights would be. One interesting observation the authors make is that, counter to the typical setup of adversarial examples, this attack would not work with a fully linear model, since you actually need your “weights” to interact with your “input”, which is different each time, but these are both just different areas of your true input. This need to have different regions of input determine how other areas of input are processed isn’t possible in a linear model where each input has a distinct impact on the output, regardless of other input values. By contrast, when you just need to optimize a single perturbation to get the network to jack up the prediction for one class, that can be accomplished by just applying a strong enough bias everywhere in the input, all pointing in the same direction, which can be added together linearly and still get the job done. The authors are able to perform MNIST and the task of “count the squares in this small input” to relatively high levels of accuracy. They perform reasonably on CIFAR (as well as a fully connected network, but not as well as a convnet). They found that performance was higher when using a pre-trained ImageNet, relative to just random weights. There’s some suggestion made that this implies there’s a kind of transfer learning going on, but honestly, this is weird enough that it’s hard to say. https://i.imgur.com/bj2MUnk.png They were able to get this reprogramming work on different model structures, but, fascinatingly, saw distinctive patterns to the "weight pixels" they needed to add to each model structure, with ResNet easily differentiable from Inception. One minor quibble I have with the framing of this paper - which I overall found impressive, creative, and well-written - is that I feel like it’s stretching the original frame of “adversarial example” a bit too far, to the point of possible provoking confusion. It’s not obvious that the network is making a mistake, per se, when it classifies this very out-of-distribution input as something silly. I suppose, in an ideal world, we may want our models to return to something like a uniform-over-outputs state of low confidence when predicting out of distribution, but that’s a bit different than seeing a gibbon in a picture of a panda. I don’t dispute the authors claim that the behavior they’re demonstrating is a vulnerability in terms of its ability to let outside actors “hijack” networks compute, but I worry we might be overloading the “adversarial example” to cover too many types of network failure modes. |
Learning Plannable Representations with Causal InfoGAN
Thanard Kurutach and Aviv Tamar and Ge Yang and Stuart Russell and Pieter Abbeel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.NE, cs.RO, stat.ML
First published: 2018/07/24 (6 years ago)
Abstract: In recent years, deep generative models have been shown to 'imagine' convincing high-dimensional observations such as images, audio, and even video, learning directly from raw data. In this work, we ask how to imagine goal-directed visual plans -- a plausible sequence of observations that transition a dynamical system from its current configuration to a desired goal state, which can later be used as a reference trajectory for control. We focus on systems with high-dimensional observations, such as images, and propose an approach that naturally combines representation learning and planning. Our framework learns a generative model of sequential observations, where the generative process is induced by a transition in a low-dimensional planning model, and an additional noise. By maximizing the mutual information between the generated observations and the transition in the planning model, we obtain a low-dimensional representation that best explains the causal nature of the data. We structure the planning model to be compatible with efficient planning algorithms, and we propose several such models based on either discrete or continuous states. Finally, to generate a visual plan, we project the current and goal observations onto their respective states in the planning model, plan a trajectory, and then use the generative model to transform the trajectory to a sequence of observations. We demonstrate our method on imagining plausible visual plans of rope manipulation.
more
less
Thanard Kurutach and Aviv Tamar and Ge Yang and Stuart Russell and Pieter Abbeel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.NE, cs.RO, stat.ML
First published: 2018/07/24 (6 years ago)
Abstract: In recent years, deep generative models have been shown to 'imagine' convincing high-dimensional observations such as images, audio, and even video, learning directly from raw data. In this work, we ask how to imagine goal-directed visual plans -- a plausible sequence of observations that transition a dynamical system from its current configuration to a desired goal state, which can later be used as a reference trajectory for control. We focus on systems with high-dimensional observations, such as images, and propose an approach that naturally combines representation learning and planning. Our framework learns a generative model of sequential observations, where the generative process is induced by a transition in a low-dimensional planning model, and an additional noise. By maximizing the mutual information between the generated observations and the transition in the planning model, we obtain a low-dimensional representation that best explains the causal nature of the data. We structure the planning model to be compatible with efficient planning algorithms, and we propose several such models based on either discrete or continuous states. Finally, to generate a visual plan, we project the current and goal observations onto their respective states in the planning model, plan a trajectory, and then use the generative model to transform the trajectory to a sequence of observations. We demonstrate our method on imagining plausible visual plans of rope manipulation.
|
[link]
This paper tries to solve the problem of how to learn systems that, given a starting state and a desired target, can earn the set of actions necessary to reach that target. The strong version of this problem requires a planning algorithm to learn a full set of actions to take the agent from state A to B. However, this is a difficult and complex task, and so this paper tries to address a relaxed version of this task: generating a set of “waypoint” observations between A and B, such that each successive observation is relatively close to one another in terms of possible actions (the paper calls this ‘h-reachable’, if observations are reachable from one another in h timesteps). With these checkpoint observations in hand, the planning system can them solve many iterations of a much shorter-time-scale version of the problem. However, the paper asserts, applying pre-designed planning algorithms in observation space (sparse, high-dimensional) is difficult, because planning algorithms apparently do better with denser representations. (I don’t really understand, based on just reading this paper, *why* this is the case, other than the general fact that high dimensional, sparse data is just hard for most things). Historically, a typical workflow for applying planning algorithms to an environment would have been to hand-design feature representations where nearby representations were close in causal decision space (i.e. could be easily reached from one another). This paper’s goal is to derive such representations from data, rather than hand-designing them. The system they design to do this is a little unwieldy to follow, and I only have about 80% confidence that I fully understand all the mechanisms. One basic way you might compress high-dimensional space into a low-dimensional code is by training a Variational Autoencoder, and pulling the latent code out of the bottleneck in the middle. However, we also want to be able to map between our low-dimensional code and a realistic observation space, once we’re done planning and have our trajectory of codes, and VAE typically have difficulty generating high-dimensional observations with high fidelity. If what you want is image-generation fidelity, the natural step would be to use a GAN. However, GANs aren’t really natively designed to learn an informative representation; their main goal is generation, and there’s no real incentive for the noise variables used to seed generation to encode any useful information. One GAN design that tries to get around this is the InfoGAN, which gets its name from the requirement that there be high mutual information between (some subset of) the noise variables used to seed the generator, and the actual observation produced. I’m not going to get into the math of the variational approximation, but what this actually mechanically shakes out to is: in addition to generating an observation from a code, an InfoGAN also tries to predict the original code subset given the observation. Intuitively, this requirement, for the observation to contain information about the code, also means the code is forced to contain meaningful information about the image generated from it. However, even with this system, even if each code separately corresponds to a realistic observation, there’s no guarantee that closeness in state space corresponds to closeness in “causality space”. This feature is valuable for planning, because it means that if you chart out a trajectory through state space, it actually corresponds to a reasonable trajectory through observation space. In order to solve this problem, the authors added their final, and more novel, modification to the InfoGAN framework: instead of giving the GAN one latent code, and having it predict one observation, they would give two at a time, and have the GAN try to generate a pair of temporally nearby (i.e. less than h actions away) observations. Importantly, they’d also define some transition or sampling function within state space, so that there would be a structured or predictable way that adjacent pairs of states looked. So, if the GAN were able to learn to map adjacent points in state space to adjacent points in observation space, then you’d be able to plan out trajectories in state space, and have them be realistic in observation space. https://i.imgur.com/oVlVc0x.png They do some experiments and do show that both adding the “Info” structure of the InfoGAN, and adding the paired causal structure, lead to states with improved planning properties.They also compared the clusters derived from their Causal InfoGAN states to the clusters you’d get from just naively assuming that nearness in observation space meant nearness in causality space. https://i.imgur.com/ddQpIdH.png They specifically tested this on an environment divided into two “rooms”, where there were many places where there were two points, nearby in Euclidean space, but far away (or mutually inaccessible) in action space. They showed that the Causal InfoGAN (b) was successfully able to learn representations such that points nearby in action space clustered together, whereas a Euclidean representation (c) didn't have this property. |
Intrinsic Social Motivation via Causal Influence in Multi-Agent RL
Natasha Jaques and Angeliki Lazaridou and Edward Hughes and Caglar Gulcehre and Pedro A. Ortega and DJ Strouse and Joel Z. Leibo and Nando de Freitas
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.MA, stat.ML
First published: 2018/10/19 (5 years ago)
Abstract: We derive a new intrinsic social motivation for multi-agent reinforcement learning (MARL), in which agents are rewarded for having causal influence over another agent's actions. Causal influence is assessed using counterfactual reasoning. The reward does not depend on observing another agent's reward function, and is thus a more realistic approach to MARL than taken in previous work. We show that the causal influence reward is related to maximizing the mutual information between agents' actions. We test the approach in challenging social dilemma environments, where it consistently leads to enhanced cooperation between agents and higher collective reward. Moreover, we find that rewarding influence can lead agents to develop emergent communication protocols. We therefore employ influence to train agents to use an explicit communication channel, and find that it leads to more effective communication and higher collective reward. Finally, we show that influence can be computed by equipping each agent with an internal model that predicts the actions of other agents. This allows the social influence reward to be computed without the use of a centralised controller, and as such represents a significantly more general and scalable inductive bias for MARL with independent agents.
more
less
Natasha Jaques and Angeliki Lazaridou and Edward Hughes and Caglar Gulcehre and Pedro A. Ortega and DJ Strouse and Joel Z. Leibo and Nando de Freitas
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.MA, stat.ML
First published: 2018/10/19 (5 years ago)
Abstract: We derive a new intrinsic social motivation for multi-agent reinforcement learning (MARL), in which agents are rewarded for having causal influence over another agent's actions. Causal influence is assessed using counterfactual reasoning. The reward does not depend on observing another agent's reward function, and is thus a more realistic approach to MARL than taken in previous work. We show that the causal influence reward is related to maximizing the mutual information between agents' actions. We test the approach in challenging social dilemma environments, where it consistently leads to enhanced cooperation between agents and higher collective reward. Moreover, we find that rewarding influence can lead agents to develop emergent communication protocols. We therefore employ influence to train agents to use an explicit communication channel, and find that it leads to more effective communication and higher collective reward. Finally, we show that influence can be computed by equipping each agent with an internal model that predicts the actions of other agents. This allows the social influence reward to be computed without the use of a centralised controller, and as such represents a significantly more general and scalable inductive bias for MARL with independent agents.
|
[link]
This paper builds very directly on the idea of “empowerment” as an intrinsic reward for RL agents. Where empowerment incentivizes agents to increase the amount of influence they’re able to have over the environment, “social influence,” this paper’s metric, is based on the degree which the actions of one agent influence the actions of other agents, within a multi-agent setting. The goals between the two frameworks are a little different. The notion of “empowerment” is built around a singular agent trying to figure out a short-term proxy for likelihood of long-term survival (which is a feedback point no individual wants to hit). By contrast, the problems that the authors of this paper seek to solve are more explicitly multi-agent coordination problems: prisoner’s dilemma-style situations where collective reward requires cooperation. However, they share a mathematical basis: the idea that an agent’s influence on some other element of its environment (be it the external state, or another agent’s actions) is well modeled by calculating the mutual information between its agents and that element. While this is initially a bit of an odd conceptual jump, it does make sense: if an action can give statistical information to help you predict an outcome, it’s likely (obviously not certain, but likely) that that action influenced that outcome. In a multi-agent problem, where cooperation and potentially even communication can help solve the task, being able to influence other agents amounts to “finding ways to make oneself useful to other agents”, because other agents aren’t going to change behavior based on your actions, or “listen” to your “messages” (in the experiment where a communication channel was available between agents) if these signals don’t help them achieve *their* goals. So, this incentive, to influence the behavior of other (self-interested) agents, amounts to a good proxy for incentivizing useful cooperation. Zooming in on the exact mathematical formulations (which differ slightly from, though they’re in a shared spirit with, the empowerment math): the agent’s (A’s) Causal Influence reward is calculated by taking a KL divergence between the action distribution of the other agent (B) conditional on the action A took, compared to other actions A might have taken. (see below. Connecting back to empowerment: Mutual Information is just the expected value of this quantity, taken over A’s action distribution). https://i.imgur.com/oxXCbdK.png One thing you may notice from the above equation is that, because we’re working in KL divergences, we expect agent A to have access to the full distribution of agent B’s policy conditional on A’s action, not just the action B actually took. We also require the ability to sample “counterfactuals,” i.e. what agent B would have done if agent A had done something differently. Between these two requirements. If we take a realistic model of two agents interacting with each other, in only one timeline, only having access to the external and not internal parameters of the other, it makes it clear that these quantities can’t be pulled from direct experience. Instead, they are calculated by using an internal model: each agent builds its own MOA (Model of Other Agents), where they build a predictive model of what an agent will do at a given time, conditional on the environment and the actions of all other agents. It’s this model that is used to sample the aforementioned counterfactuals, since that just involves passing in a different input. I’m not entirely sure, in each experiment, whether the MOAs are trained concurrent with agent policies, or in a separate prior step. https://i.imgur.com/dn2cBg4.png Testing on, again, Prisoner’s Dilemma style problems requiring agents to take risky collaborative actions, the authors did find higher performance using their method, compared to approaches where each agent just maximizes its own external reward (which, it should be said, does depend on other agents’ actions), with no explicit incentive towards collaboration. Interestingly, when they specifically tested giving agents access to a “communication channel” (the ability to output discrete signals or “words” visible to other agents), they found that it was able to train just as effectively with only an influence reward, as it was with both an influence and external reward. |
Natural Environment Benchmarks for Reinforcement Learning
Amy Zhang and Yuxin Wu and Joelle Pineau
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/11/14 (5 years ago)
Abstract: While current benchmark reinforcement learning (RL) tasks have been useful to drive progress in the field, they are in many ways poor substitutes for learning with real-world data. By testing increasingly complex RL algorithms on low-complexity simulation environments, we often end up with brittle RL policies that generalize poorly beyond the very specific domain. To combat this, we propose three new families of benchmark RL domains that contain some of the complexity of the natural world, while still supporting fast and extensive data acquisition. The proposed domains also permit a characterization of generalization through fair train/test separation, and easy comparison and replication of results. Through this work, we challenge the RL research community to develop more robust algorithms that meet high standards of evaluation.
more
less
Amy Zhang and Yuxin Wu and Joelle Pineau
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/11/14 (5 years ago)
Abstract: While current benchmark reinforcement learning (RL) tasks have been useful to drive progress in the field, they are in many ways poor substitutes for learning with real-world data. By testing increasingly complex RL algorithms on low-complexity simulation environments, we often end up with brittle RL policies that generalize poorly beyond the very specific domain. To combat this, we propose three new families of benchmark RL domains that contain some of the complexity of the natural world, while still supporting fast and extensive data acquisition. The proposed domains also permit a characterization of generalization through fair train/test separation, and easy comparison and replication of results. Through this work, we challenge the RL research community to develop more robust algorithms that meet high standards of evaluation.
|
[link]
This paper proposed three new reinforcement learning tasks which involved dealing with images. - Task 1: An agent crawls across a hidden image, revealing portions of it at each step. It must classify the image in the minimum amount of steps. For example classify the image as a cat after choosing to travel across the ears. - Task 2: The agent crawls across a visible image to sit on it's target. For example a cat in a scene of pets. - Task 3: The agent plays an Atari game where the background has been replaced with a distracting video. These tasks are easy to construct, but solving them requires large scale visual processing or attention, which typically require deep networks. To address these new tasks, popular RL agents (PPO, A2C, and ACKTR) were augmented with a deep image processing network (ResNet-18), but they still performed poorly. |
Reward learning from human preferences and demonstrations in Atari
Borja Ibarz and Jan Leike and Tobias Pohlen and Geoffrey Irving and Shane Legg and Dario Amodei
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.NE, stat.ML
First published: 2018/11/15 (5 years ago)
Abstract: To solve complex real-world problems with reinforcement learning, we cannot rely on manually specified reward functions. Instead, we can have humans communicate an objective to the agent directly. In this work, we combine two approaches to learning from human feedback: expert demonstrations and trajectory preferences. We train a deep neural network to model the reward function and use its predicted reward to train an DQN-based deep reinforcement learning agent on 9 Atari games. Our approach beats the imitation learning baseline in 7 games and achieves strictly superhuman performance on 2 games without using game rewards. Additionally, we investigate the goodness of fit of the reward model, present some reward hacking problems, and study the effects of noise in the human labels.
more
less
Borja Ibarz and Jan Leike and Tobias Pohlen and Geoffrey Irving and Shane Legg and Dario Amodei
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.NE, stat.ML
First published: 2018/11/15 (5 years ago)
Abstract: To solve complex real-world problems with reinforcement learning, we cannot rely on manually specified reward functions. Instead, we can have humans communicate an objective to the agent directly. In this work, we combine two approaches to learning from human feedback: expert demonstrations and trajectory preferences. We train a deep neural network to model the reward function and use its predicted reward to train an DQN-based deep reinforcement learning agent on 9 Atari games. Our approach beats the imitation learning baseline in 7 games and achieves strictly superhuman performance on 2 games without using game rewards. Additionally, we investigate the goodness of fit of the reward model, present some reward hacking problems, and study the effects of noise in the human labels.
|
[link]
How can humans help an agent perform at a task that has no clear reward? Imitation, demonstration, and preferences. This paper asks which combinations of imitation, demonstration, and preferences will best guide an agent in Atari games. For example an agent that is playing Pong on the Atari, but can't access the score. You might help it by demonstrating your play style for a few hours. To help the agent further you are shown two short clips of it playing and you are asked to indicate which one, if any, you prefer. To avoid spending many hours rating videos the authors sometimes used an automated approach where the game's score decides which clip is preferred, but they also compared this approach to human preferences. It turns out that human preferences are often worse because of reward traps. These happen, for example, when the human tries to encourage the agent to explore ladders, resulting in the agent obsessing about ladders instead of continuing the game. They also observed that the agent often misunderstood the preferences it was given, causing unexpected behavior called reward hacking. The only solution they mention was to have someone keep an eye on it and continue giving it preferences, but this isn't always feasible. This is the alignment problem which is a hard problem in AGI research. Results: adding merely a few thousand preferences can help in most games, unless they have sparse rewards. Demonstrations, on the other hand, tend to help those games with sparse rewards but only if the demonstrator is good at the game. |
Model-Based Active Exploration
Pranav Shyam and Wojciech Jaśkowski and Faustino Gomez
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.IT, cs.NE, math.IT, stat.ML
First published: 2018/10/29 (5 years ago)
Abstract: Efficient exploration is an unsolved problem in Reinforcement Learning. We introduce Model-Based Active eXploration (MAX), an algorithm that actively explores the environment. It minimizes data required to comprehensively model the environment by planning to observe novel events, instead of merely reacting to novelty encountered by chance. Non-stationarity induced by traditional exploration bonus techniques is avoided by constructing fresh exploration policies only at time of action. In semi-random toy environments where directed exploration is critical to make progress, our algorithm is at least an order of magnitude more efficient than strong baselines.
more
less
Pranav Shyam and Wojciech Jaśkowski and Faustino Gomez
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.IT, cs.NE, math.IT, stat.ML
First published: 2018/10/29 (5 years ago)
Abstract: Efficient exploration is an unsolved problem in Reinforcement Learning. We introduce Model-Based Active eXploration (MAX), an algorithm that actively explores the environment. It minimizes data required to comprehensively model the environment by planning to observe novel events, instead of merely reacting to novelty encountered by chance. Non-stationarity induced by traditional exploration bonus techniques is avoided by constructing fresh exploration policies only at time of action. In semi-random toy environments where directed exploration is critical to make progress, our algorithm is at least an order of magnitude more efficient than strong baselines.
|
[link]
This paper continues in the tradition of curiosity-based models, which try to reward models for exploring novel parts of their environment, in the hopes this can intrinsically motivate learning. However, this paper argues that it’s insufficient to just treat novelty as an occasional bonus on top of a normal reward function, and that instead you should figure out a process that’s more specifically designed to increase novelty. Specifically: you should design a policy whose goal is to experience transitions and world-states that are high novelty. In this setup, like in other curiosity-based papers, “high novelty” is defined in terms of a state being unpredictable given a prior state, history, and action. However, where other papers saw novelty reward as something only applied when the agent arrived at somewhere novel, here, the authors build a model (technically, an ensemble of models) to predict the state at various future points. The ensemble is important here because it’s (quasi) bootstrapped, and thus gives us a measure of uncertainty. States where the predictions of the ensemble diverge represent places of uncertainty, and thus of high value to explore. I don’t 100% follow the analytic specification of this idea (even though the heuristic/algorithmic description makes sense). The authors frame the Utility function of a state and action as being equivalent to the Jenson Shannon Divergence (~distance between probability distributions) shown below. https://i.imgur.com/YIuomuP.png Here, P(S | S, a, T) is the probability of a state given prior state and action under a given model of the environment (Transition Model), and P(gamma) is the distribution over the space of possible transition models one might learn. A “model” here is one network out of the ensemble of networks that makes up our bootstrapped (trained on different sets) distribution over models. Conceptually, I think this calculation is measuring “how different is each sampled model/state distribution from all the other models in the distribution over possible models”. If the models within the distribution diverge from one another, that indicates a location of higher uncertainty. What’s important about this is that, by building a full transition model, the authors can calculate the expected novelty or “utility” of future transitions it might take, because it can make a best guess based on this transition model (which, while called a “prior”, is really something trained on all data up to this current iteration). My understanding is that these kinds of models function similarly to a Q(s,a) or V(s) in a pure-reward case: they estimate the “utility reward” of different states and actions, and then the policy is updated to increase that expected reward. I’ve recently read papers on ICM, and I was a little disappointed that this paper didn’t appear to benchmark against that, but against Bootstrapped DQN and Exploration Bonus DQN, which I know less well and can less speak to the conceptual differences from this approach. Another difficulty in actually getting a good sense of results was that the task being tested on is fairly specific, and different from RL results coming out of the world of e.g. Atari and Deep Mind Labs. All of that said, this is a cautiously interesting idea, if the results generate to beat more baselines on more environments.
2 Comments
  |
Episodic Curiosity through Reachability
Nikolay Savinov and Anton Raichuk and Raphaël Marinier and Damien Vincent and Marc Pollefeys and Timothy Lillicrap and Sylvain Gelly
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.RO, stat.ML
First published: 2018/10/04 (5 years ago)
Abstract: Rewards are sparse in the real world and most today's reinforcement learning algorithms struggle with such sparsity. One solution to this problem is to allow the agent to create rewards for itself - thus making rewards dense and more suitable for learning. In particular, inspired by curious behaviour in animals, observing something novel could be rewarded with a bonus. Such bonus is summed up with the real task reward - making it possible for RL algorithms to learn from the combined reward. We propose a new curiosity method which uses episodic memory to form the novelty bonus. To determine the bonus, the current observation is compared with the observations in memory. Crucially, the comparison is done based on how many environment steps it takes to reach the current observation from those in memory - which incorporates rich information about environment dynamics. This allows us to overcome the known "couch-potato" issues of prior work - when the agent finds a way to instantly gratify itself by exploiting actions which lead to unpredictable consequences. We test our approach in visually rich 3D environments in ViZDoom and DMLab. In ViZDoom, our agent learns to successfully navigate to a distant goal at least 2 times faster than the state-of-the-art curiosity method ICM. In DMLab, our agent generalizes well to new procedurally generated levels of the game - reaching the goal at least 2 times more frequently than ICM on test mazes with very sparse reward.
more
less
Nikolay Savinov and Anton Raichuk and Raphaël Marinier and Damien Vincent and Marc Pollefeys and Timothy Lillicrap and Sylvain Gelly
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.RO, stat.ML
First published: 2018/10/04 (5 years ago)
Abstract: Rewards are sparse in the real world and most today's reinforcement learning algorithms struggle with such sparsity. One solution to this problem is to allow the agent to create rewards for itself - thus making rewards dense and more suitable for learning. In particular, inspired by curious behaviour in animals, observing something novel could be rewarded with a bonus. Such bonus is summed up with the real task reward - making it possible for RL algorithms to learn from the combined reward. We propose a new curiosity method which uses episodic memory to form the novelty bonus. To determine the bonus, the current observation is compared with the observations in memory. Crucially, the comparison is done based on how many environment steps it takes to reach the current observation from those in memory - which incorporates rich information about environment dynamics. This allows us to overcome the known "couch-potato" issues of prior work - when the agent finds a way to instantly gratify itself by exploiting actions which lead to unpredictable consequences. We test our approach in visually rich 3D environments in ViZDoom and DMLab. In ViZDoom, our agent learns to successfully navigate to a distant goal at least 2 times faster than the state-of-the-art curiosity method ICM. In DMLab, our agent generalizes well to new procedurally generated levels of the game - reaching the goal at least 2 times more frequently than ICM on test mazes with very sparse reward.
|
[link]
This paper proposes a new curiosity-based intrinsic reward technique that seeks to address one of the failure modes of previous curiosity methods. The basic idea of curiosity is that, often, exploring novel areas of an environment can be correlated with gaining reward within that environment, and that we can find ways to incentivize the former that don’t require a hand-designed reward function. This is appealing because many useful-to-learn environments either lack inherent reward altogether, or have reward that is very sparse (i.e. no signal until you reach the end, at which point you get a reward of 1). In both of these cases, supplementing with some kind of intrinsic incentive towards exploration might improve performance. The existing baseline curiosity technique is called ICM, and works based on “surprisal”: asking the agent to predict the next state as a function of its current state, and incentivizing exploration of areas where the gap between these two quantities is high, to promote exploration of harder-to-predict (and presumably more poorly sampled) locations. However, one failure mode of this approach is something called the “noisy TV” problem, whereby if the environment contains something analogous to a television where one can press a button and go to a random channel, that is highly unpredictable, and thus a source of easy rewards, and thus liable to distract the agent from any other actions. As an alternative, the authors here suggest a different way of defining novelty: rather than something that is unpredictable, novelty should be seen as something far away from what I as an agent have seen before. This is more direct than the prior approach, which takes ‘hard to predict’ as a proxy for ‘somewhere I haven’t explored’, which may not necessary be a reasonable assumption. https://i.imgur.com/EfcAOoI.png They implement this idea by keeping a memory of past (embedded) observations that the agent has seen during this episode, and, at each step, check whether the current observation is predicted to be more than K steps away than any of the observations in memory (more on that in a moment). If so, a bonus reward is added, and this observation is added to the aforementioned memory. (Which, waving hands vigorously, kind of ends up functioning as a spanning set of prior experience). https://i.imgur.com/gmHE11s.png The question of “how many steps is observation A from observation B” is answered by a separate Comparator network which is trained in pretty straightforward fashion: a random-samplling policy is used to collect trajectories, which are then turned into pairs of observations as input, and a 1 if they occurred > k + p steps apart, and a 0 if they occurred < k steps apart. Then, these paired states are passed into a shared-weight convolutional network, which creates an embedding, and, from that embedding, a prediction is made as to whether they’re closer than the thresholds or farther away. This network is pre-trained before the actual RL training starts. (Minor sidenote: at RL-training time, the network is chopped into two, and the embedding read out and stored, and then input as a pair with each current observation to make the prediction). https://i.imgur.com/1oUWKyb.png Overall, the authors find that their method works better than both ICM and no-intrinsic-reward for VizDoom (a maze + shooting game), and the advantage is stronger in situations more sparse settings of the external reward. https://i.imgur.com/4AURZbX.png On DeepMind Lab tasks, they saw no advantage on tasks with already-dense extrinsic rewards, and little advantage on the “normally sparse”, which they suggest may be due to it actually being easier than expected. They added doors to a maze navigation task, to ensure the agent couldn’t find the target right away, and this situation brought better performance of their method. They also tried a fully no-extrinsic-reward situation, and their method strongly performed both the ICM baseline and (obviously) the only-extrinsic-reward baseline, which was basically an untrained random policy in this setting. Regarding the poor performance of the ICM baseline in this environment, “we hypothesise that the agent can most significantly change its current view when it is close to the wall — thus increasing one-step prediction error — so it tends to get stucknear “interesting” diverse textures on the walls.”. |
Large-Scale Study of Curiosity-Driven Learning
Yuri Burda and Harri Edwards and Deepak Pathak and Amos Storkey and Trevor Darrell and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.RO, stat.ML
First published: 2018/08/13 (5 years ago)
Abstract: Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at https://pathak22.github.io/large-scale-curiosity/
more
less
Yuri Burda and Harri Edwards and Deepak Pathak and Amos Storkey and Trevor Darrell and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CV, cs.RO, stat.ML
First published: 2018/08/13 (5 years ago)
Abstract: Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at https://pathak22.github.io/large-scale-curiosity/
|
[link]
I really enjoyed this paper - in addition to being a clean, fundamentally empirical work, it was also clearly written, and had some pretty delightful moments of quotable zen, which I’ll reference at the end. The paper’s goal is to figure out how far curiosity-driven learning alone can take reinforcement learning systems, without the presence of an external reward signal. “Intrinsic” reward learning is when you construct a reward out of internal, inherent features of the environment, rather than using an explicit reward function. In some ways, intrinsic learning in RL can be thought of as analogous to unsupervised learning in classification problems, since reward functions are not inherent to most useful environments, and (when outside of game environments that inherently provide rewards), frequently need to be hand-designed. Curiosity-driven learning is a subset of intrinsic learning, which uses as a reward signal the difference between a prediction made by the dynamics model (predicting next state, given action) and the true observed next state. Situations where the this prediction area are high generate high reward for the agent, which incentivizes it to reach those states, which allows the dynamics model to then make ever-better predictions about them. Two key questions this paper raises are: 1) Does this approach even work when used on it’s own? Curiosity had previously most often been used as a supplement to extrinsic rewards, and the authors wanted to know how far it could go separately. 2) What is the best feature to do this “surprisal difference” calculation in? Predicting raw pixels is a high-dimensional and noisy process, so naively we might want something with fewer, more informationally-dense dimensions, but it’s not obvious which methods that satisfy these criteria will work the best, so the paper empirically tried them. The answer to (1) seems to be: yes, at least in the video games tested. Impressively, when you track against extrinsic reward (which, again, these games have, but we’re just ignoring in a curiosity-only setting), the agents manage to increase it despite not optimizing against it directly. There were some Atari games where this effect was stronger than others, but overall performance was stronger than might have been naively expected. One note the authors made, worth keeping in mind, is that it’s unclear how much of this is an artifact of the constraints and incentives surrounding game design, which might reflect back a preference for gradually-increasing novelty because humans find it pleasant. https://i.imgur.com/zhl39vo.png As for (2), another interesting result of this paper is that random features performed consistently well as a feature space to do these prediction/reality comparisons in. Random features here is really just as simple as “design a convolutional net that compresses down to some dimension, randomly initialize it, and then use those randomly initialized weights to run forward passes of the network to get your lower-dimensional state”. This has the strong disadvantage of (presumably) not capturing any meaningful information about the state, but also has the advantage of being stable: the other techniques tried, like pulling out the center of a VAE bottleneck, changed over time as they were being trained on new states, so they were informative, but non-stationary. My two favorite quotable moments from this paper were: 1) When the authors noted that they had removed the “done” signal associated with an agent “dying,” because it is itself a sort of intrinsic reward. However, “in practice, we do find that the agent avoids dying in the games since that brings it back to the beginning of the game, an area it has already seen many times and where it can predict the dynamics well.”. Short and sweet: “Avoiding death, because it’s really boring” https://i.imgur.com/SOfML8d.png 2) When they noted that an easy way to hack the motivation structure of a curiosity-driven agent was through a “noisy tv”, which, every time you pressed the button, jumped to a random channel. As expected, when they put this distraction inside a maze, the agent spent more time jacking up reward through that avenue, rather than exploring. Any resemblance to one’s Facebook feed is entirely coincidental. |
Multi-task Deep Reinforcement Learning with PopArt
Matteo Hessel and Hubert Soyer and Lasse Espeholt and Wojciech Czarnecki and Simon Schmitt and Hado van Hasselt
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/09/12 (5 years ago)
Abstract: The reinforcement learning community has made great strides in designing algorithms capable of exceeding human performance on specific tasks. These algorithms are mostly trained one task at the time, each new task requiring to train a brand new agent instance. This means the learning algorithm is general, but each solution is not; each agent can only solve the one task it was trained on. In this work, we study the problem of learning to master not one but multiple sequential-decision tasks at once. A general issue in multi-task learning is that a balance must be found between the needs of multiple tasks competing for the limited resources of a single learning system. Many learning algorithms can get distracted by certain tasks in the set of tasks to solve. Such tasks appear more salient to the learning process, for instance because of the density or magnitude of the in-task rewards. This causes the algorithm to focus on those salient tasks at the expense of generality. We propose to automatically adapt the contribution of each task to the agent's updates, so that all tasks have a similar impact on the learning dynamics. This resulted in state of the art performance on learning to play all games in a set of 57 diverse Atari games. Excitingly, our method learned a single trained policy - with a single set of weights - that exceeds median human performance. To our knowledge, this was the first time a single agent surpassed human-level performance on this multi-task domain. The same approach also demonstrated state of the art performance on a set of 30 tasks in the 3D reinforcement learning platform DeepMind Lab.
more
less
Matteo Hessel and Hubert Soyer and Lasse Espeholt and Wojciech Czarnecki and Simon Schmitt and Hado van Hasselt
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/09/12 (5 years ago)
Abstract: The reinforcement learning community has made great strides in designing algorithms capable of exceeding human performance on specific tasks. These algorithms are mostly trained one task at the time, each new task requiring to train a brand new agent instance. This means the learning algorithm is general, but each solution is not; each agent can only solve the one task it was trained on. In this work, we study the problem of learning to master not one but multiple sequential-decision tasks at once. A general issue in multi-task learning is that a balance must be found between the needs of multiple tasks competing for the limited resources of a single learning system. Many learning algorithms can get distracted by certain tasks in the set of tasks to solve. Such tasks appear more salient to the learning process, for instance because of the density or magnitude of the in-task rewards. This causes the algorithm to focus on those salient tasks at the expense of generality. We propose to automatically adapt the contribution of each task to the agent's updates, so that all tasks have a similar impact on the learning dynamics. This resulted in state of the art performance on learning to play all games in a set of 57 diverse Atari games. Excitingly, our method learned a single trained policy - with a single set of weights - that exceeds median human performance. To our knowledge, this was the first time a single agent surpassed human-level performance on this multi-task domain. The same approach also demonstrated state of the art performance on a set of 30 tasks in the 3D reinforcement learning platform DeepMind Lab.
|
[link]
This paper posits that one of the central problems stopping multi-task RL - that is, single models trained to perform multiple tasks well - from reaching better performance, is the inability to balance model resources and capacity between the different tasks the model is being asked to learn. Empirically, prior to this paper, multi-task RL could reach ~50% of human accuracy on Atari and Deepmind Lab tasks. The fact that this is lower than human accuracy is actually somewhat less salient than the fact that it’s quite a lot lower than single-task RL - how a single model trained to perform only that task could do. When learning a RL model across multiple tasks, the reward structures of the different tasks can vary dramatically. Some can have high-magnitude, sparse rewards, some can have low magnitude rewards throughout. If a model learns it can gain what it thinks is legitimately more reward by getting better at a game with an average reward of 2500 than it does with an average reward of 15, it will put more capacity into solving the former task. Even if you apply normalization strategies like reward clipping (which treats all rewards as a binary signal, regardless of magnitude, and just seeks to increase the frequency of rewards), that doesn’t deal with some environments having more frequent rewards than others, and thus more total reward when summed over timestep. The authors here try to solve this problem by performing a specific kind of normalization, called Pop Art normalization, on the problem. PopArt normalization (don’t worry about the name) works by adaptively normalizing both the target and the estimate of the target output by the model, at every step. In the Actor-Critic case that this model is working on, the target and estimate that are being normalized are, respectively, 1) the aggregated rewards of the trajectories from state S onward, and 2) the value estimate at state S. If your value function is perfect, these two things should be equivalent, and so you optimize your value function to be closer to the true rewards under your policy. And, then, you update your policy to increase probability of actions with higher advantage (expected reward with that action, relative to the baseline Value(S) of that state). The “adaptive” part of that refers to correcting for the fact when you’re estimating, say, a Value function to predict the total future reward of following a policy at a state, that V(S) will be strongly non-stationary, since by improving your policy you are directly optimizing to increase that value. This is done by calculating “scale” and “shift” parameters off of a recent data. The other part of the PopArt algorithm works by actually updating the estimate our model is producing, to stay normalized alongside the continually-being-re-normalized target. https://i.imgur.com/FedXTfB.png It does this by taking the new and old versions of scale (sigma) and shift (mu) parameters (which will be used to normalize the target) and updates the weights and biases of the last layer, such that the movement of the estimator moves along with the movement in the target. Using this toolkit, this paper proposes learning one *policy* that’s shared over all task, but keeping shared value estimation functions for each task. Then, it normalizes each task’s values independently, meaning that each task ends up contributing equal weight to the gradient updates of the model (both for the Value and Policy updates). In doing this, the authors find dramatically improved performance at both Atari and Deepmind, relative to prior IMPALA work https://i.imgur.com/nnDcjNm.png https://i.imgur.com/Z6JClo3.png |
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Lasse Espeholt and Hubert Soyer and Remi Munos and Karen Simonyan and Volodymir Mnih and Tom Ward and Yotam Doron and Vlad Firoiu and Tim Harley and Iain Dunning and Shane Legg and Koray Kavukcuoglu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI
First published: 2018/02/05 (6 years ago)
Abstract: In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
more
less
Lasse Espeholt and Hubert Soyer and Remi Munos and Karen Simonyan and Volodymir Mnih and Tom Ward and Yotam Doron and Vlad Firoiu and Tim Harley and Iain Dunning and Shane Legg and Koray Kavukcuoglu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI
First published: 2018/02/05 (6 years ago)
Abstract: In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
|
[link]
This reinforcement learning paper starts with the constraints imposed an engineering problem - the need to scale up learning problems to operate across many GPUs - and ended up, as a result, needing to solve an algorithmic problem along with it. In order to massively scale up their training to be able to train multiple problem domains in a single model, the authors of this paper implemented a system whereby many “worker” nodes execute trajectories (series of actions, states, and reward) and then send those trajectories back to a “learner” node, that calculates gradients and updates a central policy model. However, because these updates are queued up to be incorporated into the central learner, it can frequently happen that the policy that was used to collect the trajectories is a few steps behind from the policy on the central learner to which its gradients will be applied (since other workers have updated the learner since this worker last got a policy download). This results in a need to modify the policy network model design accordingly. IMPALA (Importance Weighted Actor Learner Architectures) uses an “Actor Critic” model design, which means you learn both a policy function and a value function. The policy function’s job is to choose which actions to take at a given state, by making some higher probability than others. The value function’s job is to estimate the reward from a given state onward, if a certain policy p is followed. The value function is used to calculate the “advantage” of each action at a given state, by taking the reward you receive through action a (and reward you expect in the future), and subtracting out the value function for that state, which represents the average future reward you’d get if you just sampled randomly from the policy from that point onward. The policy network is then updated to prioritize actions which are higher-advantage. If you’re on-policy, you can calculate a value function without needing to explicitly calculate the probabilities of each action, because, by definition, if you take actions according to your policy probabilities, then you’re sampling each action with a weight proportional to its probability. However, if your actions are calculated off-policy, you need correct for this, typically by calculating an “importance sampling” ratio, that multiplies all actions by a probability under the desired policy divided by the probability under the policy used for sampling. This cancels out the implicit probability under the sampling policy, and leaves you with your actions scaled in proportion to their probability under the policy you’re actually updating. IMPALA shares the basic structure of this solution, but with a few additional parameters to dynamically trade off between the bias and variance of the model. The first parameter, rho, controls how much bias you allow into your model, where bias here comes from your model not being fully corrected to “pretend” that you were sampling from the policy to which gradients are being applied. The trade-off here is that if your policies are far apart, you might downweight its actions so aggressively that you don’t get a strong enough signal to learn quickly. However, the policy you learn might be statistically biased. Rho does this by weighting each value function update by: https://i.imgur.com/4jKVhCe.png where rho-bar is a hyperparameter. If rho-bar is high, then we allow stronger weighting effects, whereas if it’s low, we put a cap on those weights. The other parameter is c, and instead of weighting each value function update based on policy drift at that state, it weights each timestep based on how likely or unlikely the action taken at that timestep was under the true policy. https://i.imgur.com/8wCcAoE.png Timesteps that much likelier under the true policy are upweighted, and, once again, we use a hyperparameter, c-bar, to put a cap on the amount of allowed upweighting. Where the prior parameter controlled how much bias there was in the policy we learn, this parameter helps control the variance - the higher c-bar, the higher the amount of variance there will be in the updates used to train the model, and the longer it’ll take to converge. |
Language GANs Falling Short
Massimo Caccia and Lucas Caccia and William Fedus and Hugo Larochelle and Joelle Pineau and Laurent Charlin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL, cs.LG
First published: 2018/11/06 (5 years ago)
Abstract: Generating high-quality text with sufficient diversity is essential for a wide range of Natural Language Generation (NLG) tasks. Maximum-Likelihood (MLE) models trained with teacher forcing have constantly been reported as weak baselines, where poor performance is attributed to exposure bias; at inference time, the model is fed its own prediction instead of a ground-truth token, which can lead to accumulating errors and poor samples. This line of reasoning has led to an outbreak of adversarial based approaches for NLG, on the account that GANs do not suffer from exposure bias. In this work, we make several surprising observations with contradict common beliefs. We first revisit the canonical evaluation framework for NLG, and point out fundamental flaws with quality-only evaluation: we show that one can outperform such metrics using a simple, well-known temperature parameter to artificially reduce the entropy of the model's conditional distributions. Second, we leverage the control over the quality / diversity tradeoff given by this parameter to evaluate models over the whole quality-diversity spectrum, and find MLE models constantly outperform the proposed GAN variants, over the whole quality-diversity space. Our results have several implications: 1) The impact of exposure bias on sample quality is less severe than previously thought, 2) temperature tuning provides a better quality / diversity trade off than adversarial training, while being easier to train, easier to cross-validate, and less computationally expensive.
more
less
Massimo Caccia and Lucas Caccia and William Fedus and Hugo Larochelle and Joelle Pineau and Laurent Charlin
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL, cs.LG
First published: 2018/11/06 (5 years ago)
Abstract: Generating high-quality text with sufficient diversity is essential for a wide range of Natural Language Generation (NLG) tasks. Maximum-Likelihood (MLE) models trained with teacher forcing have constantly been reported as weak baselines, where poor performance is attributed to exposure bias; at inference time, the model is fed its own prediction instead of a ground-truth token, which can lead to accumulating errors and poor samples. This line of reasoning has led to an outbreak of adversarial based approaches for NLG, on the account that GANs do not suffer from exposure bias. In this work, we make several surprising observations with contradict common beliefs. We first revisit the canonical evaluation framework for NLG, and point out fundamental flaws with quality-only evaluation: we show that one can outperform such metrics using a simple, well-known temperature parameter to artificially reduce the entropy of the model's conditional distributions. Second, we leverage the control over the quality / diversity tradeoff given by this parameter to evaluate models over the whole quality-diversity spectrum, and find MLE models constantly outperform the proposed GAN variants, over the whole quality-diversity space. Our results have several implications: 1) The impact of exposure bias on sample quality is less severe than previously thought, 2) temperature tuning provides a better quality / diversity trade off than adversarial training, while being easier to train, easier to cross-validate, and less computationally expensive.
|
[link]
This paper’s high-level goal is to evaluate how well GAN-type structures for generating text are performing, compared to more traditional maximum likelihood methods. In the process, it zooms into the ways that the current set of metrics for comparing text generation fail to give a well-rounded picture of how models are performing. In the old paradigm, of maximum likelihood estimation, models were both trained and evaluated on a maximizing the likelihood of each word, given the prior words in a sequence. That is, models were good when they assigned high probability to true tokens, conditioned on past tokens. However, GANs work in a fundamentally new framework, in that they aren’t trained to increase the likelihood of the next (ground truth) word in a sequence, but to generate a word that will make a discriminator more likely to see the sentence as realistic. Since GANs don’t directly model the probability of token t, given prior tokens, you can’t evaluate them using this maximum likelihood framework. This paper surveys a range of prior work that has evaluated GANs and MLE models on two broad categories of metrics, occasionally showing GANs to perform better on one or the other, but not really giving a way to trade off between the two. - The first type of metric, shorthanded as “quality”, measures how aligned the generated text is with some reference corpus of text: to what extent your generated text seems to “come from the same distribution” as the original. BLEU, a heuristic frequently used in translation, and also leveraged here, measures how frequently certain sets of n-grams occur in the reference text, relative to the generated text. N typically goes up to 4, and so in addition to comparing the distributions of single tokens in the reference and generated, BLEU also compares shared bigrams, trigrams, and quadgrams (?) to measure more precise similarity of text. - The second metric, shorthanded as “diversity” measures how different generated sentences are from one another. If you want to design a model to generate text, you presumably want it to be able to generate a diverse range of text - in probability terms, you want to fully sample from the distribution, rather than just taking the expected or mean value. Linguistically, this would be show up as a generator that just generates the same sentence over and over again. This sentence can be highly representative of the original text, but lacks diversity. One metric used for this is the same kind of BLEU score, but for each generated sentence against a corpus of prior generated sentences, and, here, the goal is for the overlap to be as low as possible The trouble with these two metrics is that, in their raw state, they’re pretty incommensurable, and hard to trade off against one another. The authors of this paper try to address this by observing that all models trade off diversity and quality to some extent, just by modifying the entropy of the conditional token distribution they learn. If a distribution is high entropy, that is, if it spreads probability out onto more tokens, it’s likelier to bounce off into a random place, which increases diversity, but also can make the sentence more incoherent. By contrast, if a distribution is too low entropy, only ever putting probability on one or two words, then it will be only ever capable of carving out a small number of distinct paths through word space. The below table shows a good example of what language generation can look like at high and low levels of entropy https://i.imgur.com/YWGXDaJ.png The entropy of a softmax distribution be modified, without changing the underlying model, by changing the *temperature* of the softmax calculation. So, the authors do this, and, as a result, they can chart out that model’s curve on the quality/diversity axis. Conceptually, this is asking “at a range of different quality thresholds, how good is this model’s diversity,” and vice versa. I mentally analogize this to a ROC curve, where it’s not really possible to compare, say, precision of models that use different thresholds, and so you instead need to compare the curve over a range of different thresholds, and compare models on that. https://i.imgur.com/C3zdEjm.png When they do this for GANs and MLEs, they find that, while GANs might dominate on a single metric at a time, when you modulate the temperature of MLE models, they’re able to achieve superior quality when you tune them to commensurate levels of diversity. |
On the Evaluation of Common-Sense Reasoning in Natural Language Understanding
Paul Trichelair and Ali Emami and Jackie Chi Kit Cheung and Adam Trischler and Kaheer Suleman and Fernando Diaz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CL, stat.ML
First published: 2018/11/05 (5 years ago)
Abstract: The NLP and ML communities have long been interested in developing models capable of common-sense reasoning, and recent works have significantly improved the state of the art on benchmarks like the Winograd Schema Challenge (WSC). Despite these advances, the complexity of tasks designed to test common-sense reasoning remains under-analyzed. In this paper, we make a case study of the Winograd Schema Challenge and, based on two new measures of instance-level complexity, design a protocol that both clarifies and qualifies the results of previous work. Our protocol accounts for the WSC's limited size and variable instance difficulty, properties common to other common-sense benchmarks. Accounting for these properties when assessing model results may prevent unjustified conclusions.
more
less
Paul Trichelair and Ali Emami and Jackie Chi Kit Cheung and Adam Trischler and Kaheer Suleman and Fernando Diaz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CL, stat.ML
First published: 2018/11/05 (5 years ago)
Abstract: The NLP and ML communities have long been interested in developing models capable of common-sense reasoning, and recent works have significantly improved the state of the art on benchmarks like the Winograd Schema Challenge (WSC). Despite these advances, the complexity of tasks designed to test common-sense reasoning remains under-analyzed. In this paper, we make a case study of the Winograd Schema Challenge and, based on two new measures of instance-level complexity, design a protocol that both clarifies and qualifies the results of previous work. Our protocol accounts for the WSC's limited size and variable instance difficulty, properties common to other common-sense benchmarks. Accounting for these properties when assessing model results may prevent unjustified conclusions.
|
[link]
I should say from the outset: I have a lot of fondness for this paper. It goes upstream of a lot of research-community incentives: It’s not methodologically flashy, it’s not about beating the State of the Art with a bigger, better model (though, those papers certainly also have their place). The goal of this paper was, instead, to dive into a test set used to evaluate performance of models, and try to understand to what extent it’s really providing a rigorous test of what we want out of model behavior. Test sets are the often-invisible foundation upon which ML research is based, but like real-world foundations, if there are weaknesses, the research edifice built on top can suffer. Specifically, this paper discusses the Winograd Schema, a clever test set used to test what the NLP community calls “common sense reasoning”. An example Winograd Schema sentence is: The delivery truck zoomed by the school bus because it was going so fast. A model is given this task, and asked to predict which token the underlined “it” refers to. These cases are specifically chosen because of their syntactic ambiguity - nothing structural about the order of the sentence requires “it” to refer to the delivery truck here. However, the underlying meaning of the sentence is only coherent under that parsing. This is what is meant by “common-sense” reasoning: the ability to understand meaning of a sentence in a way deeper than that allowed by simple syntactic parsing and word co-occurrence statistics. Taking the existing Winograd examples (and, when I said tiny, there are literally 273 of them) the authors of this paper surface some concerns about ways these examples might not be as difficult or representative of “common sense” abilities as we might like. - First off, there is the basic, previously mentioned fact that there are so few examples that it’s possible to perform well simply by random chance, especially over combinatorially large hyperparameter optimization spaces. This isn’t so much an indictment of the set itself as it is indicative of the work involved in creating it. - One of the two distinct problems the paper raises is that of “associativity”. This refers to situations where simple co-occurance counts between the description and the correct entity can lead the model to the correct term, without actually having to parse the sentence. An example here is: “I’m sure that my map will show this building; it is very famous.” Treasure maps aside, “famous buildings” are much more generally common than “famous maps”, and so being able to associate “it” with a building in this case doesn’t actually require the model to understand what’s going on in this specific sentence. The authors test this by creating a threshold for co-occurance, and, using that threshold, call about 40% of the examples “associative” - The second problem is that of predictable structure - the fact that the “hinge” adjective is so often the last word in the sentence, making it possible that the model is brittle, and just attending to that, rather than the sentence as a whole The authors perform a few tests - examining results on associative vs non-associative examples, and examining results if you switch the ordering (in cases like “Emma did not pass the ball to Janie although she saw that she was open,” where it’s syntactically possible), to ensure the model is not just anchoring on the identity of the correct entity, regardless of its place in the sentence. Overall, they found evidence that some of the state of the art language models perform well on the Winograd Schema as a whole, but do less well (and in some cases even less well than the baselines they otherwise outperform) on these more rigorous examples. Unfortunately, these tests don’t lead us automatically to a better solution - design of examples like this is still tricky and hard to scale - but does provide valuable caution and food for thought. |
Trellis Networks for Sequence Modeling
Shaojie Bai and J. Zico Kolter and Vladlen Koltun
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CL, stat.ML
First published: 2018/10/15 (5 years ago)
Abstract: We present trellis networks, a new architecture for sequence modeling. On the one hand, a trellis network is a temporal convolutional network with special structure, characterized by weight tying across depth and direct injection of the input into deep layers. On the other hand, we show that truncated recurrent networks are equivalent to trellis networks with special sparsity structure in their weight matrices. Thus trellis networks with general weight matrices generalize truncated recurrent networks. We leverage these connections to design high-performing trellis networks that absorb structural and algorithmic elements from both recurrent and convolutional models. Experiments demonstrate that trellis networks outperform the current state of the art on a variety of challenging benchmarks, including word-level language modeling on Penn Treebank and WikiText-103, character-level language modeling on Penn Treebank, and stress tests designed to evaluate long-term memory retention. The code is available at https://github.com/locuslab/trellisnet .
more
less
Shaojie Bai and J. Zico Kolter and Vladlen Koltun
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, cs.CL, stat.ML
First published: 2018/10/15 (5 years ago)
Abstract: We present trellis networks, a new architecture for sequence modeling. On the one hand, a trellis network is a temporal convolutional network with special structure, characterized by weight tying across depth and direct injection of the input into deep layers. On the other hand, we show that truncated recurrent networks are equivalent to trellis networks with special sparsity structure in their weight matrices. Thus trellis networks with general weight matrices generalize truncated recurrent networks. We leverage these connections to design high-performing trellis networks that absorb structural and algorithmic elements from both recurrent and convolutional models. Experiments demonstrate that trellis networks outperform the current state of the art on a variety of challenging benchmarks, including word-level language modeling on Penn Treebank and WikiText-103, character-level language modeling on Penn Treebank, and stress tests designed to evaluate long-term memory retention. The code is available at https://github.com/locuslab/trellisnet .
|
[link]
For solving sequence modeling problems, recurrent architectures have been historically the most commonly used solution, but, recently, temporal convolution networks, especially with dilations to help capture longer term dependencies, have gained prominence. RNNs have theoretically much larger capacity to learn long sequences, but also have a lot of difficulty propagating signal forward through long chains of recurrent operations. This paper, which suggests the approach of Trellis Networks, places itself squarely in the middle of the debate between these two paradigms. TrellisNets are designed to be a theoretical bridge between between temporal convolutions and RNNs - more specialized than the former, but more generalized than the latter. https://i.imgur.com/J2xHYPx.png The architecture of TrellisNets is very particular, and, unfortunately, somewhat hard to internalize without squinting at diagrams and equations for awhile. Fundamentally: - At each layer in a TrellisNet, the network creates a “candidate pre-activation” by combining information from the input and the layer below, for both the current and former time step. - This candidate pre-activation is then non-linearly combined with the prior layer, prior-timestep hidden state - This process continues for some desired number of layers. https://i.imgur.com/f96QgT8.png At first glance, this structure seems pretty arbitrary: a lot of quantities connected together, but without a clear mechanic for what’s happening. However, there are a few things interesting to note here, which will help connect these dots, to view TrellisNet as either a kind of RNN or a kind of CNN: - TrellisNet uses the same weight matrices to process prior and current timestep inputs/hidden states, no matter which timestep or layer it’s on. This is strongly reminiscent of a recurrent architecture, which uses the same calculation loop at each timestep - TrellisNets also re-insert the model’s input at each layer. This also gives it more of a RNN-like structure, where the prior layer’s values act as a kind of “hidden state”, which are then combined with an input value - At a given layer, each timestep only needs access to two elements of the prior layer (in addition to the input); it does not require access to all the prior-timestep values of it’s own layer. This is important because it means that you can calculate an entire layer’s values at once, given the values of the prior layer: this means these models can be more easily parallelized for training Seeing TrellisNets as a kind of Temporal CNN is fairly straightforward: each timestep’s value, at a given layer, is based on a “filter” of the lower-layer value at the current and prior timestep, and this filter is shared across the whole sequence. Framing them as a RNN is certainly trickier, and anyone wanting to understand it in full depth is probably best served by returning to the paper’s equations. At at high level, the authors show that TrellisNets can represent a specific kind of RNN: a truncated RNN, where each timestep only uses history from the prior M time steps, rather than the full sequence. This works by sort of imagining the RNN chains as existing along the diagonals of a TrellisNet architecture diagram: as you reach higher levels, you can also reach farther back in time. Specifically, a TrellisNet that wants to represent a depth K truncated RNN, which is allowed to unroll through M steps of history, can do so using M + K - 1 layers. Essentially, by using a fixed operation across layers and timesteps, the TrellisNet authors blur the line between layer and timestep: any chain of operations, across layers, is fundamentally a series of the same operation, performed many times, and is in that way RNN-like. The authors have not yet taken a stab at translation, but tested their model on a number of word and character-level language modeling tasks (predicting the next word or character, given prior ones), and were able to successfully beat SOTA on many of them. I’d be curious to see more work broadly in this domain, and also gain a better understanding of areas in which a fixed, recurrently-used layer operation, like the ones used in RNNs and this paper, is valuables, and areas (like a “normal” CNN) where having specific weights for different levels of the hierarchy is valable. |
Embedding Grammars
David Wingate and William Myers and Nancy Fulda and Tyler Etchart
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/08/14 (5 years ago)
Abstract: Classic grammars and regular expressions can be used for a variety of purposes, including parsing, intent detection, and matching. However, the comparisons are performed at a structural level, with constituent elements (words or characters) matched exactly. Recent advances in word embeddings show that semantically related words share common features in a vector-space representation, suggesting the possibility of a hybrid grammar and word embedding. In this paper, we blend the structure of standard context-free grammars with the semantic generalization capabilities of word embeddings to create hybrid semantic grammars. These semantic grammars generalize the specific terminals used by the programmer to other words and phrases with related meanings, allowing the construction of compact grammars that match an entire region of the vector space rather than matching specific elements.
more
less
David Wingate and William Myers and Nancy Fulda and Tyler Etchart
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/08/14 (5 years ago)
Abstract: Classic grammars and regular expressions can be used for a variety of purposes, including parsing, intent detection, and matching. However, the comparisons are performed at a structural level, with constituent elements (words or characters) matched exactly. Recent advances in word embeddings show that semantically related words share common features in a vector-space representation, suggesting the possibility of a hybrid grammar and word embedding. In this paper, we blend the structure of standard context-free grammars with the semantic generalization capabilities of word embeddings to create hybrid semantic grammars. These semantic grammars generalize the specific terminals used by the programmer to other words and phrases with related meanings, allowing the construction of compact grammars that match an entire region of the vector space rather than matching specific elements.
|
[link]
This paper is, on the whole, a refreshing jaunt into the applied side of the research word. It isn’t looking to solve a fundamental machine learning problem in some new way, but it does highlight and explore one potential beneficial application of a common and widely used technique: specifically, combining word embeddings with context-free grammars (such as: regular expressions), to make the latter less rigid. Regular expressions work by specifying specific hardcoded patterns of symbols, and matching against any strings in some search set that match those patterns. They don’t need to specify specific characters - they can work at higher levels of generality, like “uppercase alphabetic character” or “any character”, but they’re still fundamentally hardcoded, in that the designer of the expression needs to create a specification that will affirmatively catch all the desired cases. This can be a particular challenging task when you’re trying to find - for example - all sentences that match the pattern of someone giving someone else a compliment. You might want to match against “I think you’re smart” and also “I think you’re clever”. However, in the normal use of regular expressions, something like this would be nearly impossible to specify, short of writing out every synonym for “intelligent” that you can think of. The “Embedding Grammars” paper proposes a solution to this problem: instead of enumerating a list of synonyms, simply provide one example term, or, even better, a few examples, and use those term’s word embedding representation to define a “synonym bubble” (my word, not theirs) in continuous space around those examples. This is based on the oft-remarked-upon fact that, because word embedding systems are generally trained to push together words that can be used in similar contexts, closeness in word vector space frequently corresponds to words being synonyms, or close in some other sense. So, if you “match” to any term that is sufficiently nearby to your exemplar terms, you are performing something similar to the task of enumerating all of a term’s syllables. Once this general intuition is in hand, the details of the approach are fairly straightforward: the authors try a few approaches, and find that constructing a bubble of some epsilon around each example’s word vector, and matching to anything inside that bubble, works the best as an approach. https://i.imgur.com/j9OSNuE.png Overall, this seems like a clever idea; one imagines that the notion of word embeddings will keep branching out into ever more far-flung application as time goes on. There are reasons to be skeptical of this paper, though. Fundamentally, word embedding space is a “here there be dragons” kind of place: we may be able to observe broad patterns, and might be able to say that “nearby words tend to be synonyms,” but we can’t give any kind of guarantee of that being the case. As an example of this problem, often the nearest thing to an example, after direct synonyms, are direct antonyms, so if you set too high a threshold, you’ll potentially match to words exactly the opposite of what you expect. We are probably still a ways away from systems like this one being broady useful, for this and other reasons, but I do think it’s valuable to try to understand what questions we’d want answered, what features of embedding space we’d want more elucidated, before applications like these would be more stably usable. |
You May Not Need Attention
Ofir Press and Noah A. Smith
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/10/31 (5 years ago)
Abstract: In NMT, how far can we get without attention and without separate encoding and decoding? To answer that question, we introduce a recurrent neural translation model that does not use attention and does not have a separate encoder and decoder. Our eager translation model is low-latency, writing target tokens as soon as it reads the first source token, and uses constant memory during decoding. It performs on par with the standard attention-based model of Bahdanau et al. (2014), and better on long sentences.
more
less
Ofir Press and Noah A. Smith
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/10/31 (5 years ago)
Abstract: In NMT, how far can we get without attention and without separate encoding and decoding? To answer that question, we introduce a recurrent neural translation model that does not use attention and does not have a separate encoder and decoder. Our eager translation model is low-latency, writing target tokens as soon as it reads the first source token, and uses constant memory during decoding. It performs on par with the standard attention-based model of Bahdanau et al. (2014), and better on long sentences.
|
[link]
An attention mechanism and a separate encoder/decoder are two properties of almost every single neural translation model. The question asked in this paper is- how far can we go without attention and without a separate encoder and decoder? And the answer is- pretty far! The model presented preforms just as well as the attention model of Bahdanau on the four language directions that are studied in the paper.
The translation model presented in the paper is basically a simple recurrent language model. A recurrent language model receives at every timestep the current input word and has to predict the next word in the dataset. To translate with such a model, simply give it the current word from the source sentence and have it try to predict the next word from the target sentence.
Obviously, in many cases such a simple model wouldn't work. For example, if your sentence was "The white dog" and you wanted to translate to Spanish ("El perro blanco"), at the 2nd timestep, the input would be "white" and the expected output would be "perro" (dog). But how could the model predict "perro" when it hasn't seen "dog" yet?
To solve this issue, we preprocess the data before training and insert "empty" padding tokens into the target sentence. When the model outputs such a token, it means that the model would like to read more of the input sentence before emitting the next output word.
So in the example from above, we would change the target sentence to "El PAD perro blanco". Now, at timestep 2 the model emits the PAD symbol. At timestep 3, when the input is "dog", the model can emit the token "perro". These padding symbols are deleted in post-processing, before the output is returned to the user. You can see a visualization of the decoding process below:
https://i.imgur.com/znI6xoN.png
To enable us to use beam search, our model actually receives the previous outputted target token in addition to receiving the current source token at every timestep.
PyTorch code for the model is available at https://github.com/ofirpress/YouMayNotNeedAttention
|

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming-Wei Chang and Kenton Lee and Kristina Toutanova
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/10/11 (5 years ago)
Abstract: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
more
less
Jacob Devlin and Ming-Wei Chang and Kenton Lee and Kristina Toutanova
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/10/11 (5 years ago)
Abstract: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
|
[link]
The last two years have seen a number of improvements in the field of language model pretraining, and BERT - Bidirectional Encoder Representations from Transformers - is the most recent entry into this canon. The general problem posed by language model pretraining is: can we leverage huge amounts of raw text, which aren’t labeled for any specific classification task, to help us train better models for supervised language tasks (like translation, question answering, logical entailment, etc)? Mechanically, this works by either 1) training word embeddings and then using those embeddings as input feature representations for supervised models, or 2) treating the problem as a transfer learning problem, and fine-tune to a supervised task - similar to how you’d fine-tune a model trained on ImageNet by carrying over parameters, and then training on your new task. Even though the text we’re learning on is strictly speaking unsupervised (lacking a supervised label), we need to design a task on which we calculate gradients in order to train our representations. For unsupervised language modeling, that task is typically structured as predicting a word in a sequence given prior words in that sequence. Intuitively, in order for a model to do a good job at predicting the word that comes next in a sentence, it needs to have learned patterns about language, both on grammatical and semantic levels. A notable change recently has been the shift from learning unconditional word vectors (where the word’s representation is the same globally) to contextualized ones, where the representation of the word is dependent on the sentence context it’s found in. All the baselines discussed here are of this second type. The two main baselines that the BERT model compares itself to are OpenAI’s GPT, and Peters et al’s ELMo. The GPT model uses a self-attention-based Transformer architecture, going through each word in the sequence, and predicting the next word by calculating an attention-weighted representation of all prior words. (For those who aren’t familiar, attention works by multiplying a “query” vector with every word in a variable-length sequence, and then putting the outputs of those multiplications into a softmax operator, which inherently gets you a weighting scheme that adds to one). ELMo uses models that gather context in both directions, but in a fairly simple way: it learns one deep LSTM that goes from left to right, predicting word k using words 0-k-1, and a second LSTM that goes from right to left, predicting word k using words k+1 onward. These two predictions are combined (literally: just summed together) to get a representation for the word at position k. https://i.imgur.com/2329e3L.png BERT differs from prior work in this area in several small ways, but one primary one: instead of representing a word using only information from words before it, or a simple sum of prior information and subsequent information, it uses the full context from before and after the word in each of its multiple layers. It also uses an attention-based Transformer structure, but instead of incorporating just prior context, it pulls in information from the full sentence. To allow for a model that actually uses both directions of context at a time in its unsupervised prediction task, the authors of BERT slightly changed the nature of that task: it replaces the word being predicted with the “mask” token, so that even with multiple layers of context aggregation on both sides, the model doesn’t have any way of knowing what the token is. By contrast, if it weren’t masked, after the first layer of context aggregation, the representations of other words in the sequence would incorporate information about the predicted word k, making it trivial, if another layer were applied on top of that first one, for the model to directly have access to the value it’s trying to predict. This problem can either be solved by using multiple layers, each of which can only see prior context (like GPT), by learning fully separate L-R and R-L models, and combining them at the final layer (like ELMo) or by masking tokens, and predicting the value of the masked tokens using the full remainder of the context. This task design crucially allows for a multi-layered bidirectional architecture, and consequently a much richer representation of context in each word’s pre-trained representation. BERT demonstrates dramatic improvements over prior work when fine tuned on a small amount of supervised data, suggesting that this change added substantial value. |
Optimizing Agent Behavior over Long Time Scales by Transporting Value
Chia-Chun Hung and Timothy Lillicrap and Josh Abramson and Yan Wu and Mehdi Mirza and Federico Carnevale and Arun Ahuja and Greg Wayne
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG
First published: 2018/10/15 (5 years ago)
Abstract: Humans spend a remarkable fraction of waking life engaged in acts of "mental time travel". We dwell on our actions in the past and experience satisfaction or regret. More than merely autobiographical storytelling, we use these event recollections to change how we will act in similar scenarios in the future. This process endows us with a computationally important ability to link actions and consequences across long spans of time, which figures prominently in addressing the problem of long-term temporal credit assignment; in artificial intelligence (AI) this is the question of how to evaluate the utility of the actions within a long-duration behavioral sequence leading to success or failure in a task. Existing approaches to shorter-term credit assignment in AI cannot solve tasks with long delays between actions and consequences. Here, we introduce a new paradigm for reinforcement learning where agents use recall of specific memories to credit actions from the past, allowing them to solve problems that are intractable for existing algorithms. This paradigm broadens the scope of problems that can be investigated in AI and offers a mechanistic account of behaviors that may inspire computational models in neuroscience, psychology, and behavioral economics.
more
less
Chia-Chun Hung and Timothy Lillicrap and Josh Abramson and Yan Wu and Mehdi Mirza and Federico Carnevale and Arun Ahuja and Greg Wayne
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG
First published: 2018/10/15 (5 years ago)
Abstract: Humans spend a remarkable fraction of waking life engaged in acts of "mental time travel". We dwell on our actions in the past and experience satisfaction or regret. More than merely autobiographical storytelling, we use these event recollections to change how we will act in similar scenarios in the future. This process endows us with a computationally important ability to link actions and consequences across long spans of time, which figures prominently in addressing the problem of long-term temporal credit assignment; in artificial intelligence (AI) this is the question of how to evaluate the utility of the actions within a long-duration behavioral sequence leading to success or failure in a task. Existing approaches to shorter-term credit assignment in AI cannot solve tasks with long delays between actions and consequences. Here, we introduce a new paradigm for reinforcement learning where agents use recall of specific memories to credit actions from the past, allowing them to solve problems that are intractable for existing algorithms. This paradigm broadens the scope of problems that can be investigated in AI and offers a mechanistic account of behaviors that may inspire computational models in neuroscience, psychology, and behavioral economics.
|
[link]
This builds on the previous ["MERLIN"](https://arxiv.org/abs/1803.10760) paper. First they introduce the RMA agent, which is a simplified version of MERLIN which uses model based RL and long term memory. They give the agent long term memory by letting it choose to save and load the agent's working memory (represented by the LSTM's hidden state). Then they add credit assignment, similar to the RUDDER paper, to get the "Temporal Value Transport" (TVT) agent that can plan long term in the face of distractions. **The critical insight here is that they use the agent's memory access to decide on credit assignment**. So if the model uses a memory from 512 steps ago, that action from 512 steps ago gets lots of credit for the current reward. They use various tasks, for example a maze with a distracting task then a memory retrieval task. For example, after starting in a maze with, say, a yellow wall, the agent needs to collect apples. This serves as a distraction, ensuring the agent can recall memories even after distraction. At the end of the maze it needs to remember that initial color (e.g. yellow) in order to choose the exit of the correct color. They include performance graphs showing that memory or even better memory plus credit assignment are a significant help in this, and similar, tasks. |
Producing radiologist-quality reports for interpretable artificial intelligence
William Gale and Luke Oakden-Rayner and Gustavo Carneiro and Andrew P Bradley and Lyle J Palmer
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI
First published: 2018/06/01 (6 years ago)
Abstract: Current approaches to explaining the decisions of deep learning systems for medical tasks have focused on visualising the elements that have contributed to each decision. We argue that such approaches are not enough to "open the black box" of medical decision making systems because they are missing a key component that has been used as a standard communication tool between doctors for centuries: language. We propose a model-agnostic interpretability method that involves training a simple recurrent neural network model to produce descriptive sentences to clarify the decision of deep learning classifiers. We test our method on the task of detecting hip fractures from frontal pelvic x-rays. This process requires minimal additional labelling despite producing text containing elements that the original deep learning classification model was not specifically trained to detect. The experimental results show that: 1) the sentences produced by our method consistently contain the desired information, 2) the generated sentences are preferred by doctors compared to current tools that create saliency maps, and 3) the combination of visualisations and generated text is better than either alone.
more
less
William Gale and Luke Oakden-Rayner and Gustavo Carneiro and Andrew P Bradley and Lyle J Palmer
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI
First published: 2018/06/01 (6 years ago)
Abstract: Current approaches to explaining the decisions of deep learning systems for medical tasks have focused on visualising the elements that have contributed to each decision. We argue that such approaches are not enough to "open the black box" of medical decision making systems because they are missing a key component that has been used as a standard communication tool between doctors for centuries: language. We propose a model-agnostic interpretability method that involves training a simple recurrent neural network model to produce descriptive sentences to clarify the decision of deep learning classifiers. We test our method on the task of detecting hip fractures from frontal pelvic x-rays. This process requires minimal additional labelling despite producing text containing elements that the original deep learning classification model was not specifically trained to detect. The experimental results show that: 1) the sentences produced by our method consistently contain the desired information, 2) the generated sentences are preferred by doctors compared to current tools that create saliency maps, and 3) the combination of visualisations and generated text is better than either alone.
|
[link]
The paper presents a model-agnostic extension of deep learning classifiers based on a RNN with a visual attention mechanism for report generation.  One of the most important points in this paper is not the model, but the dataset they itself: Luke Oakden-Rayner, one of the authors, is a radiologist and worked a lot to educate the public on current medical datasets ([chest x-ray blog post](https://lukeoakdenrayner.wordpress.com/2017/12/18/the-chestxray14-dataset-problems/)), how they are made and what are the problems associated with them. In this paper they used 50,363 frontal pelvic X-rays, containing 4,010 hip fractures, the original dataset contained descriptive sentences, but these had highly inconsistent structure and content. A radiologist created a new set of sentences more appropriate to the task, from their [blog post](https://lukeoakdenrayner.wordpress.com/2018/06/05/explain-yourself-machine-producing-simple-text-descriptions-for-ai-interpretability/): > We simply created sentences with a fixed grammatical structure and a tiny vocabulary (26 words!). We stripped the task back to the simplest useful elements. For example: “There is a mildly displaced comminuted fracture of the left neck of the femur.” Using sentences like that we build a RNN to generate text*, on top of the detection model. >And that is the research in a nutshell! No fancy new models, no new maths or theoretical breakthroughs. Just sensible engineering to make the task tractable. This paper shows the importance of a well-built dataset in medical imaging and how it can thus lead to impressive results:  |

Everybody Dance Now
Caroline Chan and Shiry Ginosar and Tinghui Zhou and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.GR, cs.CV
First published: 2018/08/22 (5 years ago)
Abstract: This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We pose this problem as a per-frame image-to-image translation with spatio-temporal smoothing. Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject's appearance. We adapt this setup for temporally coherent video generation including realistic face synthesis. Our video demo can be found at https://youtu.be/PCBTZh41Ris .
more
less
Caroline Chan and Shiry Ginosar and Tinghui Zhou and Alexei A. Efros
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.GR, cs.CV
First published: 2018/08/22 (5 years ago)
Abstract: This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We pose this problem as a per-frame image-to-image translation with spatio-temporal smoothing. Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject's appearance. We adapt this setup for temporally coherent video generation including realistic face synthesis. Our video demo can be found at https://youtu.be/PCBTZh41Ris .
|
[link]
This paper presents a per-frame image-to-image translation system enabling copying of a motion of a person from a source video to a target person. For example, a source video might be a professional dancer performing complicated moves, while the target person is you. By utilizing this approach, it is possible to generate a video of you dancing as a professional. Check the authors' [video](https://www.youtube.com/watch?v=PCBTZh41Ris) for the visual explanation.
**Data preparation**
The authors have manually recorded high-resolution video ( at 120fps ) of a person performing various random moves. The video is further decomposed to frames, and person's pose keypoints (body joints, hands, face) are extracted for each frame. These keypoints are further connected to form a person stick figure. In practice, pose estimation is performed by open source project [OpenPose](https://github.com/CMU-Perceptual-Computing-Lab/openpose).
**Training**
https://i.imgur.com/VZCXZMa.png
Once the data is prepared the training is performed in two stages:
1. **Training pix2pixHD model with temporal smoothing**.
The core model is an original [pix2pixHD](https://tcwang0509.github.io/pix2pixHD/)[1] model with temporal smoothing. Specifically, if we were to use vanilla pix2pixHD, the input to the model would be a stick person image, and the target is the person's image corresponding to the pose. The network's objective would be $min_{G} (Loss1 + Loss2 + Loss3)$, where:
- $Loss1 = max_{D_1, D_2, D_3} \sum_{k=1,2,3} \alpha_{GAN}(G, D_k)$ is adverserial loss;
- $Loss2 = \lambda_{FM} \sum_{k=1,2,3} \alpha_{FM}(G,D_k)$ is feature matching loss;
- $Loss3 = \lambda_{VGG}\alpha_{VGG}(G(x),y)]$ is VGG perceptual loss.
However, this objective does not account for the fact that we want to generate video composed of frames that are temporally coherent. The authors propose to ensure *temporal smoothing* between adjacent frames by including pose, corresponding image, and generated image from the previous step (zero image for the first frame) as shown in the figure below:
https://i.imgur.com/0NSeBVt.png
Since the generated output $G(x_t; G(x_{t-1}))$ at time step $t$ is now conditioned on the previously generated frame $G(x_{t-1})$ as well as current stick image $x_t$, better temporal consistency is ensured. Consequently, the discriminator is now trying to determine both correct generation, as well as temporal consitency for a fake sequence $[x_{t-1}; x_t; G(x_{t-1}), G(x_t)]$.
2. **Training FaceGAN model**.
https://i.imgur.com/mV1xuMi.png
In order to improve face generation, the authors propose to use specialized FaceGAN. In practice, this is another smaller pix2pixHD model (with a global generator only, instead of local+global) which is fed with a cropped face area of a stick image and cropped face area of a corresponding generated image (from previous step 1) and aims to generate a residual which is added to the previously generated full image.
**Testing**
During testing, we extract frames from the input video, obtain pose stick image for each frame, normalize the stick pose image and feed it to pix2pixHD (with temporal consistency) and, further, to FaceGAN to produce final generated image with improved face features. Normalization is needed to capture possible pose variation between a source and a target input video.
**Remarks**
While this method produces a visually appealing result, it is not perfect. The are several reasons for being so:
1. *Quality of a pose stick image*: if the pose detector "misses" the keypoint, the generator might have difficulties to generate a properly rendered image;
2. *Motion blur*: motion blur causes pose detector to miss keypoints;
3. *Severe scale change*: if source person is very far, keypoint detector might fail to detect proper keypoints.
Among video rendering challenges, the authors mention self-occlusion, cloth texture generation, video jittering (training-test motion mismatch).
References:
[1] "High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs"
2 Comments
  |
Compositional Obverter Communication Learning From Raw Visual Input
Edward Choi and Angeliki Lazaridou and Nando de Freitas
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.CL, cs.LG, cs.NE
First published: 2018/04/06 (6 years ago)
Abstract: One of the distinguishing aspects of human language is its compositionality, which allows us to describe complex environments with limited vocabulary. Previously, it has been shown that neural network agents can learn to communicate in a highly structured, possibly compositional language based on disentangled input (e.g. hand- engineered features). Humans, however, do not learn to communicate based on well-summarized features. In this work, we train neural agents to simultaneously develop visual perception from raw image pixels, and learn to communicate with a sequence of discrete symbols. The agents play an image description game where the image contains factors such as colors and shapes. We train the agents using the obverter technique where an agent introspects to generate messages that maximize its own understanding. Through qualitative analysis, visualization and a zero-shot test, we show that the agents can develop, out of raw image pixels, a language with compositional properties, given a proper pressure from the environment.
more
less
Edward Choi and Angeliki Lazaridou and Nando de Freitas
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.CL, cs.LG, cs.NE
First published: 2018/04/06 (6 years ago)
Abstract: One of the distinguishing aspects of human language is its compositionality, which allows us to describe complex environments with limited vocabulary. Previously, it has been shown that neural network agents can learn to communicate in a highly structured, possibly compositional language based on disentangled input (e.g. hand- engineered features). Humans, however, do not learn to communicate based on well-summarized features. In this work, we train neural agents to simultaneously develop visual perception from raw image pixels, and learn to communicate with a sequence of discrete symbols. The agents play an image description game where the image contains factors such as colors and shapes. We train the agents using the obverter technique where an agent introspects to generate messages that maximize its own understanding. Through qualitative analysis, visualization and a zero-shot test, we show that the agents can develop, out of raw image pixels, a language with compositional properties, given a proper pressure from the environment.
|
[link]
This paper proposes a new training method for multi-agent communication settings. They show the following referential game: A speaker sees an image of a 3d rendered object and describes it to a listener. The listener sees a different image and must decide if it is the same object as described by the speaker (has the same color and shape). The game can only be completed successfully if a communication protocol emerges that can express the color and shape the speaker sees. The main contribution of the paper is the training algorithm. The speaker enumerates the message that would maximise its own understanding of the message given the image it sees (in a greedy way, symbol by symbol). The listener, given the image and the message, predicts a binary output and is trained using maximum likelihood given the correct answer. Only the listener is updating its parameters - therefore the speaker and listener change roles every number of rounds. They show that a compositional communication protocol has emerged and evaluate it using zero-shot tests. [Implemenation of this paper in pytorch](https://github.com/benbogin/obverter) |

Towards Robust Evaluations of Continual Learning
Sebastian Farquhar and Yarin Gal
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/05/24 (6 years ago)
Abstract: Continual learning experiments used in current deep learning papers do not faithfully assess fundamental challenges of learning continually, masking weak-points of the suggested approaches instead. We study gaps in such existing evaluations, proposing essential experimental evaluations that are more representative of continual learning's challenges, and suggest a re-prioritization of research efforts in the field. We show that current approaches fail with our new evaluations and, to analyse these failures, we propose a variational loss which unifies many existing solutions to continual learning under a Bayesian framing, as either 'prior-focused' or 'likelihood-focused'. We show that while prior-focused approaches such as EWC and VCL perform well on existing evaluations, they perform dramatically worse when compared to likelihood-focused approaches on other simple tasks.
more
less
Sebastian Farquhar and Yarin Gal
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/05/24 (6 years ago)
Abstract: Continual learning experiments used in current deep learning papers do not faithfully assess fundamental challenges of learning continually, masking weak-points of the suggested approaches instead. We study gaps in such existing evaluations, proposing essential experimental evaluations that are more representative of continual learning's challenges, and suggest a re-prioritization of research efforts in the field. We show that current approaches fail with our new evaluations and, to analyse these failures, we propose a variational loss which unifies many existing solutions to continual learning under a Bayesian framing, as either 'prior-focused' or 'likelihood-focused'. We show that while prior-focused approaches such as EWC and VCL perform well on existing evaluations, they perform dramatically worse when compared to likelihood-focused approaches on other simple tasks.
|
[link]
Through a likelihood-focused derivation of a variational inference (VI) loss, Variational Generative Experience Replay (VGER) presents the closest appropriate likelihood- focused alternative to Variational Continual Learning (VCL), the state-of the art prior-focused approach to continual learning.
In non continual learning, the aim is to learn parameters $\omega$ using labelled training data $\mathcal{D}$ to infer $p(y|\omega, x)$. In the continual learning context, instead, the data is not independently and identically distributed (i.i.d.), but may be split into separate tasks $\mathcal{D}_t = (X_t, Y_t)$ whose examples $x_t^{n_t}$ and $y_t^{n_t}$ are assumed to be i.i.d.
In \cite{Farquhar18}, as the loss at time $t$ cannot be estimated for previously discarded datasets, to approximate the distribution of past datasets $p_t(x,y)$, VGER (Variational Generative Experience Replay) trains a GAN $q_t(x, y)$ to produce ($\hat{x}, \hat{y}$) pairs for each class in each dataset as it arrives (generator is kept while data is discarded after each dataset is used). The variational free energy $\mathcal{F}_T$ is used to train on dataset $\mathcal{D}_T$ augmented with samples generated by the GAN. In this way the prior is set as the posterior approximation from the previous task.
|

Banach Wasserstein GAN
Jonas Adler and Sebastian Lunz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, math.FA
First published: 2018/06/18 (6 years ago)
Abstract: Wasserstein Generative Adversarial Networks (WGANs) can be used to generate realistic samples from complicated image distributions. The Wasserstein metric used in WGANs is based on a notion of distance between individual images, which induces a notion of distance between probability distributions of images. So far the community has considered $\ell^2$ as the underlying distance. We generalize the theory of WGAN with gradient penalty to Banach spaces, allowing practitioners to select the features to emphasize in the generator. We further discuss the effect of some particular choices of underlying norms, focusing on Sobolev norms. Finally, we demonstrate the impact of the choice of norm on model performance and show state-of-the-art inception scores for non-progressive growing GANs on CIFAR-10.
more
less
Jonas Adler and Sebastian Lunz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.LG, math.FA
First published: 2018/06/18 (6 years ago)
Abstract: Wasserstein Generative Adversarial Networks (WGANs) can be used to generate realistic samples from complicated image distributions. The Wasserstein metric used in WGANs is based on a notion of distance between individual images, which induces a notion of distance between probability distributions of images. So far the community has considered $\ell^2$ as the underlying distance. We generalize the theory of WGAN with gradient penalty to Banach spaces, allowing practitioners to select the features to emphasize in the generator. We further discuss the effect of some particular choices of underlying norms, focusing on Sobolev norms. Finally, we demonstrate the impact of the choice of norm on model performance and show state-of-the-art inception scores for non-progressive growing GANs on CIFAR-10.
|
[link]
The paper extends the [WGAN](http://www.shortscience.org/paper?bibtexKey=journals/corr/1701.07875) paper by replacing the L2 norm in the transportation cost by some other metric $d(x, y)$. By following the same reasoning as in the WGAN paper one arrives at a dual optimization problem similar to the WGAN's one except that the critic $f$ has to be 1-Lipschitz w.r.t. a given norm (rather than L2). This, in turn, means that critic's gradient (w.r.t. input $x$) has to be bounded in the dual norm (only in Banach spaces, hence the name). Authors build upon the [WGAN-GP](http://www.shortscience.org/paper?bibtexKey=journals/corr/1704.00028) to incorporate similar gradient penalty term to force critic's constraint.
In particular authors choose [Sobolev norm](https://en.wikipedia.org/wiki/Sobolev_space#Multidimensional_case):
$$
||f||_{W^{s,p}} = \left( \int \sum_{k=0}^s ||\nabla^k f(x)||_{L_p}^p dx \right)^{1 / p}
$$
This norm is chosen because it not only forces pixel values to be close, but also the gradients to be close as well. The gradients are small when you have smooth texture, and big on the edges -- so this loss can regulate how much you care about the edges. Alternatively, you could express the same norm by first transforming the $f$ using the Fourier Transform, then multiplying the result by $1 + ||x||_{L_2}^2$ pointwise, and then transforming it back and integrating over the whole space:
$$
||f||_{W^{s,p}} = \left( \int \left( \mathcal{F}^{-1} \left[ (1 + ||x||_{L_2}^2)^{s/2} \mathcal{F}[f] (x) \right] (x) \right)^p dx \right)^{1 / p}
$$
Here $f(x)$ would be image pixels intensities, and $x$ would be image coordinates, so $\nabla^k f(x)$ would be spatial gradient -- the one you don't have access to, and it's a bit hard to estimate one with finite differences, so the authors go for the second -- fourier -- option. Luckily, a DFT transform is just a linear operator, and fast implementations exists, so you can backpropagate through it (TensorFlow already includes tf.spectal)
Authors perform experiments on CIFAR and report state-of-the-art non-progressive results in terms of Inception Score (though not beating SNGANs by a statistically significant margin). The samples they present, however, are too small to tell if the network really cared about the edges.
|

A Comparison of Word Embeddings for the Biomedical Natural Language Processing
Yanshan Wang and Sijia Liu and Naveed Afzal and Majid Rastegar-Mojarad and Liwei Wang and Feichen Shen and Paul Kingsbury and Hongfang Liu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.IR
First published: 2018/02/01 (6 years ago)
Abstract: Neural word embeddings have been widely used in biomedical Natural Language Processing (NLP) applications as they provide vector representations of words capturing the semantic properties of words and the linguistic relationship between words. Many biomedical applications use different textual resources (e.g., Wikipedia and biomedical articles) to train word embeddings and apply these word embeddings to downstream biomedical applications. However, there has been little work on evaluating the word embeddings trained from these resources.In this study, we provide an empirical evaluation of word embeddings trained from four different resources, namely clinical notes, biomedical publications, Wikipedia, and news. We performed the evaluation qualitatively and quantitatively. In qualitative evaluation, we manually inspected five most similar medical words to a given set of target medical words, and then analyzed word embeddings through the visualization of those word embeddings. In quantitative evaluation, we conducted both intrinsic and extrinsic evaluation. Based on the evaluation results, we can draw the following conclusions. First, the word embeddings trained on EHR and PubMed can capture the semantics of medical terms better than those trained on GloVe and Google News and find more relevant similar medical terms, and are closer to human experts' judgments, compared to these trained on GloVe and Google News. Second, there does not exist a consistent global ranking of word embedding quality for downstream biomedical NLP applications. However, adding word embeddings as extra features will improve results on most downstream tasks. Finally, the word embeddings trained on biomedical domain corpora do not necessarily have better performance than those trained on other general domain corpora for any downstream biomedical NLP tasks.
more
less
Yanshan Wang and Sijia Liu and Naveed Afzal and Majid Rastegar-Mojarad and Liwei Wang and Feichen Shen and Paul Kingsbury and Hongfang Liu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.IR
First published: 2018/02/01 (6 years ago)
Abstract: Neural word embeddings have been widely used in biomedical Natural Language Processing (NLP) applications as they provide vector representations of words capturing the semantic properties of words and the linguistic relationship between words. Many biomedical applications use different textual resources (e.g., Wikipedia and biomedical articles) to train word embeddings and apply these word embeddings to downstream biomedical applications. However, there has been little work on evaluating the word embeddings trained from these resources.In this study, we provide an empirical evaluation of word embeddings trained from four different resources, namely clinical notes, biomedical publications, Wikipedia, and news. We performed the evaluation qualitatively and quantitatively. In qualitative evaluation, we manually inspected five most similar medical words to a given set of target medical words, and then analyzed word embeddings through the visualization of those word embeddings. In quantitative evaluation, we conducted both intrinsic and extrinsic evaluation. Based on the evaluation results, we can draw the following conclusions. First, the word embeddings trained on EHR and PubMed can capture the semantics of medical terms better than those trained on GloVe and Google News and find more relevant similar medical terms, and are closer to human experts' judgments, compared to these trained on GloVe and Google News. Second, there does not exist a consistent global ranking of word embedding quality for downstream biomedical NLP applications. However, adding word embeddings as extra features will improve results on most downstream tasks. Finally, the word embeddings trained on biomedical domain corpora do not necessarily have better performance than those trained on other general domain corpora for any downstream biomedical NLP tasks.
|
[link]
This paper demonstrates that Word2Vec \cite{1301.3781} can extract relationships between words and produce latent representations useful for medical data. They explore this model on different datasets which yield different relationships between words.
https://i.imgur.com/hSA61Zw.png
The Word2Vec model works like an autoencoder that predicts the context of a word. The context of a word is composed of the surrounding words as shown below. Given the word in the center the neighboring words are predicted through a bottleneck in the autoencoder. A word has many contexts in a corpus so the model can never have 0 error. The model must minimize the reconstruction which is how it learns the latent representation.
https://i.imgur.com/EMtjTHn.png
Subjectively we can observe the relationship between word vectors:
https://i.imgur.com/8C9EVq1.png
|
Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
David Acuna and Huan Ling and Amlan Kar and Sanja Fidler
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/26 (6 years ago)
Abstract: Manually labeling datasets with object masks is extremely time consuming. In this work, we follow the idea of Polygon-RNN to produce polygonal annotations of objects interactively using humans-in-the-loop. We introduce several important improvements to the model: 1) we design a new CNN encoder architecture, 2) show how to effectively train the model with Reinforcement Learning, and 3) significantly increase the output resolution using a Graph Neural Network, allowing the model to accurately annotate high-resolution objects in images. Extensive evaluation on the Cityscapes dataset shows that our model, which we refer to as Polygon-RNN++, significantly outperforms the original model in both automatic (10% absolute and 16% relative improvement in mean IoU) and interactive modes (requiring 50% fewer clicks by annotators). We further analyze the cross-domain scenario in which our model is trained on one dataset, and used out of the box on datasets from varying domains. The results show that Polygon-RNN++ exhibits powerful generalization capabilities, achieving significant improvements over existing pixel-wise methods. Using simple online fine-tuning we further achieve a high reduction in annotation time for new datasets, moving a step closer towards an interactive annotation tool to be used in practice.
more
less
David Acuna and Huan Ling and Amlan Kar and Sanja Fidler
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/26 (6 years ago)
Abstract: Manually labeling datasets with object masks is extremely time consuming. In this work, we follow the idea of Polygon-RNN to produce polygonal annotations of objects interactively using humans-in-the-loop. We introduce several important improvements to the model: 1) we design a new CNN encoder architecture, 2) show how to effectively train the model with Reinforcement Learning, and 3) significantly increase the output resolution using a Graph Neural Network, allowing the model to accurately annotate high-resolution objects in images. Extensive evaluation on the Cityscapes dataset shows that our model, which we refer to as Polygon-RNN++, significantly outperforms the original model in both automatic (10% absolute and 16% relative improvement in mean IoU) and interactive modes (requiring 50% fewer clicks by annotators). We further analyze the cross-domain scenario in which our model is trained on one dataset, and used out of the box on datasets from varying domains. The results show that Polygon-RNN++ exhibits powerful generalization capabilities, achieving significant improvements over existing pixel-wise methods. Using simple online fine-tuning we further achieve a high reduction in annotation time for new datasets, moving a step closer towards an interactive annotation tool to be used in practice.
|
[link]
In this paper, the authors develop a system for automatic as well as an interactive annotation (i.e. segmentation) of a dataset. In the automatic mode, bounding boxes are generated by another network (e.g. FasterRCNN), while in the interactive mode, the input bounding box around an object of interest comes from the human in the loop. The system is composed of the following parts: https://github.com/davidjesusacu/polyrnn-pp/raw/master/readme/model.png 1. **Residual encoder with skip connections**. This step acts as a feature extractor. The ResNet-50 with few modifications (i.e. reducing stride, usage of dilation, removal of average pooling and FC layers) serve as a base CNN encoder. Instead of utilizing the last features of the network, the authors concatenate outputs from different layers - resized to highest feature resolution - to capture multi-level representations. This is shown in the figure below: https://www.groundai.com/media/arxiv_projects/226090/x4.png.750x0_q75_crop.png 2. **Recurrent decoder** is a two-layer ConvLSTM which takes image features, previous (or first) vertex position and outputs one-hot encoding of 28x28 representing possible vertex position, +1 indicates that the polygon is closed (i.e. the end of the sequence). Attention weight per location is utilized using CNN features, 1st and 2nd layers of ConvLSTM. Training is formulated as reinforcement learning since recurrent decoder is considered as sequential decision-making agent. The reward function is IoU between mask generated by the enclosed polygon and ground-truth mask. 3. **Evaluator network** chooses the best polygon among multiple candidates. CNN features, last state tensor of ConvLSTM, and the predicted polygon are used as input, and the output is the predicted IoU. The best polygon is selected from the polygons which are generated using 5 top scoring first vertex predictions. https://i.imgur.com/84amd98.png 4. **Upscaling with Graph Neural Network** takes the list of vertices generated by ConvLSTM decode, adds a node in between two consecutive nodes (to produce finer details at higher resolution), and aims to predict relative offset of each node at a higher resolution. Specifically, it extracts features around every predicted vertex and forwards it through GGNN (Gated Graph Neural Network) to obtain the final location (i.e. offset) of the vertex (treated as classification task). https://www.groundai.com/media/arxiv_projects/226090/x5.png.750x0_q75_crop.png The whole system is not trained end-to-end. While the network was trained on CityScapes dataset, it has shown reasonable generalization to different modalities (e.g. medical data). It would be very nice to observe the opposite generalization of the model. Meaning you train on medical data and see how it performs on CityScapes data. |
The challenge of realistic music generation: modelling raw audio at scale
Sander Dieleman and Aäron van den Oord and Karen Simonyan
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.SD, cs.LG, eess.AS, stat.ML
First published: 2018/06/26 (6 years ago)
Abstract: Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
more
less
Sander Dieleman and Aäron van den Oord and Karen Simonyan
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.SD, cs.LG, eess.AS, stat.ML
First published: 2018/06/26 (6 years ago)
Abstract: Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
|
[link]
This paper draws from two strains of recent work: the hierarchical music modeling of MusicVAE - which intentionally model musical structure at both local and more global levels - , and the discrete autoencoder approaches of Vector Quantized VAEs - which seek to maintain the overall structure of a VAE, but apply a less aggressive form of regularization. The goal of this paper is to build a model that can generate music, not from that music’s symbolic representation - lists of notes - but from actual waveform audio. This is a more difficult task because the model now has to learn mappings between waveforms and symbolic notes, but confers the advantage of being able to model expressive dimensions of music that are difficult to capture in a pure symbolic representation. Models of pure waveform data have been used before - Wavenet is a central example - but typically they are learned alongside some kind of text conditioning structure, which is to say, you tell the model to say “Hello there, world” and the model is only responsible for building local mappings between those phonemes and waveforms, not actually modeling coherent words to follow after “Hello”. To try to address this problem, the authors of the paper propose the solution of learning an autoencoded representation over the full music sample, to try to capture global structure. Each predicted value of the global structure sequence then represents some number of timesteps of the generated sequence: say, 20. The idea here is: learn a global model that produces 1/N (1/20, in this case) fewer sequence points, whose job is ensuring long term consistency. Then, the authors also suggest the use of a lower level decoder model that uses the conditioning information from the autoencoder, and, in a similar fashion to a text to speech wavenet, captures a high fidelity mapping between that conditioning and the output waveform. This overall structure has a lot in common with the recently released MusicVAE paper. The most salient architectural change proposed by this paper is that of Argmax VAEs, rather than VQ VAEs. Overall, the reason for training discrete autoencoders is to have a more easily adjustable way of regularizing the bottlenecked representation, to avoid the fact that for some challenging problems, excessively strong VAE regularization can lead to that high level representational space just not being used. To understand the difference, it’s worth understanding that VQ VAEs work by generating a continuous encoding vector (the same as a typical VAE) but then instead of passing that continuous vector itself directly on to the decoder, the VQ VAE instead fits what is basically a K means operation: it maps the continuous vector to one of it’s “prototypical” or “codebook” vectors based on closeness in Euclidean distance (these codebook vectors are learned in a separate trading loop, in a K Means style algorithm). The Argmax VAE is similar, but instead of needing to take that alternating step of learning the codebook vectors via K Means, it performs a much simpler quantization operation: just taking the argmax of indices across the continuous vector, so that the output is the one-hot vector closest to the continuous input. While this reduces the capacity of the model, it also limits the problem of “codebook collapse”, which is a failure mode that can happen during the K Means iteration (I’m actually not entirely clear on the prototypical example of codebook collapse, or exactly why it happens). https://i.imgur.com/H5YqSZG.png Combining these ideas together: this paper’s model works by learning an Argmax VAE over a larger and courser timeframe of the model, and then learning a local, high resolution decoder - similar to Wavenet - over the smaller time scales, conditioned on the output of the Argmax VAE making high level decisions. This combination balances the needs of coherent musical structure and local fidelity, and allows for different weighing of those trade-offs in a fairly flexible way, by changing the frequency at which you produce Argmax VAE conditioning output. |
Quasi-Monte Carlo Variational Inference
Alexander Buchholz and Florian Wenzel and Stephan Mandt
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/07/04 (6 years ago)
Abstract: Many machine learning problems involve Monte Carlo gradient estimators. As a prominent example, we focus on Monte Carlo variational inference (MCVI) in this paper. The performance of MCVI crucially depends on the variance of its stochastic gradients. We propose variance reduction by means of Quasi-Monte Carlo (QMC) sampling. QMC replaces N i.i.d. samples from a uniform probability distribution by a deterministic sequence of samples of length N. This sequence covers the underlying random variable space more evenly than i.i.d. draws, reducing the variance of the gradient estimator. With our novel approach, both the score function and the reparameterization gradient estimators lead to much faster convergence. We also propose a new algorithm for Monte Carlo objectives, where we operate with a constant learning rate and increase the number of QMC samples per iteration. We prove that this way, our algorithm can converge asymptotically at a faster rate than SGD. We furthermore provide theoretical guarantees on QMC for Monte Carlo objectives that go beyond MCVI, and support our findings by several experiments on large-scale data sets from various domains.
more
less
Alexander Buchholz and Florian Wenzel and Stephan Mandt
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG
First published: 2018/07/04 (6 years ago)
Abstract: Many machine learning problems involve Monte Carlo gradient estimators. As a prominent example, we focus on Monte Carlo variational inference (MCVI) in this paper. The performance of MCVI crucially depends on the variance of its stochastic gradients. We propose variance reduction by means of Quasi-Monte Carlo (QMC) sampling. QMC replaces N i.i.d. samples from a uniform probability distribution by a deterministic sequence of samples of length N. This sequence covers the underlying random variable space more evenly than i.i.d. draws, reducing the variance of the gradient estimator. With our novel approach, both the score function and the reparameterization gradient estimators lead to much faster convergence. We also propose a new algorithm for Monte Carlo objectives, where we operate with a constant learning rate and increase the number of QMC samples per iteration. We prove that this way, our algorithm can converge asymptotically at a faster rate than SGD. We furthermore provide theoretical guarantees on QMC for Monte Carlo objectives that go beyond MCVI, and support our findings by several experiments on large-scale data sets from various domains.
|
[link]
Variational Inference builds around the ELBO (Evidence Lower BOund) -- a lower bound on a marginal log-likelihood of the observed data $\log p(x) = \log \int p(x, z) dz$ (which is typically intractable). The ELBO makes use of an approximate posterior to form a lower bound:
$$
\log p(x) \ge \mathbb{E}_{q(z|x)} \log \frac{p(x, z)}{q(z|x)}
$$
# Introduction to Quasi Monte Carlo
It's assumed that both the join $p(x, z)$ (or, equivalently the likelihood $p(x|z)$ and the prior $p(z)$) and the approximate posterior $q(z|x)$ are tractable (have closed-form density and are easy to sample from). Then one can estimate the ELBO via Monte Carlo as
$$
\text{ELBO} \approx \frac{1}{N} \sum_{n=1}^N \log \frac{p(x, z_n)}{q(z_n|x)}, \quad\quad z_n \sim q(z|x)
$$
This estimate can be used in stochastic optimization, essentially stochastically maximizing the ELBO, which leads to either increasing marginal log-likelihood or decreasing the gap between the true posterior distribution $p(z|x)$ and the approximate one $q(z|x)$.
Efficiency of stochastic optimization depends on the amount of stochasticity. The bigger the variance is -- the harder it's to locate the optimum. It's well-known that in typical Monte Carlo variance scales as 1/N for a sample of size N, and hence typical error of such "approximation" has an order of $1/\sqrt{N}$
However, there are more efficient schemes to evaluate the integrals of the form of the expectation. To give you some intuition, consider
$$ \mathbb{E}_{q(z)} f(z) = \int_\mathcal{Z} f(z) q(z) dz = \int_{[0, 1]^d} f(z(u)) du $$
Here I used the fact that any random variance can be expressed as a deterministic transformation of a uniform r.v. (by application of the inverse CDF of the former r.v.), so estimating the expectation using MC essentially means sampling a bunch of uniform r.v. $u_1, \dots, u_N$ and transforming them into the corresponding $z$s. However, uniformly distributed random variables sometimes clump together and leave some areas uncovered:
https://i.imgur.com/fejsl2t.png
Low Discrepancy sequences are designed to cover the unit cube more uniformly in a sense that points are unlikely to clump and should not leave "holes" in the landscape, effectively facilitating a better exploration. The Quasi Monte Carlo then employs these sequences to evaluate the integral at, giving (a deterministic!) approximation with an error of an order $\tfrac{(\log N)^d}{N}$. If you want some randomness, there are clever randomization techniques, that give you Randomized Quasi Monte Carlo with roughly the same guarantees.
# RQMC applied to VI
Authors estimate the ELBO using samples obtained from the Randomized QMC (scrambled Sobol sequence, in particular), and show experimentally that this leads to lower gradient variance and faster convergence.
# Theoretical Properties
Authors also analyse Stochastic Gradient Descent with RQMC and prove several convergence theorems. To the best of my knowledge, this is the first work considering stochastic optimization using QMC (which is understandable given that one needs to be able to control the gradients to do so)
# Critique
The paper was a great read, and spurred a great interest in me. I find the idea of using QMC very intriguing, however in my opinion there are several problems on the road to mass-adoption
1. Authors use RQMC to get the stochastic nature of $z_n$, however that essentially changes the effective distribution of generated $z$, which should be accounted for in the ELBO, otherwise the objective they're maximizing is not an ELBO (if only asymptotically) and hence not necessary a lower bound on the marginal log-likelihood. However, finding the correct proposal density $q(z|x)$ (and successfully using it) does not seem easy as most randomization schemes give you degenerate support, and KL is not well-defined.
2. Authors have an experiment on a Bayesian Neural Network, however a very small one, there are reasons to doubt their results will translate to real ones, as the positive effect of QMC vanishes as dimension grows (because it's harder for uniform samples to clump together)
3. Standard control variates might no longer reduce the variance, further research is needed.
1 Comments
 |
Insights on representational similarity in neural networks with canonical correlation
Ari S. Morcos and Maithra Raghu and Samy Bengio
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.CV, cs.LG, cs.NE
First published: 2018/06/14 (6 years ago)
Abstract: Comparing different neural network representations and determining how representations evolve over time remain challenging open questions in our understanding of the function of neural networks. Comparing representations in neural networks is fundamentally difficult as the structure of representations varies greatly, even across groups of networks trained on identical tasks, and over the course of training. Here, we develop projection weighted CCA (Canonical Correlation Analysis) as a tool for understanding neural networks, building off of SVCCA, a recently proposed method. We first improve the core method, showing how to differentiate between signal and noise, and then apply this technique to compare across a group of CNNs, demonstrating that networks which generalize converge to more similar representations than networks which memorize, that wider networks converge to more similar solutions than narrow networks, and that trained networks with identical topology but different learning rates converge to distinct clusters with diverse representations. We also investigate the representational dynamics of RNNs, across both training and sequential timesteps, finding that RNNs converge in a bottom-up pattern over the course of training and that the hidden state is highly variable over the course of a sequence, even when accounting for linear transforms. Together, these results provide new insights into the function of CNNs and RNNs, and demonstrate the utility of using CCA to understand representations.
more
less
Ari S. Morcos and Maithra Raghu and Samy Bengio
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.CV, cs.LG, cs.NE
First published: 2018/06/14 (6 years ago)
Abstract: Comparing different neural network representations and determining how representations evolve over time remain challenging open questions in our understanding of the function of neural networks. Comparing representations in neural networks is fundamentally difficult as the structure of representations varies greatly, even across groups of networks trained on identical tasks, and over the course of training. Here, we develop projection weighted CCA (Canonical Correlation Analysis) as a tool for understanding neural networks, building off of SVCCA, a recently proposed method. We first improve the core method, showing how to differentiate between signal and noise, and then apply this technique to compare across a group of CNNs, demonstrating that networks which generalize converge to more similar representations than networks which memorize, that wider networks converge to more similar solutions than narrow networks, and that trained networks with identical topology but different learning rates converge to distinct clusters with diverse representations. We also investigate the representational dynamics of RNNs, across both training and sequential timesteps, finding that RNNs converge in a bottom-up pattern over the course of training and that the hidden state is highly variable over the course of a sequence, even when accounting for linear transforms. Together, these results provide new insights into the function of CNNs and RNNs, and demonstrate the utility of using CCA to understand representations.
|
[link]
The overall goal of the paper is measure how similar different layer activation profiles are to one another, in hopes of being able to quantify the similarity of the representations that different layers are learning. If you had a measure that captured this, you could ask questions like: “how similar are the representations that are learned by different networks on the same task”, and “what is the dynamic of representational change in a given layer throughout training”? Canonical Correlation Analysis is one way of approaching this question, and the way taken by this paper. The premise of CCA is that you have two multidimensional variable sets, where each set is made up of vectors representing dimensions within that variable set. Concretely, in this paper, the sets under examination are the activation profiles of two layers (either the same layer at different points in training, or different layers in the same network, or layers in different networks). An activation profile is thought of in terms of multiple vectors, where each vector represents a given neuron’s activation value, evaluated over some observation set X. Importantly, for the two layers that you’re comparing, the set of observations X needs to be of the same length, but the layers can have different number of neurons (and, consequently, different numbers of vectors making up that layer’s multivariate set). Given this setup, the goal of CCA is to find vectors that are linear combinations of the basis vectors of each set, to satisfy some constraint. In that broad sense, this is similar to the project of PCA, which also constructs linear-combination principal components to better represent the underlying data space. However, in PCA, the constraints that define these combinations are based on one multidimensional feature space, not two. In CCA, instead of generating k principal components, you generate k *pairs* of canonical correlates. Each canonical correlate pair, (U1, V1) is a linear combination of the activation vectors of sets L1 and L2 respectively, and is chosen with the goal of minimizing the the angle (cosine) distance between the correlates in each pair. If you think about L1 and L2 each only having two activations (that is: if you think about them as being two-dimensional spaces) then the goal of CCA is to find the cosine distance between the planes defined by the two activation spaces. An important intuition here is that in this framing, vector sets that are just linear transformations of one another (scalings, rotations, swaps in the arbitrary order of activations) will look the same, which wouldn’t be the case if you just looked at raw correlations between the individual activations. This is connected to the linear algebra idea that, if you have two vectors, and a third that is just a linear combination of the first two, the span of those vectors is still just that two-dimensional space. This property is important for the analysis of neural network representations because it means it will be able to capture similarities between representational spaces that have fundamental geometric similarities, even if they’re different on a more surface level. In prior papers, CCA had been used by calculating the CCA vectors between varying sets of layers, and then taking the mean CCA value over all of the pairs of vectors. This paper argues against that approach, on the theory that network layers are probably not using the full representational capacity of their activation dimensions (think, as analogy: a matrix with three columns, that only actually spans two), and so including in your average very low-order correlations is mostly adding uninformative noise to your similarity measure. Instead, this paper weights the correlation coefficients according to the magnitudes of the correlate vectors in the pair; as best I can tell, this is roughly analogous to weighting according to eigenvalues, in a PCA setting. Using this weighted-average similarity measure, the authors do some really interesting investigations into learning dynamics. These include: * Comparing the intermediate-layer representations learned by networks that achieve low train error via memorization vs via actually-generalizing solutions, and show that, during training, the intermediate representations of generalizing networks are more similar to one another than memorizing networks are to one another. Intuitively, this aligns with the idea that there are many ways to noisily memorize, but a more constrained number of ways to actually learn meaningful information about a dataset. A super interesting implication of this is the idea that representational similarity *on the training set* across multiple bootstrapped or randomized trainings could be used as a proxy for test set performance, which could be particularly valuable in contexts where test data is limited https://i.imgur.com/JwyHFmN.png * Across networks, lower layers tend to be more similar to one another than layers closer to the output; said another way, the very simple (e.g. edge detectors) tend to be quite similar across networks, but the higher level representations are more divergent and influenceable by smaller quirks of the training set. * Within a given dataset, you can cluster learned internal representations across many training sets and recover groups trained with the same learning rate, even though the final layer softmax is inherently similar across models that achieve the same training error. This implies that metrics like this can give us some idea of the different minima that the optimization algorithm finds, as a function of different learning rates. Overall, I found this paper a great example of a straightforward idea used to clearly answer important and interesting questions, which is always refreshing amidst a sea of “tiny hack for an extra 0.05 accuracy”. |
BRUNO: A Deep Recurrent Model for Exchangeable Data
Iryna Korshunova and Jonas Degrave and Ferenc Huszár and Yarin Gal and Arthur Gretton and Joni Dambre
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML
First published: 2018/02/21 (6 years ago)
Abstract: We present a novel model architecture which leverages deep learning tools to perform exact Bayesian inference on sets of high dimensional, complex observations. Our model is provably exchangeable, meaning that the joint distribution over observations is invariant under permutation: this property lies at the heart of Bayesian inference. The model does not require variational approximations to train, and new samples can be generated conditional on previous samples, with cost linear in the size of the conditioning set. The advantages of our architecture are demonstrated on learning tasks that require generalisation from short observed sequences while modelling sequence variability, such as conditional image generation, few-shot learning, and anomaly detection.
more
less
Iryna Korshunova and Jonas Degrave and Ferenc Huszár and Yarin Gal and Arthur Gretton and Joni Dambre
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML
First published: 2018/02/21 (6 years ago)
Abstract: We present a novel model architecture which leverages deep learning tools to perform exact Bayesian inference on sets of high dimensional, complex observations. Our model is provably exchangeable, meaning that the joint distribution over observations is invariant under permutation: this property lies at the heart of Bayesian inference. The model does not require variational approximations to train, and new samples can be generated conditional on previous samples, with cost linear in the size of the conditioning set. The advantages of our architecture are demonstrated on learning tasks that require generalisation from short observed sequences while modelling sequence variability, such as conditional image generation, few-shot learning, and anomaly detection.
|
[link]
If one is a Bayesian he or she best expresses beliefs about next observation $x_{n+1}$ after observing $x_1, \dots, x_n$ using the **posterior predictive distribution**: $p(x_{n+1}\vert x_1, \dots, x_n)$. Typically one invokes the de Finetti theorem and assumes there exists an underlying model $p(x\vert\theta)$, hence $p(x_{n+1}\vert x_1, \dots, x_n) = \int p(x_{n+1} \vert \theta) p(\theta \vert x_1, \dots, x_n) d\theta$, however this integral is far from tractable in most cases. Nevertheless, having tractable posterior predictive is useful in cases like few-shot generative learning where we only observe a few instances of a given class and are asked to produce more of it.
In this paper authors take a slightly different approach and build a neural model with tractable posterior predictive distribution $p(x_{n+1} | x_1, \dots, x_n)$ suited for complex objects like images. In order to do so the authors take a simple model with tractable posterior predictive $p(z_{n+1} | z_1, \dots, z_n)$ (like a Gaussian Process, but not quite) and use it as a latent code, which is obtained from observations using an analytically inversible encoder $f$. This setup lets you take a complex $x$ like an image, run it through $f$ to obtain $z = f(x)$ -- a simplified latent representation for which it's easier to build joint density of all possible representations and hence easier to model the posterior predictive. By feeding latent representations of $x_1, \dots, x_n$ (namely, $z_1, \dots, z_n$) to the posterior predictive $p(z_{n+1} | f(x_1), \dots, f(x_n))$ we obtain obtain a distribution of latent representations that are coherent with those of already observed $x$s. By sampling $z$ from this distribution and running it through $f^{-1}$ we recover an object in the observation space, $x_\text{pred} = f^{-1}(z)$ -- a sample most coherent with previous observations.
Important choices are:
* Model for latent representations $z$: one could use Gaussian Process, however authors claim it lacks some helpful properties and go for a more general [Student-T Process](http://www.shortscience.org/paper?bibtexKey=journals/corr/1402.4306). Then authors assume that each component of $z$ is a univariate sample from this process (and hence is independent from other components)
* Encoder $f$. It has to be easily inversible and have an easy-to-evaluate Jacobian (the determinant of the Jacobi matrix). The former is needed to perform decoding of predictions in latent representations space and the later is used to efficiently compute a density of observations $p(x_1, \dots, x_n)$ using the standard change of variables formula $$p(x_1, \dots, x_n) = p(z_1, \dots, z_n) \left\vert\text{det} \frac{\partial f(x)}{\partial x} \right\vert$$The architecture of choice for this task is [RealNVP](http://www.shortscience.org/paper?bibtexKey=journals/corr/1605.08803)
Done this way, it's possible to write out the marginal density $p(x_1, \dots, x_n)$ on all the observed $x$s and maximize it (as in the Maximum Likelihood Estimation). Authors choose to factor the joint density in an auto-regressive fashion (via the chain rule) $$p(x_1, \dots, x_n) = p(x_1) p(x_2 \vert x_1) p(x_3 \vert x_1, x_2) \dots p(x_n \vert x_1, \dots, x_{n-1}) $$with all the conditional marginals $p(x_i \vert x_1, \dots, x_{i-1})$ having analytic (student t times the jacobian) density -- this allows one to form a fully differentiable recurrent computation graph whose parameters (parameters of Student Processes for each component of $z$ + parameters of the encoder $f$) to be learned using any stochastic gradient method.
https://i.imgur.com/yRrRaMs.png
|
Actor and Action Video Segmentation from a Sentence
Kirill Gavrilyuk and Amir Ghodrati and Zhenyang Li and Cees G. M. Snoek
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/20 (6 years ago)
Abstract: This paper strives for pixel-level segmentation of actors and their actions in video content. Different from existing works, which all learn to segment from a fixed vocabulary of actor and action pairs, we infer the segmentation from a natural language input sentence. This allows to distinguish between fine-grained actors in the same super-category, identify actor and action instances, and segment pairs that are outside of the actor and action vocabulary. We propose a fully-convolutional model for pixel-level actor and action segmentation using an encoder-decoder architecture optimized for video. To show the potential of actor and action video segmentation from a sentence, we extend two popular actor and action datasets with more than 7,500 natural language descriptions. Experiments demonstrate the quality of the sentence-guided segmentations, the generalization ability of our model, and its advantage for traditional actor and action segmentation compared to the state-of-the-art.
more
less
Kirill Gavrilyuk and Amir Ghodrati and Zhenyang Li and Cees G. M. Snoek
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/20 (6 years ago)
Abstract: This paper strives for pixel-level segmentation of actors and their actions in video content. Different from existing works, which all learn to segment from a fixed vocabulary of actor and action pairs, we infer the segmentation from a natural language input sentence. This allows to distinguish between fine-grained actors in the same super-category, identify actor and action instances, and segment pairs that are outside of the actor and action vocabulary. We propose a fully-convolutional model for pixel-level actor and action segmentation using an encoder-decoder architecture optimized for video. To show the potential of actor and action video segmentation from a sentence, we extend two popular actor and action datasets with more than 7,500 natural language descriptions. Experiments demonstrate the quality of the sentence-guided segmentations, the generalization ability of our model, and its advantage for traditional actor and action segmentation compared to the state-of-the-art.
|
[link]
This paper performs pixel-wise segmentation of the object of interest which is specified by a sentence. The model is composed of three main components: a **textual encoder**, a **video encoder**, and a **decoder**.https://i.imgur.com/gjbHNqs.png - **Textual encoder** is word2vec pre-trained model followed by 1D CNN. - **Video encoder** is a 3D CNN to obtain a visual representation of the video (can be combined with optical flow to obtain motion information). - **Decoder**. Given a sentence representation $T$ a separate filter $f^r = tanh(W^r_fT + b^r_f)$ is created to match each feature map in the video frame decoder and combined with visual features as $S^r_t = f^r * V^r_t$, for each $r$esolution at $t$imestep. The decoder is composed of sequence of transpose convolution layers to get the response map of the same size as the input video frame. |
Taskonomy: Disentangling Task Transfer Learning
Amir Zamir and Alexander Sax and William Shen and Leonidas Guibas and Jitendra Malik and Silvio Savarese
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.AI, cs.LG, cs.NE, cs.RO
First published: 2018/04/23 (6 years ago)
Abstract: Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a structure among visual tasks. Knowing this structure has notable values; it is the concept underlying transfer learning and provides a principled way for identifying redundancies across tasks, e.g., to seamlessly reuse supervision among related tasks or solve many tasks in one system without piling up the complexity. We proposes a fully computational approach for modeling the structure of space of visual tasks. This is done via finding (first and higher-order) transfer learning dependencies across a dictionary of twenty six 2D, 2.5D, 3D, and semantic tasks in a latent space. The product is a computational taxonomic map for task transfer learning. We study the consequences of this structure, e.g. nontrivial emerged relationships, and exploit them to reduce the demand for labeled data. For example, we show that the total number of labeled datapoints needed for solving a set of 10 tasks can be reduced by roughly 2/3 (compared to training independently) while keeping the performance nearly the same. We provide a set of tools for computing and probing this taxonomical structure including a solver that users can employ to devise efficient supervision policies for their use cases.
more
less
Amir Zamir and Alexander Sax and William Shen and Leonidas Guibas and Jitendra Malik and Silvio Savarese
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, cs.AI, cs.LG, cs.NE, cs.RO
First published: 2018/04/23 (6 years ago)
Abstract: Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a structure among visual tasks. Knowing this structure has notable values; it is the concept underlying transfer learning and provides a principled way for identifying redundancies across tasks, e.g., to seamlessly reuse supervision among related tasks or solve many tasks in one system without piling up the complexity. We proposes a fully computational approach for modeling the structure of space of visual tasks. This is done via finding (first and higher-order) transfer learning dependencies across a dictionary of twenty six 2D, 2.5D, 3D, and semantic tasks in a latent space. The product is a computational taxonomic map for task transfer learning. We study the consequences of this structure, e.g. nontrivial emerged relationships, and exploit them to reduce the demand for labeled data. For example, we show that the total number of labeled datapoints needed for solving a set of 10 tasks can be reduced by roughly 2/3 (compared to training independently) while keeping the performance nearly the same. We provide a set of tools for computing and probing this taxonomical structure including a solver that users can employ to devise efficient supervision policies for their use cases.
|
[link]
The goal of this work is to perform transfer learning among numerous tasks and to discover visual relationships among them. Specifically, while we intiutively might guess the depth of an image and surface normals are related, this work takes a step forward and discovers a beneficial relationship among 26 tasks in terms of task transferability - many of them are not obvious. This is important for scenarios when an insufficient budget is available for target task for annotation, thus, learned representation from the 'cheaper' task could be used along with small dataset for the target task to reach sufficient performance on par with fully supervised training on a large dataset. The basis of the approach is to compute an affinity matrix among tasks based on whether the solution for one task can be sufficiently easily used for another task. This approach does not impose human intuition about the task relationships and chooses task transferability based on the quality of a transfer operation in a fully computational manner. The task taxonomy (i.e. **taskonomy**) is a computationally found directed hypergraph that captures the notion of task transferability over any given task dictionary. It performed using a four-step process depicted in the figure below:  - In stage I (**Task-specific Modelling**), a task-specific network is trained in a fully supervised manner. The network is composed of the encoder (modified ResNet-50), and fully convolutional decoder for pixel-to-pixel tasks, or 2-3 FC layers for low-dimensional tasks. Dataset consists of 4 million images of indoor scenes from about 600 buildings; every image has an annotation for every task. - In stage II (**Transfer modeling**), all feasible transfers between sources and targets are trained (multiple inputs task to single target transfer is also considered). Specifically, after the task-specific networks are trained in stage I, the weights of an encoder are fixed (frozen network is used to extract representations only) and the representation from the encoder is used to train a small readout network (similar to a decoder from stage I) with a new task as a target (i.e. ground truth is available). In total, about 3000 transfer possibilities are trained. - In stage III (**Taxonomy solver**), the task affinities acquired from the transfer functions performance are normalized. This is needed because different tasks lie in different spaces and transfer function scale. This is performed using ordinal normalization - Analytical Hierarchy Process (details are in the paper - Section 3.3). This results in an affinity matrix where a complete graph of relationships is completely normalized and this graph quantifies a pair-wise set of tasks evaluated in terms of a transfer function (i.e. task dependency). - In stage IV (**Computed Taxonomy**), a hypergraph which can predict the performance of any transfer policy and optimize for the optimal one is synthesized. This is solved using Binary Integer Program as a subgraph selection problem where tasks are nodes and transfers are edges. After the optimization process, the solution devices a connectivity that solves all target tasks, maximizes their collective performance while using only available source tasks under user-specified constraints (e.g. budget). So, if you want to train your network on an unseen task, you can obtain pretrained weights for existing tasks from the [project page](https://github.com/StanfordVL/taskonomy/tree/master/taskbank), train readout functions against each task (as well as combination of multiple inputs), build an affinity matrix to know where your task is positioned against the other ones, and through subgraph selection procedure observe what tasks have favourable influence on your task. Consequently, you can train your task with much less data by utilizing representations from the existing tasks which share visual significance with your task. Magnificent! |
Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
Naveed Akhtar and Ajmal Mian
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/01/02 (6 years ago)
Abstract: Deep learning is at the heart of the current rise of machine learning and artificial intelligence. In the field of Computer Vision, it has become the workhorse for applications ranging from self-driving cars to surveillance and security. Whereas deep neural networks have demonstrated phenomenal success (often beyond human capabilities) in solving complex problems, recent studies show that they are vulnerable to adversarial attacks in the form of subtle perturbations to inputs that lead a model to predict incorrect outputs. For images, such perturbations are often too small to be perceptible, yet they completely fool the deep learning models. Adversarial attacks pose a serious threat to the success of deep learning in practice. This fact has lead to a large influx of contributions in this direction. This article presents the first comprehensive survey on adversarial attacks on deep learning in Computer Vision. We review the works that design adversarial attacks, analyze the existence of such attacks and propose defenses against them. To emphasize that adversarial attacks are possible in practical conditions, we separately review the contributions that evaluate adversarial attacks in the real-world scenarios. Finally, we draw on the literature to provide a broader outlook of the research direction.
more
less
Naveed Akhtar and Ajmal Mian
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/01/02 (6 years ago)
Abstract: Deep learning is at the heart of the current rise of machine learning and artificial intelligence. In the field of Computer Vision, it has become the workhorse for applications ranging from self-driving cars to surveillance and security. Whereas deep neural networks have demonstrated phenomenal success (often beyond human capabilities) in solving complex problems, recent studies show that they are vulnerable to adversarial attacks in the form of subtle perturbations to inputs that lead a model to predict incorrect outputs. For images, such perturbations are often too small to be perceptible, yet they completely fool the deep learning models. Adversarial attacks pose a serious threat to the success of deep learning in practice. This fact has lead to a large influx of contributions in this direction. This article presents the first comprehensive survey on adversarial attacks on deep learning in Computer Vision. We review the works that design adversarial attacks, analyze the existence of such attacks and propose defenses against them. To emphasize that adversarial attacks are possible in practical conditions, we separately review the contributions that evaluate adversarial attacks in the real-world scenarios. Finally, we draw on the literature to provide a broader outlook of the research direction.
|
[link]
Akhtar and Mian present a comprehensive survey of attacks and defenses of deep neural networks, specifically in computer vision. Published on ArXiv in January 2018, but probably written prior to August 2017, the survey includes recent attacks and defenses. For example, Table 1 presents an overview of attacks on deep neural networks – categorized by knowledge, target and perturbation measure. The authors also provide a strength measure – in the form of a 1-5 start “rating”. Personally, however, I see this rating critically – many of the attacks have not been studies extensively (across a wide variety of defense mechanisms, tasks and datasets). In comparison to the related survey [1], their overview is slightly less detailed – the attacks, for example are described in less mathematical detail and the categorization in Table 1 is less comprehensive. https://i.imgur.com/cdAcivj.png Table 1: Overview of the discussed attacks on deep neural networks. [1] Xiaoyong Yuan, Pan He, Qile Zhu, Rajendra Rana Bhat, Xiaolin Li: Adversarial Examples: Attacks and Defenses for Deep Learning. CoRR abs/1712.07107 (2017) Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Adversarial Spheres
Justin Gilmer and Luke Metz and Fartash Faghri and Samuel S. Schoenholz and Maithra Raghu and Martin Wattenberg and Ian Goodfellow
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, 68T45, I.2.6
First published: 2018/01/09 (6 years ago)
Abstract: State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.
more
less
Justin Gilmer and Luke Metz and Fartash Faghri and Samuel S. Schoenholz and Maithra Raghu and Martin Wattenberg and Ian Goodfellow
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV, 68T45, I.2.6
First published: 2018/01/09 (6 years ago)
Abstract: State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.
|
[link]
Gilmer et al. study the existence of adversarial examples on a synthetic toy datasets consisting of two concentric spheres. The dataset is created by randomly sampling examples from two concentric spheres, one with radius $1$ and one with radius $R = 1.3$. While the authors argue that difference difficulties of the dataset can be created by varying $R$ and the dimensionality, they merely experiment with $R = 1.3$ and a dimensionality of $500$. The motivation to study this dataset comes form the idea that adversarial examples can easily be found by leaving the data manifold. Based on this simple dataset, the authors provide several theoretical insights – see the paper for details. Beneath theoretical insights, Gilmer et al. slso discuss the so-called manifold attack, an attack using projected gradient descent which ensures that the adversarial examples stays on the data-manifold – moreover, it is ensured that the class does not change. Unfortunately (as I can tell), this idea of a manifold attack is not studied further – which is very unfortunate and renders the question while this concept was introduced in the first place. One of the main take-aways is the suggestion that there is a trade-off between accuracy (i.e. the ability of the network to perform well) and the average distance to an adversarial example. Thus, the existence of adversarial examples might be related to the question why deep neural networks perform very well. Also see this summary at [davidstutz.de](https://davidstutz.de/category/reading/). |
Certified Defenses against Adversarial Examples
Aditi Raghunathan and Jacob Steinhardt and Percy Liang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG
First published: 2018/01/29 (6 years ago)
Abstract: While neural networks have achieved high accuracy on standard image classification benchmarks, their accuracy drops to nearly zero in the presence of small adversarial perturbations to test inputs. Defenses based on regularization and adversarial training have been proposed, but often followed by new, stronger attacks that defeat these defenses. Can we somehow end this arms race? In this work, we study this problem for neural networks with one hidden layer. We first propose a method based on a semidefinite relaxation that outputs a certificate that for a given network and test input, no attack can force the error to exceed a certain value. Second, as this certificate is differentiable, we jointly optimize it with the network parameters, providing an adaptive regularizer that encourages robustness against all attacks. On MNIST, our approach produces a network and a certificate that no attack that perturbs each pixel by at most \epsilon = 0.1 can cause more than 35% test error.
more
less
Aditi Raghunathan and Jacob Steinhardt and Percy Liang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG
First published: 2018/01/29 (6 years ago)
Abstract: While neural networks have achieved high accuracy on standard image classification benchmarks, their accuracy drops to nearly zero in the presence of small adversarial perturbations to test inputs. Defenses based on regularization and adversarial training have been proposed, but often followed by new, stronger attacks that defeat these defenses. Can we somehow end this arms race? In this work, we study this problem for neural networks with one hidden layer. We first propose a method based on a semidefinite relaxation that outputs a certificate that for a given network and test input, no attack can force the error to exceed a certain value. Second, as this certificate is differentiable, we jointly optimize it with the network parameters, providing an adaptive regularizer that encourages robustness against all attacks. On MNIST, our approach produces a network and a certificate that no attack that perturbs each pixel by at most \epsilon = 0.1 can cause more than 35% test error.
|
[link]
Raghunathan et al. provide an upper bound on the adversarial loss of two-layer networks and also derive a regularization method to minimize this upper bound. In particular, the authors consider the scoring functions $f^i(x) = V_i^T\sigma(Wx)$ with bounded derivative $\sigma'(z) \in [0,1]$ which holds for Sigmoid and ReLU activation functions. Still, the model is very constrained considering recent, well-performng deep (convolutional) neural networks. The upper bound is then derived by considering $f(A(x))$ where $A(x)$ is the optimal attacker $A(x) = \arg\max_{\tilde{x} \in B_\epsilon(x)} f(\tilde{x})$. For a linear model $f(x) = (W_1 – W_2)^Tx$, an upper bound can be derived as follows:
$f(\tilde{x}) = f(x) + (W_1 – W_2)^T(\tilde{x} – x) \leq f(x) + \epsilon\|W_1 – W_2\|_1$.
For two-layer networks a bound is derived by considering
$f(\tilde{x}) = f(x) + \int_0^1 \nabla f(t\tilde{x} + (1-t)x)^T (\tilde{x} – x) dt \leq f(x) + \max_{\tilde{x}\in B_\epsilon(x)} \epsilon\|\nabla f(\tilde{x})\|_1$.
In this case, Raghunathan rewrite the second term, i.e. $\max_{\tilde{x}\in B_\epsilon(x)} \epsilon\|\nabla f(\tilde{x})\|_1$ to derive an upper bound in the form of a semidefinite program, see the paper for details. For $v = V_1 – V_2$, this semidefinite program is based on the matrix
$M(v,W) = \left[\begin{array}0 & 0 & 1^T W^R \text{diag}(v)\\0 & 0 & W^T\text{diag}(v)\\ \text{diag}(v)^T W 1 & \text{diag}(v)^T W & 0\end{array}\right]$.
By deriving the dual objective, the upper bound can then be minimized by constraining the eigenvalues of $M(v, W)$ (specifically, the largest eigenvalue; note that the dual also involves dual variables – see the paper for details). Overall, the proposed regularize involves minimizing the largest eigenvalue of $M(v, W) – D$ where $D$ is a diagonal matrix based on the dual variables. In practice, this is implemented using SciPy's implementation of the Lanczos algorithm.
Also view this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality
Xingjun Ma and Bo Li and Yisen Wang and Sarah M. Erfani and Sudanthi Wijewickrema and Grant Schoenebeck and Dawn Song and Michael E. Houle and James Bailey
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, cs.CV
First published: 2018/01/08 (6 years ago)
Abstract: Deep Neural Networks (DNNs) have recently been shown to be vulnerable against adversarial examples, which are carefully crafted instances that can mislead DNNs to make errors during prediction. To better understand such attacks, a characterization is needed of the properties of regions (the so-called 'adversarial subspaces') in which adversarial examples lie. We tackle this challenge by characterizing the dimensional properties of adversarial regions, via the use of Local Intrinsic Dimensionality (LID). LID assesses the space-filling capability of the region surrounding a reference example, based on the distance distribution of the example to its neighbors. We first provide explanations about how adversarial perturbation can affect the LID characteristic of adversarial regions, and then show empirically that LID characteristics can facilitate the distinction of adversarial examples generated using state-of-the-art attacks. As a proof-of-concept, we show that a potential application of LID is to distinguish adversarial examples, and the preliminary results show that it can outperform several state-of-the-art detection measures by large margins for five attack strategies considered in this paper across three benchmark datasets. Our analysis of the LID characteristic for adversarial regions not only motivates new directions of effective adversarial defense, but also opens up more challenges for developing new attacks to better understand the vulnerabilities of DNNs.
more
less
Xingjun Ma and Bo Li and Yisen Wang and Sarah M. Erfani and Sudanthi Wijewickrema and Grant Schoenebeck and Dawn Song and Michael E. Houle and James Bailey
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.CR, cs.CV
First published: 2018/01/08 (6 years ago)
Abstract: Deep Neural Networks (DNNs) have recently been shown to be vulnerable against adversarial examples, which are carefully crafted instances that can mislead DNNs to make errors during prediction. To better understand such attacks, a characterization is needed of the properties of regions (the so-called 'adversarial subspaces') in which adversarial examples lie. We tackle this challenge by characterizing the dimensional properties of adversarial regions, via the use of Local Intrinsic Dimensionality (LID). LID assesses the space-filling capability of the region surrounding a reference example, based on the distance distribution of the example to its neighbors. We first provide explanations about how adversarial perturbation can affect the LID characteristic of adversarial regions, and then show empirically that LID characteristics can facilitate the distinction of adversarial examples generated using state-of-the-art attacks. As a proof-of-concept, we show that a potential application of LID is to distinguish adversarial examples, and the preliminary results show that it can outperform several state-of-the-art detection measures by large margins for five attack strategies considered in this paper across three benchmark datasets. Our analysis of the LID characteristic for adversarial regions not only motivates new directions of effective adversarial defense, but also opens up more challenges for developing new attacks to better understand the vulnerabilities of DNNs.
|
[link]
Ma et al. detect adversarial examples based on their estimated intrinsic dimensionality. I want to note that this work is also similar to [1] – in both publications, local intrinsic dimensionality is used to analyze adversarial examples. Specifically, the intrinsic dimensionality of a sample is estimated based on the radii $r_i(x)$ of the $k$-nearest neighbors around a sample $x$:
$- \left(\frac{1}{k} \sum_{i = 1}^k \log \frac{r_i(x)}{r_k(x)}\right)^{-1}$.
For details regarding the original, theoretical formulation of local intrinsic dimensionality I refer to the paper. In experiments, the authors show that adversarial examples exhibit a significant higher intrinsic dimensionality than training samples or randomly perturbed examples. This observation allows detection of adversarial examples. A proper interpretation of this finding is, however, missing. It would be interesting to investigate what this finding implies about the properties of adversarial examples.
|
Adversarial Vulnerability of Neural Networks Increases With Input Dimension
Carl-Johann Simon-Gabriel and Yann Ollivier and Léon Bottou and Bernhard Schölkopf and David Lopez-Paz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.CV, cs.LG, 68T45, I.2.6
First published: 2018/02/05 (6 years ago)
Abstract: Over the past four years, neural networks have proven vulnerable to adversarial images: targeted but imperceptible image perturbations lead to drastically different predictions. We show that adversarial vulnerability increases with the gradients of the training objective when seen as a function of the inputs. For most current network architectures, we prove that the $\ell_1$-norm of these gradients grows as the square root of the input-size. These nets therefore become increasingly vulnerable with growing image size. Over the course of our analysis we rediscover and generalize double-backpropagation, a technique that penalizes large gradients in the loss surface to reduce adversarial vulnerability and increase generalization performance. We show that this regularization-scheme is equivalent at first order to training with adversarial noise. Our proofs rely on the network's weight-distribution at initialization, but extensive experiments confirm all conclusions after training.
more
less
Carl-Johann Simon-Gabriel and Yann Ollivier and Léon Bottou and Bernhard Schölkopf and David Lopez-Paz
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.CV, cs.LG, 68T45, I.2.6
First published: 2018/02/05 (6 years ago)
Abstract: Over the past four years, neural networks have proven vulnerable to adversarial images: targeted but imperceptible image perturbations lead to drastically different predictions. We show that adversarial vulnerability increases with the gradients of the training objective when seen as a function of the inputs. For most current network architectures, we prove that the $\ell_1$-norm of these gradients grows as the square root of the input-size. These nets therefore become increasingly vulnerable with growing image size. Over the course of our analysis we rediscover and generalize double-backpropagation, a technique that penalizes large gradients in the loss surface to reduce adversarial vulnerability and increase generalization performance. We show that this regularization-scheme is equivalent at first order to training with adversarial noise. Our proofs rely on the network's weight-distribution at initialization, but extensive experiments confirm all conclusions after training.
|
[link]
Simon-Gabriel et al. Study the robustness of neural networks with respect to the input dimensionality. Their main hypothesis is that the vulnerability of neural networks against adversarial perturbations increases with the input dimensionality. To support this hypothesis, they provide a theoretical analysis as well as experiments.
The general idea of robustness is that small perturbations $\delta$ of the input $x$ do only result in small variations $\delta \mathcal{L}$ of the loss:
$\delta \mathcal{L} = \max_{\|\delta\| \leq \epsilon} |\mathcal{L}(x + \delta) - \mathcal{L}(x)| \approx \max_{\|\delta\| \leq \epsilon} |\partial_x \mathcal{L} \cdot \delta| = \epsilon \||\partial_x \mathcal{L}\||$
where the approximation is due to a first-order Taylor expansion and $\||\cdot\||$ is the dual norm of $\|\cdot\|$. As a result, the vulnerability of networks can be quantified by considering $\epsilon\mathbb{E}_x\||\partial_x \mathcal{L}\||$. A natural regularizer to increase robustness (i.e. decrease vulnerability) would be $\epsilon \||\partial_x \mathcal{L}\||$ which is a similar regularizer as proposed in [1].
The remainder of the paper studies the norm $\|\partial_x \mathcal{L}\|$ with respect to the input dimension $d$. Specifically, they show that the gradient norm increases monotonically with the input dimension. I refer to the paper for the exact theorems and proofs. This claim is based on the assumption of non-trained networks that have merely been initialized. However, in experiments, they show that the conclusion may hold true in realistic settings, e.g. on ImageNet.
[1] Matthias Hein, Maksym Andriushchenko:
Formal Guarantees on the Robustness of a Classifier against Adversarial Manipulation. NIPS 2017: 2263-2273
Also view this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
|
Deep contextualized word representations
Matthew E. Peters and Mark Neumann and Mohit Iyyer and Matt Gardner and Christopher Clark and Kenton Lee and Luke Zettlemoyer
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/02/15 (6 years ago)
Abstract: We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
more
less
Matthew E. Peters and Mark Neumann and Mohit Iyyer and Matt Gardner and Christopher Clark and Kenton Lee and Luke Zettlemoyer
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CL
First published: 2018/02/15 (6 years ago)
Abstract: We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
|
[link]
This paper introduces a deep universal word embedding based on using a bidirectional LM (in this case, biLSTM). First words are embedded with a CNN-based, character-level, context-free, token embedding into $x_k^{LM}$ and then each sentence is parsed using a biLSTM, maximizing the log-likelihood of a word given it's forward and backward context (much like a normal language model).
The innovation is in taking the output of each layer of the LSTM ($h_{k,j}^{LM}$ being the output at layer $j$)
$$
\begin{align}
R_k &= \{x_k^{LM}, \overrightarrow{h}_{k,j}^{LM}, \overleftarrow{h}_{k,j}^{LM} | j = 1 \ldots L \} \\
&= \{h_{k,j}^{LM} | j = 0 \ldots L \}
\end{align}
$$
and allowing the user to learn a their own task-specific weighted sum of these hidden states as the embedding:
$$
ELMo_k^{task} = \gamma^{task} \sum_{j=0}^L s_j^{task} h_{k,j}^{LM}
$$
The authors show that this weighted sum is better than taking only the top LSTM output (as in their previous work or in CoVe) because it allows capturing syntactic information in the lower layer of the LSTM and semantic information in the higher level. Table below shows that the second layer is more useful for the semantic task of word sense disambiguation, and the first layer is more useful for the syntactic task of POS tagging.
https://i.imgur.com/dKnyvAa.png
On other benchmarks, they show it is also better than taking the average of the layers (which could be done by setting $\gamma = 1$)
https://i.imgur.com/f78gmKu.png
To add the embeddings to your supervised model, ELMo is concatenated with your context-free embeddings, $\[ x_k; ELMo_k^{task} \]$. It can also be concatenated with the output of your RNN model $\[ h_k; ELMo_k^{task} \]$ which can show improvements on the same benchmarks
https://i.imgur.com/eBqLe8G.png
Finally, they show that adding ELMo to a competitive but simple baseline gets SOTA (at the time) on very many NLP benchmarks
https://i.imgur.com/PFUlgh3.png
It's all open-source and there's a tutorial [here](https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md)
|

Born Again Neural Networks
Tommaso Furlanello and Zachary C. Lipton and Michael Tschannen and Laurent Itti and Anima Anandkumar
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG
First published: 2018/05/12 (6 years ago)
Abstract: Knowledge distillation (KD) consists of transferring knowledge from one machine learning model (the teacher}) to another (the student). Commonly, the teacher is a high-capacity model with formidable performance, while the student is more compact. By transferring knowledge, one hopes to benefit from the student's compactness. %we desire a compact model with performance close to the teacher's. We study KD from a new perspective: rather than compressing models, we train students parameterized identically to their teachers. Surprisingly, these {Born-Again Networks (BANs), outperform their teachers significantly, both on computer vision and language modeling tasks. Our experiments with BANs based on DenseNets demonstrate state-of-the-art performance on the CIFAR-10 (3.5%) and CIFAR-100 (15.5%) datasets, by validation error. Additional experiments explore two distillation objectives: (i) Confidence-Weighted by Teacher Max (CWTM) and (ii) Dark Knowledge with Permuted Predictions (DKPP). Both methods elucidate the essential components of KD, demonstrating a role of the teacher outputs on both predicted and non-predicted classes. We present experiments with students of various capacities, focusing on the under-explored case where students overpower teachers. Our experiments show significant advantages from transferring knowledge between DenseNets and ResNets in either direction.
more
less
Tommaso Furlanello and Zachary C. Lipton and Michael Tschannen and Laurent Itti and Anima Anandkumar
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.AI, cs.LG
First published: 2018/05/12 (6 years ago)
Abstract: Knowledge distillation (KD) consists of transferring knowledge from one machine learning model (the teacher}) to another (the student). Commonly, the teacher is a high-capacity model with formidable performance, while the student is more compact. By transferring knowledge, one hopes to benefit from the student's compactness. %we desire a compact model with performance close to the teacher's. We study KD from a new perspective: rather than compressing models, we train students parameterized identically to their teachers. Surprisingly, these {Born-Again Networks (BANs), outperform their teachers significantly, both on computer vision and language modeling tasks. Our experiments with BANs based on DenseNets demonstrate state-of-the-art performance on the CIFAR-10 (3.5%) and CIFAR-100 (15.5%) datasets, by validation error. Additional experiments explore two distillation objectives: (i) Confidence-Weighted by Teacher Max (CWTM) and (ii) Dark Knowledge with Permuted Predictions (DKPP). Both methods elucidate the essential components of KD, demonstrating a role of the teacher outputs on both predicted and non-predicted classes. We present experiments with students of various capacities, focusing on the under-explored case where students overpower teachers. Our experiments show significant advantages from transferring knowledge between DenseNets and ResNets in either direction.
|
[link]
A finding first publicized by Geoff Hinton is the fact that, when you train a simple, lower capacity module on the probability outputs of another model, you can often get a model that has comparable performance, despite that lowered capacity. Another, even more interesting finding is that, if you take a trained model, and train a model with identical structure on its probability outputs, you can often get a model with better performance than the original teacher, with quicker convergence. This paper addresses, and tries to specifically test, a few theories about why this effect might be observed. One idea is that the "student" model can learn more quickly because getting to see the full probability distribution over a well-trained models outputs gives it a more valuable signal, specifically because the trained model is able to better rank the classes that aren't the true class. For example, if you're training on Imagenet, on an image of a huskies, you're only told "this is a husky (1), and not one of 100 other classes, which are all 0". Whereas a trained model might say "'this is most likely a husky, but the probability of wolf is way higher than that of teapot". This inherently gives you more useful signal to train on, because you’re given a full distribution of classes that an image is most like. This theory goes by the name of the “Dark Knowledge” theory (a truly delightful name), because it pulls all of this knowledge that is hidden in a 0/1 label into the light. An alternative explanation for the strong performance of distillation techniques is that the student model is just benefitting from the implicit importance weighting of having a stronger gradient on examples where the teacher model is more confident. You could think of this as leading the student towards examples that are the most clear or unambiguous examples of a class, rather than more fuzzy and uncertain ones. Along with a few other tests (which I won’t address here, for sake of time and focus), the authors design a few experiments to test these possible mechanisms of action. The first test involved doing an explicit importance weighting of examples according to how confident the teacher model is, but including no information about the incorrect classes. The second was similar, but instead involved perturbing the probabilities of the classes that weren’t the max probability. In this situation, the student model gets some information in terms of the overall magnitudes of the not-max class, but can’t leverage it as usefully because it’s been randomized. In both situations, they found that there still was some value - in other words, that the student outperformed the teacher - but it outperformed by less than the case where the teacher could see the full probability distribution. This supports the case that both the inclusion of probabilities for the less probable classes, as well as the “confidence weighting” effect of weighting the student to learn more from examples on which the “teacher” model was more confident. |
Image Transformer
Niki Parmar and Ashish Vaswani and Jakob Uszkoreit and Łukasz Kaiser and Noam Shazeer and Alexander Ku and Dustin Tran
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/15 (6 years ago)
Abstract: Image generation has been successfully cast as an autoregressive sequence generation or transformation problem. Recent work has shown that self-attention is an effective way of modeling textual sequences. In this work, we generalize a recently proposed model architecture based on self-attention, the Transformer, to a sequence modeling formulation of image generation with a tractable likelihood. By restricting the self-attention mechanism to attend to local neighborhoods we significantly increase the size of images the model can process in practice, despite maintaining significantly larger receptive fields per layer than typical convolutional neural networks. While conceptually simple, our generative models significantly outperform the current state of the art in image generation on ImageNet, improving the best published negative log-likelihood on ImageNet from 3.83 to 3.77. We also present results on image super-resolution with a large magnification ratio, applying an encoder-decoder configuration of our architecture. In a human evaluation study, we find that images generated by our super-resolution model fool human observers three times more often than the previous state of the art.
more
less
Niki Parmar and Ashish Vaswani and Jakob Uszkoreit and Łukasz Kaiser and Noam Shazeer and Alexander Ku and Dustin Tran
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/15 (6 years ago)
Abstract: Image generation has been successfully cast as an autoregressive sequence generation or transformation problem. Recent work has shown that self-attention is an effective way of modeling textual sequences. In this work, we generalize a recently proposed model architecture based on self-attention, the Transformer, to a sequence modeling formulation of image generation with a tractable likelihood. By restricting the self-attention mechanism to attend to local neighborhoods we significantly increase the size of images the model can process in practice, despite maintaining significantly larger receptive fields per layer than typical convolutional neural networks. While conceptually simple, our generative models significantly outperform the current state of the art in image generation on ImageNet, improving the best published negative log-likelihood on ImageNet from 3.83 to 3.77. We also present results on image super-resolution with a large magnification ratio, applying an encoder-decoder configuration of our architecture. In a human evaluation study, we find that images generated by our super-resolution model fool human observers three times more often than the previous state of the art.
|
[link]
Last year, a machine translation paper came out, with an unfortunately un-memorable name (the Transformer network) and a dramatic proposal for sequence modeling that eschewed both Recurrent NNN and Convolutional NN structures, and, instead, used self-attention as its mechanism for “remembering” or aggregating information from across an input. Earlier this month, the same authors released an extension of that earlier paper, called Image Transformer, that applies the same attention-only approach to image generation, and also achieved state of the art performance there. The recent paper offers a framing of attention that I find valuable and compelling, and that I’ll try to explicate here. They describe attention as being a middle ground between the approaches of CNNs and RNNs, and one that, to use an over-abused cliche, gets the best of both worlds. CNNs are explicitly local: each convolutional filter only gathers information from the cells that fall in specific locations along some predefined grid. And, because convolutional filters have a unique parameter for every relative location in the grid they’re applied to, increasing the size of any given filter’s receptive field would engender an exponential increase in parameters: to go from a 3x3 grid to a 4x4 one, you go from 9 parameters to 16. Convolutional networks typically increase their receptive field through the mechanism of adding additional layers, but there is still this fundamental limitation that for a given number of layers, CNNs will be fairly constrained in their receptive field. On the other side of the receptive field balance, we have RNNs. RNNs have an effectively unlimited receptive field, because they just apply one operation again and again: take in a new input, and decide to incorporate that information into the hidden state. This gives us the theoretical ability to access things from the distant past, because they’re stored somewhere in the hidden state. However, each element is only seen once and needs to be stored in the hidden state in a way that sort of “averages over” all of the ways it’s useful for various points in the decoding/translation process. (My mental image basically views RNN hidden state as packing for a long trip in a small suitcase: you have to be very clever about what you decide to pack, averaging over all the possible situations you might need to be prepared for. You can’t go back and pull different things into your suitcase as a function of the situation you face; you had to have chosen to add them at the time you encountered them). All in all, RNNs are tricky both because they have difficulty storing information efficiently over long time frames, and also because they can be monstrously slow to train, since you have to run through the full sequence to built up hidden state, and can’t chop it into localized bits the way you can with CNNs. So, between CNN - with its locally-specific hidden state - and RNN - with its large receptive field but difficulty in information storage - the self-attention approach interposes itself. Attention works off of three main objects: a query, and a set of keys, each one is attached to a value. In general, all of these objects take the form of vectors. For a given query, you calculate its similarity with each key, and then normalize those into a distribution (a set of weights, all of which sum to 1) that is used as the weights in calculating a weighted average of the values. As a motivating example, think of a model that is “unrolling” or decoding a translated sentence. In order to translate a sentence properly, the model needs to “remember” not only the conceptual content of the sentence, but what it has already generated. So, at each given point in the unrolling, the model can “query” the past and get a weighted distribution over what’s relevant to it in its current context. In the original Transformer, and also in the new one, the models use “multi-headed attention”, which I think is best compared to convolution filters: in the same way that you learn different convolution filters, each with different parameters, to pick up on different features, you learn different “heads” of the attention apparatus for the same purpose. To go back to our CNN - Attention - RNN schematic from earlier: Attention makes it a lot easier to query a large receptive field, since you don’t need an additional set of learned parameters for each location you expand to; you just use the same query weights and key weights you use for every other key and query. And, it allows you to contextually extract information from the past, depending on the needs you have right now. That said, it’s still the case that it becomes infeasible to make the length of the past you calculate your attention distribution over excessively long, but that cost is in terms of computation, not additional parameters, and thus is a question of training time, rather than essential model complexity, the way additional parameters is. Jumping all the way back up the stack, to the actual most recent image paper, this question of how best to limit the receptive field is one of the more salient questions, since it still is the case that conducting attention over every prior pixel would be a very large number of calculations. The Image Transformer paper solves this in a slightly hacky way: by basically subdividing the image into chunks, and having each chunk operate over the same fixed memory region (rather than scrolling the memory region with each pixel shift) to take better advantage of the speed of batched big matrix multiplies. Overall, this paper showed an advantage for the Image Transformer approach relevative to PixelCNN autoregressive generation models, and cited the ability for a larger receptive field during generation - without explosion in number of parameters - as the most salient reason why. |
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)
Shibani Santurkar and Dimitris Tsipras and Andrew Ilyas and Aleksander Madry
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG, cs.NE
First published: 2018/05/29 (6 years ago)
Abstract: Batch Normalization (BatchNorm) is a widely adopted technique that enables faster and more stable training of deep neural networks (DNNs). Despite its pervasiveness, the exact reasons for BatchNorm's effectiveness are still poorly understood. The popular belief is that this effectiveness stems from controlling the change of the layers' input distributions during training to reduce the so-called "internal covariate shift". In this work, we demonstrate that such distributional stability of layer inputs has little to do with the success of BatchNorm. Instead, we uncover a more fundamental impact of BatchNorm on the training process: it makes the optimization landscape significantly smoother. This smoothness induces a more predictive and stable behavior of the gradients, allowing for faster training. These findings bring us closer to a true understanding of our DNN training toolkit.
more
less
Shibani Santurkar and Dimitris Tsipras and Andrew Ilyas and Aleksander Madry
arXiv e-Print archive - 2018 via Local arXiv
Keywords: stat.ML, cs.LG, cs.NE
First published: 2018/05/29 (6 years ago)
Abstract: Batch Normalization (BatchNorm) is a widely adopted technique that enables faster and more stable training of deep neural networks (DNNs). Despite its pervasiveness, the exact reasons for BatchNorm's effectiveness are still poorly understood. The popular belief is that this effectiveness stems from controlling the change of the layers' input distributions during training to reduce the so-called "internal covariate shift". In this work, we demonstrate that such distributional stability of layer inputs has little to do with the success of BatchNorm. Instead, we uncover a more fundamental impact of BatchNorm on the training process: it makes the optimization landscape significantly smoother. This smoothness induces a more predictive and stable behavior of the gradients, allowing for faster training. These findings bring us closer to a true understanding of our DNN training toolkit.
|
[link]
At NIPS 2017, Ali Rahimi was invited on stage to give a keynote after a paper he was on received the “Test of Time” award. While there, in front of several thousand researchers, he gave an impassioned argument for more rigor: more small problems to validate our assumptions, more visibility into why our optimization algorithms work the way they do. The now-famous catchphrase of the talk was “alchemy”; he argued that the machine learning community has been effective at finding things that work, but less effective at understanding why the techniques we use work. A central example he used in his talk is that of Batch Normalization: a now nearly-universal step in optimizing deep nets, but one where our accepted explanation of “reducing internal covariate shift” is less rigorous than one might hope. With apologies for the long preamble, this is the context in which today’s paper is such a welcome push in the direction of what Rahimi was advocating for - small, focused experimentation that tries to build up knowledge from principles, and, specifically, asks the question: “Does Batch Norm really work via reducing covariate shift”. To answer the question of whether internal covariate shift is a likely mechanism of the - empirically very solid - improved performance of Batch Norm, the authors do a few simple experience. First, and most straightforwardly, they train a basic convolutional net with and without BatchNorm, pick a layer, and visualize the activation distribution of that layer over time, both in the Batch Norm and non-Batch Norm case. While they saw the expected performance boost, the Batch Norm case didn’t seem to be meaningfully more stable over time, relative to the normal case. Second, the authors tested what would happen if they added non-zero-mean random noise *after* Batch Norm in the network. The upshot of this was that they were explicitly engineering internal covariate shift, and, if control thereof was the primary useful purpose of Batch Norm, you would expect that to neutralize BN’s good performance. In this experiment, while the authors did indeed see noisier, less stable activation distributions in the noise + BN case (in particular: look at layer 13 activations in the attached image), but noisy BN performed nearly as well as non-noisy, and meaningfully better than the standard model without noise, but also without BN. As a final test, they approached the idea of “internal covariate shift” from a different definitional standpoint. Maybe a better way of thinking about it is in terms of stability of your gradients, in the face of updates made by lower layers of the network. That is to say: each parameter of the network pushes itself in the direction of lower loss all else held equal, but in practice, you change lower-level parameters simultaneously, which could cause the directional change the higher-layer parameter thought it needed to be off. So, the authors calculated the “gradient delta” between the gradient the model trains on, and what the gradient would be if you estimated it *after* all of the lower layers of the model had updated, such that the distribution of inputs to that layer has changed. Although the expectation would be that this gradient delta is smaller for batch norm, in fact, the authors found that, if anything, the opposite was true. So, in the face of none of these ideas panning out, the authors then introduce the best idea they’ve found for what motivates BN’s improved performance: a smoothing out of the loss function that SGD is optimizing. A smoother curve means, generally speaking, that the magnitudes of your gradients will be smaller, and also that the value of the gradient will change more slowly (i.e. low second derivative). As support for this idea, they show really different results for BN vs standard models in terms of, for example, how predictive a gradient at one point is of a gradient taken after you take a step in the direction of the first gradient. BN has meaningfully more predictive gradients, tied to lower variance in the values of the loss function in the direction of the gradient. The logic for why the mechanism of BN would cause this outcome is a bit tied up in math that’s hard to explain without LaTeX visuals, but basically comes from the idea that Batch Norm decreases the magnitude of the gradient of each layer output with respect to individual weight parameters, by averaging out those magnitudes over the batch. As Rahimi said in his initial talk, a lot of modern modeling is “applying brittle optimization techniques to loss surfaces we don’t understand.” And, by and large, that is in fact true: it’s devilishly difficult to get a good handle on what loss surfaces are doing when they’re doing it in several-million-dimensional space. But, it being hard doesn’t mean we should just give up on searching for principles we can build our understanding on, and I think this paper is a really fantastic example of how that can be done well.
1 Comments
 |
The unreasonable effectiveness of the forget gate
Jos van der Westhuizen and Joan Lasenby
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/13 (6 years ago)
Abstract: Given the success of the gated recurrent unit, a natural question is whether all the gates of the long short-term memory (LSTM) network are necessary. Previous research has shown that the forget gate is one of the most important gates in the LSTM. Here we show that a forget-gate-only version of the LSTM with chrono-initialized biases, not only provides computational savings but outperforms the standard LSTM on multiple benchmark datasets and competes with some of the best contemporary models. Our proposed network, the JANET, achieves accuracies of 99% and 92.5% on the MNIST and pMNIST datasets, outperforming the standard LSTM which yields accuracies of 98.5% and 91%.
more
less
Jos van der Westhuizen and Joan Lasenby
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/13 (6 years ago)
Abstract: Given the success of the gated recurrent unit, a natural question is whether all the gates of the long short-term memory (LSTM) network are necessary. Previous research has shown that the forget gate is one of the most important gates in the LSTM. Here we show that a forget-gate-only version of the LSTM with chrono-initialized biases, not only provides computational savings but outperforms the standard LSTM on multiple benchmark datasets and competes with some of the best contemporary models. Our proposed network, the JANET, achieves accuracies of 99% and 92.5% on the MNIST and pMNIST datasets, outperforming the standard LSTM which yields accuracies of 98.5% and 91%.
|
[link]
I have a lot of fondness for this paper as a result of its impulse towards clear explanations, simplicity, and pushing back against complexity for complexity’s sake. The goal of the paper is pretty straightforward. Long Short Term Memory networks (LSTM) work by having a memory vector, and pulling information into and out of that vector through a gating system. These gates take as input the context of the network at a given timestep (the prior hidden state, and the current input), apply weight matrices and a sigmoid activation, and produce “mask” vectors with values between 0 and 1. A typical LSTM learns three separate gates: a “forget” gate that controls how much of the old memory vector is remembered, an “input” gate that controls how much new contextual information is added to the memory, an “output” gate that controls how much of the output (a sum of the gated memory information, and the gated input information) is passed outward into a hidden state context that’s visible to the rest of the network. Note here that “hidden” is an unfortunate word here, since this is actually the state that is visible to the rest of the network, whereas the “memory” vector is only visible to the next-step memory updating calculations. Also note that “forget gate” is an awkward name insofar as the higher the value of the forget gate, the more that the model *remembers* of its past memory. This is confusing, but we appear to be stuck with this terminology The Gated Recurrent Unit, or GRU, did away with the output gate. In this system, the difference between “hidden” and “memory” vectors is removed, and so the network no longer has separate information channels for communicating with subsequent layers, and simple memory passed to future timesteps. On a wide range of problems, the GRU has performed comparably to the LSTM. This makes the authors ask: if a two-gate model can do as well, can a single gate model? In particular: how well does a LSTM-style model perform, if it only has a forget gate. The answer, to not bury the probably-obvious lede, is: quite well. Models that only have a forget gate perform comparably to or better than traditional LSTM models for the tasks at which they were tried. On a mechanical level, not having an input gate means that, instead of having individual scaling for “how much old memory do you remember” and “how much new context do you take in”, so that those values could be, for example, 0.2 and 0.15, these numbers are defined as a convex combination of a single value, which is the forget gate. That’s a fancy way of saying: we calculate some x between 0 and 1, and that’s the weight on the forget gate, and then (1-x) is the weight on the input gate. This model, for reasons that are entirely unjustified, and obviously the result of some In Joke, is called JANET, because with a single gate, it’s Just Another NETwork. Image is attached to prove I’m Not Making This Shit Up. The authors go down a few pathways of explaining why this forget-only model performs well, of which the most compelling is that it gives the model an easier and more efficient way to learn a skip connection, where information is passed down more or less intact to a future point in the model. It’s more straightforward to learn because the “skip-ness” of the connection, or, how strongly the information wants to propogate into the future, is just controlled by one set of parameters, and not a complex interaction of input, forget, and output. An interesting side investigation they perform is how the initialization of the bias term in the forget gate (which is calculated by applying weights to the input and former hidden state, and then adding a constant bias term) effects a model’s ability to learn long term dependencies. In particular, they discuss the situation where the model gets some signal, and then a long string of 0 values. If the bias term of the model is quite low, then all of those 0 values being used to calculate the forget gate will mean that only the bias is left, and the more times the bias is multiplied by itself, the smaller and closer to 0 it gets. The paper suggests initializing the bias of the forget gate according to the longest dependencies you expect the model to have, with the idea that you should more strongly bias your model towards remembering old information, regardless of what new information comes in, if you expect long term dependencies to be strongly relevant. |
Evolved Policy Gradients
Rein Houthooft and Richard Y. Chen and Phillip Isola and Bradly C. Stadie and Filip Wolski and Jonathan Ho and Pieter Abbeel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI
First published: 2018/02/13 (6 years ago)
Abstract: We propose a metalearning approach for learning gradient-based reinforcement learning (RL) algorithms. The idea is to evolve a differentiable loss function, such that an agent, which optimizes its policy to minimize this loss, will achieve high rewards. The loss is parametrized via temporal convolutions over the agent's experience. Because this loss is highly flexible in its ability to take into account the agent's history, it enables fast task learning. Empirical results show that our evolved policy gradient algorithm (EPG) achieves faster learning on several randomized environments compared to an off-the-shelf policy gradient method. We also demonstrate that EPG's learned loss can generalize to out-of-distribution test time tasks, and exhibits qualitatively different behavior from other popular metalearning algorithms.
more
less
Rein Houthooft and Richard Y. Chen and Phillip Isola and Bradly C. Stadie and Filip Wolski and Jonathan Ho and Pieter Abbeel
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI
First published: 2018/02/13 (6 years ago)
Abstract: We propose a metalearning approach for learning gradient-based reinforcement learning (RL) algorithms. The idea is to evolve a differentiable loss function, such that an agent, which optimizes its policy to minimize this loss, will achieve high rewards. The loss is parametrized via temporal convolutions over the agent's experience. Because this loss is highly flexible in its ability to take into account the agent's history, it enables fast task learning. Empirical results show that our evolved policy gradient algorithm (EPG) achieves faster learning on several randomized environments compared to an off-the-shelf policy gradient method. We also demonstrate that EPG's learned loss can generalize to out-of-distribution test time tasks, and exhibits qualitatively different behavior from other popular metalearning algorithms.
|
[link]
The general goal of meta-learning systems is to learn useful shared structure across a broad distribution of tasks, in such a way that learning on a new task can be faster. Some of the historical ways this has been done have been through initializations (i.e. initializing the network at a point such that it is easy to further optimize on each individual task, drawn from some distribution of tasks), and recurrent network structures (where you treat the multiple timesteps of a recurrent network as the training iterations on a single task, and train the recurrent weights of the network based on generalization performance on a wide range of tasks). This paper proposes a different approach: a learned proxy loss function. The idea here is that, often, early in the learning process, handcoded rewards aren’t the best or most valuable signal to use to guide a network, both because they may be high variance, and because they might not natively incentivize things like exploration rather than just exploitation. A better situation would be if we had some more far-sighted loss function we could use, that had proved to be a good proxy over a variety of different rewards. This is exactly what this method proposes to give us. Training consists of an inner loop, and an outer loop. Each instantiation of the inner loop corresponds to a single RL task, drawn from a distribution over tasks (for example, all tasks involving the robot walking to a position, with a single instantiated task being the task of walking to one specific position). Within the inner loop, we apply a typical policy gradient loop of optimizing the parameters of our policy, except, instead of expected rewards, we optimize our policy parameters according to a loss function we specifically parametrize. Within the outer loop, we take as signal the final reward on the trained policy on this task, and use that to update our parametrized loss. This parametrized loss is itself a neural network, that takes in the agent’s most recent set of states, actions, and rewards at a rolling window of recent timesteps, and performs temporal convolutions on those, to get a final loss value out the other side. In short, this auxiliary network takes in information about the agent’s recent behavior, and outputs an assessment of how well the agent is doing according to this longer-view loss criteria. Because it’s not possible to directly formulate the test performance of a policy in terms of the loss function that was used to train the policy (which would be necessary for backprop), the weights of this loss-calculating network are instead learned via evolutionary strategies. At a zoomed-out level of complexity, this means: making small random perturbations to the current parameters of the network, and moving in the direction of the random change that works the best. So, ultimately, you end up with a loss network that takes in recent environmental states and the behavior of the agent, and returns an estimate of the proxy loss value, that has hopefully been trained such that it captures environmental factors that indicate progress on the task, over a wide variety of similar tasks. Then, during testing, the RL agent can use that loss function to adapt its behavior. An interesting note here is that for tasks where the parameters of the task being learned are inferable from the environment - for example, where the goal is “move towards the green dot”, you don’t actually need to give the agent the rewards from a new task; ideally, it will have learned how to infer the task from the environment. One of the examples they use to prove their method has done something useful is train their model entirely on tasks where an ant-agent’s goal is to move towards various different targets on the right, and then shift it to a scenario where its target is towards the left. In the EPG case, the ant was able to quickly learn to move left, because it’s loss function was able to adapt to the new environment where the target had moved. By contrast, RL^2 (a trained learning algorithm implemented as a recurrent network) kept on moving right as its initial strategy, and seemed unable to learn the specifics of a task outside its original task distribution of “always move right”. I think this paper could benefit from being a little bit more concrete about what it’s expected use cases are (like: what kinds of environments lend themselves to having proxy loss functions inferred from environmental data? Which don’t?), but overall, I find the kernel of idea this model introduces interesting, and will be interested to see if other researchers run with it. |
Differentiable plasticity: training plastic neural networks with backpropagation
Thomas Miconi and Jeff Clune and Kenneth O. Stanley
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/06 (6 years ago)
Abstract: How can we build agents that keep learning from experience, quickly and efficiently, after their initial training? Here we take inspiration from the main mechanism of learning in biological brains: synaptic plasticity, carefully tuned by evolution to produce efficient lifelong learning. We show that plasticity, just like connection weights, can be optimized by gradient descent in large (millions of parameters) recurrent networks with Hebbian plastic connections. First, recurrent plastic networks with more than two million parameters can be trained to memorize and reconstruct sets of novel, high-dimensional 1000+ pixels natural images not seen during training. Crucially, traditional non-plastic recurrent networks fail to solve this task. Furthermore, trained plastic networks can also solve generic meta-learning tasks such as the Omniglot task, with competitive results and little parameter overhead. Finally, in reinforcement learning settings, plastic networks outperform a non-plastic equivalent in a maze exploration task. We conclude that differentiable plasticity may provide a powerful novel approach to the learning-to-learn problem.
more
less
Thomas Miconi and Jeff Clune and Kenneth O. Stanley
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/06 (6 years ago)
Abstract: How can we build agents that keep learning from experience, quickly and efficiently, after their initial training? Here we take inspiration from the main mechanism of learning in biological brains: synaptic plasticity, carefully tuned by evolution to produce efficient lifelong learning. We show that plasticity, just like connection weights, can be optimized by gradient descent in large (millions of parameters) recurrent networks with Hebbian plastic connections. First, recurrent plastic networks with more than two million parameters can be trained to memorize and reconstruct sets of novel, high-dimensional 1000+ pixels natural images not seen during training. Crucially, traditional non-plastic recurrent networks fail to solve this task. Furthermore, trained plastic networks can also solve generic meta-learning tasks such as the Omniglot task, with competitive results and little parameter overhead. Finally, in reinforcement learning settings, plastic networks outperform a non-plastic equivalent in a maze exploration task. We conclude that differentiable plasticity may provide a powerful novel approach to the learning-to-learn problem.
|
[link]
Meta learning is an area sparking a lot of research curiosity these days. It’s framed in different ways: models that can adapt, models that learn to learn, models that can learn a new task quickly. This paper uses a somewhat different lens: that of neural plasticity, and argues that applying the concept to modern neural networks will give us an effective, and biologically inspired way of building adaptable models. The basic premise of plasticity from a neurobiology perspective (at least how it was framed in the paper: I’m not a neuroscientist myself, and may be misunderstanding) is that plasticity performs a kind of gating function on the strength of a neural link being upregulated by experience. The most plastic a connection is, the more quickly it can get modified by new data; the less plastic, the more fixed it is. In concrete terms, this is implemented by subdividing the weight on each connection in the network into two parts: the “fixed” component, and the “plastic” component. (see picture). The fixed component acts like a typical weight: it gets modified during training, but stays fixed once training is done. The plastic component is composed of an alpha weight, multiplied by a term H. H is basically a decaying running average of the past input*output activations of this weight. Activations that are high in magnitude, and the same sign, for both the input and the output will lead to H being pushed higher. Note that that this H can continue to be updated even after the model is done training, because it builds up information whenever you pass a new input X through the network. The plastic component’s learned weight, alpha, controls how strong the influence of this is on the model. If alpha is near zero, then the connection behaves basically identically to a “typical” neural network, with weights that don’t change as a function of activation values. If alpha is positive, that means that strong co-activation within H will tend to make the connection weight higher. If alpha is negative, the opposite is true, and strong co-activation will make the connection weight more negative. (As an aside, I’d be really interested to see the distribution over alpha values in a trained model, relative to the weight values, and look at how often they go in the same direction as the weights, and increase magnitude, and how often they have the opposite direction and attenuate the weight towards zero). These models are trained by running them for fixed size “episodes” during which the H value gets iteratively changed, and then the alpha parameters of H get updated in the way that would have reduced error over the episode. One area in which they seem to show strong performance is that of memorization (where the network is shown an image once, and needs to reconstruct it later). The theory for why this is true is that the weights are able to store short-term information about which pixels are in the images it sees by temporarily boosting themselves higher for inputs and activations they’ve recently seen. There are definitely some intuitional gaps for me in this paper. The core one is: this framework just makes weights able to update themselves as a function of the values of their activations, not as a function of an actual loss function. That is to say: it seems like a potentially better analogy to neural plasticity is just a network that periodically gets more training data, and has some amount of connection plasticity to update as a result of that. |
Implicit Autoencoders
Alireza Makhzani
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/05/24 (6 years ago)
Abstract: In this paper, we describe the "implicit autoencoder" (IAE), a generative autoencoder in which both the generative path and the recognition path are parametrized by implicit distributions. We use two generative adversarial networks to define the reconstruction and the regularization cost functions of the implicit autoencoder, and derive the learning rules based on maximum-likelihood learning. Using implicit distributions allows us to learn more expressive posterior and conditional likelihood distributions for the autoencoder. Learning an expressive conditional likelihood distribution enables the latent code to only capture the abstract and high-level information of the data, while the remaining information is captured by the implicit conditional likelihood distribution. For example, we show that implicit autoencoders can disentangle the global and local information, and perform deterministic or stochastic reconstructions of the images. We further show that implicit autoencoders can disentangle discrete underlying factors of variation from the continuous factors in an unsupervised fashion, and perform clustering and semi-supervised learning.
more
less
Alireza Makhzani
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2018/05/24 (6 years ago)
Abstract: In this paper, we describe the "implicit autoencoder" (IAE), a generative autoencoder in which both the generative path and the recognition path are parametrized by implicit distributions. We use two generative adversarial networks to define the reconstruction and the regularization cost functions of the implicit autoencoder, and derive the learning rules based on maximum-likelihood learning. Using implicit distributions allows us to learn more expressive posterior and conditional likelihood distributions for the autoencoder. Learning an expressive conditional likelihood distribution enables the latent code to only capture the abstract and high-level information of the data, while the remaining information is captured by the implicit conditional likelihood distribution. For example, we show that implicit autoencoders can disentangle the global and local information, and perform deterministic or stochastic reconstructions of the images. We further show that implicit autoencoders can disentangle discrete underlying factors of variation from the continuous factors in an unsupervised fashion, and perform clustering and semi-supervised learning.
|
[link]
This paper outlines (yet another) variation on a variational autoencoder (VAE), which is, at a high level, a model that seeks to 1) learn to construct realistic samples from the data distribution, and 2) capture meaningful information about the data within its latent space. The “latent space” is a way of referring to the information bottleneck that happens when you compress the input (typically for these examples: an image) into a low-dimensional vector, before trying to predict that input out again using that low-dimensional vector as a seed or conditional input. In a typical VAE, the objective function is composed of two terms: a reconstruction loss that captures how well your Decoder distribution captures the X that was passed in as input, and a regularization loss that pushes the latent z code you create to be close to some input prior distribution. Pushing your learned z codes to be closer to a prior is useful because you can then sample using that prior, and have those draws map to the coheret regions of the space, where you’ve trained in the past. The Implicit Autoencoder proposal changes both elements of this objective function, but since one - the modification of the regularization term - is actually drawn from another (Adversarial Autoencoders), I’m primarily going to be focusing on the changes to the reconstruction term. In a typical variational autoencoder, the model is incentivized to perform an exact reconstruction of the input X, by using the latent code as input. Since this distance is calculated on a pixelwise basis, this puts a lot of pressure on the latent z code to learn ways of encoding this detailed local information, rather than what we’d like it to be capturing, which is broader, global structure of the data. In the IAE approach, instead of incentivizing the input x to be high probability in the distribution conditioned by the z that the encoder embedded off of x, we instead try to match the joint distributions of (x, z) and (reconstructed-x, z). This is done by taking these two pairs, and running them through a GAN, which needs to tell which pair represents the reconstructed x, and which the input x. Here, the GAN takes as input a concatenation of z (the embedded code for this image), and n, which is a random vector. Since a GAN is a deterministic mapping, this random vector n is what allows for sampling from this model, rather than just pulling the same output every time. Under this system, the model is under less pressure to recreate the details from the particular image that was input. Instead, it just needs to synchronize the use of z between the encoder and the decoder. To understand why this is true, imagine if you had an MNIST set of 1 and 2s, and a binary number for your z distribution. If you encode a 2, you can do so by setting that binary float to 0. Now, as long as your decoder realizes what the encoder was trying to do, and reconstructs a 2, then the joint distribution will be similar between the encoder and decoder, and our new objective function will be happy. An important fact here is: this doesn’t require that the decoder reconstruct the *exact* 2 that was passed in, as long as it matches, in distribution, the set of images that the encoder is choosing to map to the same z code, the decoder can do well. A consequence of this approach is an ability to modulate how much information you actually want to pull out into your latent vector, and how much you just want to be represented by your random noise vector, which will control randomness in the GAN and, to continue the example above, allow you to draw more than one distinct 2 off of the ‘2” latent code. If you have a limited set of z dimensionality, the they will represent high level concepts (for example: MNIST digits) and the rest of the variability in images will be modeled through the native GAN framework. If you have a high dimensional z, then more and more detail-level information will get encoded into the z vector, rather than just being left to the noise. |
Associative Compression Networks for Representation Learning
Alex Graves and Jacob Menick and Aaron van den Oord
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/06 (6 years ago)
Abstract: This paper introduces Associative Compression Networks (ACNs), a new framework for variational autoencoding with neural networks. The system differs from existing variational autoencoders (VAEs) in that the prior distribution used to model each code is conditioned on a similar code from the dataset. In compression terms this equates to sequentially transmitting the dataset using an ordering determined by proximity in latent space. Since the prior need only account for local, rather than global variations in the latent space, the coding cost is greatly reduced, leading to rich, informative codes. Crucially, the codes remain informative when powerful, autoregressive decoders are used, which we argue is fundamentally difficult with normal VAEs. Experimental results on MNIST, CIFAR-10, ImageNet and CelebA show that ACNs discover high-level latent features such as object class, writing style, pose and facial expression, which can be used to cluster and classify the data, as well as to generate diverse and convincing samples. We conclude that ACNs are a promising new direction for representation learning: one that steps away from IID modelling, and towards learning a structured description of the dataset as a whole.
more
less
Alex Graves and Jacob Menick and Aaron van den Oord
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.NE, cs.LG, stat.ML
First published: 2018/04/06 (6 years ago)
Abstract: This paper introduces Associative Compression Networks (ACNs), a new framework for variational autoencoding with neural networks. The system differs from existing variational autoencoders (VAEs) in that the prior distribution used to model each code is conditioned on a similar code from the dataset. In compression terms this equates to sequentially transmitting the dataset using an ordering determined by proximity in latent space. Since the prior need only account for local, rather than global variations in the latent space, the coding cost is greatly reduced, leading to rich, informative codes. Crucially, the codes remain informative when powerful, autoregressive decoders are used, which we argue is fundamentally difficult with normal VAEs. Experimental results on MNIST, CIFAR-10, ImageNet and CelebA show that ACNs discover high-level latent features such as object class, writing style, pose and facial expression, which can be used to cluster and classify the data, as well as to generate diverse and convincing samples. We conclude that ACNs are a promising new direction for representation learning: one that steps away from IID modelling, and towards learning a structured description of the dataset as a whole.
|
[link]
These days, a bulk of recent work in Variational AutoEncoders - a type of generative model - focuses on the question of how to add recently designed, powerful decoders (the part that maps from the compressed information bottleneck to the reconstruction) to VAEs, but still cause them to capture high level, conceptual information within the aforementioned information bottleneck (also know as a latent code). In the status quo, it’s the case that the decoder can do well enough even without conditioning on conceptual variables stored in the latent codes, that it’s not worth storing information there. The reason why VAEs typically make it costly to store information in latent codes is the typical inclusion of a term that measures the KL divergence (distributional distance, more or less) between an uninformative unit Gaussian (the prior) and distribution of latent z codes produced for each individual input x (the posterior). Intuitively, if the distribution for each input x just maps to the prior, then that gives the decoder no information about what x was initially passed in: this means the encoder has learned to ignore the latent code. The question of why this penalty term is included in the VAE has two answers, depending on whether you’re asking from a theoretical or practical standpoint. Theoretically, it’s because the original VAE objective function could be interpreted as a lower bound on the true p(x) distribution. Practically, pulling the individual distributions closer to that prior often has a regularizing effect, that causes z codes for individual files to be closer together, and also for closeness in z space to translate more to closeness in recreation concept. That happens because the encoder is disincentivized from making each individual z distribution that far from a prior. The upshot of this is that there’s a lot of overlap between the distributions learned for various input x values, and so it’s in the model’s interest to make the reconstruction of those nearby elements similar as well. The argument of this paper starts from the compression cost side. If you look at the KL divergence term with the prior from an information theory, you can see it as the “cost of encoding your posterior, using a codebook developed from your prior”. This is a bit of an opaque framing, but the right mental image is the morse code tree, the way that the most common character in the English language corresponds to the shortest morse symbol, and so on. This tree was optimized to make messages as short as possible, and was done so by mapping common letters to short symbols. But, if you were to encode a message in, say, Russian, you’d no longer be well optimized for the letter distribution in Russian, and your messages would generally be longer. So, in the typical VAE setting, we’re imagining a receiver who has no idea what message he’ll be sent yes, and so uses the global prior to inform their codebook. By contrast, the authors suggest a world in which we meaningfully order the entries sent to the receiver in terms of similarity. Then, if you use the heuristic “each message provides a good prior for the next message I’ll receive, you incur a lot less coding cost than, because the “prior” is designed to be a good distribution to use to encode this sample, which will hopefully be quite similar to the next one. On a practical level, this translates to: 1. Encoding a z distribution 2. Choosing one of that z code’s K closest neighbors 3. Putting that as input into a “prior network” that takes in the randomly chosen nearby c, and spits out distributional parameters for another distribution over zs, which we’ll call the “prior”. Intuitively, a lot of the trouble with the constraint that all z encodings be close to the same global prior is that that was just too restrictive. This paper tries to impose a local prior instead, that’s basically enforcing local smoothness, by pulling the z value closer to others already nearby it,but without forcing everything to look like a global prior. |
A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music
Adam Roberts and Jesse Engel and Colin Raffel and Curtis Hawthorne and Douglas Eck
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.SD, eess.AS, stat.ML
First published: 2018/03/13 (6 years ago)
Abstract: The Variational Autoencoder (VAE) has proven to be an effective model for producing semantically meaningful latent representations for natural data. However, it has thus far seen limited application to sequential data, and, as we demonstrate, existing recurrent VAE models have difficulty modeling sequences with long-term structure. To address this issue, we propose the use of a hierarchical decoder, which first outputs embeddings for subsequences of the input and then uses these embeddings to generate each subsequence independently. This structure encourages the model to utilize its latent code, thereby avoiding the "posterior collapse" problem which remains an issue for recurrent VAEs. We apply this architecture to modeling sequences of musical notes and find that it exhibits dramatically better sampling, interpolation, and reconstruction performance than a "flat" baseline model. An implementation of our "MusicVAE" is available online at http://g.co/magenta/musicvae-code.
more
less
Adam Roberts and Jesse Engel and Colin Raffel and Curtis Hawthorne and Douglas Eck
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.SD, eess.AS, stat.ML
First published: 2018/03/13 (6 years ago)
Abstract: The Variational Autoencoder (VAE) has proven to be an effective model for producing semantically meaningful latent representations for natural data. However, it has thus far seen limited application to sequential data, and, as we demonstrate, existing recurrent VAE models have difficulty modeling sequences with long-term structure. To address this issue, we propose the use of a hierarchical decoder, which first outputs embeddings for subsequences of the input and then uses these embeddings to generate each subsequence independently. This structure encourages the model to utilize its latent code, thereby avoiding the "posterior collapse" problem which remains an issue for recurrent VAEs. We apply this architecture to modeling sequences of musical notes and find that it exhibits dramatically better sampling, interpolation, and reconstruction performance than a "flat" baseline model. An implementation of our "MusicVAE" is available online at http://g.co/magenta/musicvae-code.
|
[link]
I’ve spent the last few days pretty deep in the weeds of GAN theory - with all its attendant sample-squinting and arcane training diagnosis - and so today I’m shifting gears to an applied paper, that mostly showcases some clever modifications of an underlying technique. The goal of the MusicVAE is as you might expect: to make music. But the goal isn’t just the ability to produce patterns of notes that sound musical, it’s the ability to learn a vector space where we can modify the values along each dimension, and cause the music we produce to vary along conceptually meaningful directions. In an ideal world, we might learn a dimension that corresponds to tempo, another that corresponds to the key we’re in, etc. To achieve this goal, the modelers use the structure of a Variational AutoEncoder, a model where we pass in the input, compress it down to some latent code (read: a low-dimensional vector of continuous values), and then, starting from that latent code, use a decoder to try to recreate (or “reconstruct”) the output. Think of this as describing a scene to a friend behind their back, and trying to describe it in a maximally informative way, so that they can draw it themselves, and get as close as possible to the original. Ideally, this set of constraints incentives you to learn an informative code, which will contain the kind of conceptually meaningful information that we want it to. One problem this can run into is that, given certain mathematical facts about the structure of autoencoders, if you use a decoder with a lot of capacity, like a RNN, the model can “decide” to use the RNN to model the data directly, storing all that conceptual information we’d like to have pulled out in the latent code in the parameters of the RNN instead. And, so, to solve this, the authors of the paper came up with a clever solution: instead of generating the full piece of music at once, they would instead build a hierarchical model, with a “conductor” layer that prescribes what a medium-sized chunk of the reconstructed piece will sound like, and a lower level “decoder” layer that takes the conductor’s direction for that chunk, and unspools it into a series of notes. On a more mechanical level, when the encoder spits out a latent code for a given piece of music, we pass that to the conductor. The conductor then produces - say - 10 embeddings, with each embedding corresponding to a set of 4 measures. Each decoder only sees the embedding for its chunk, and is only responsible for mapping that embedding into a series of concrete notes. This inability of each decoder to see what the decoders before and after it are doing means that, in order for the piece to sound coherent, the network needs to learn to develop a condensed set of instructions to give to the conductor. https://i.imgur.com/PQKoraX.png In practice, they come up with some really neat results: the example they show on the linked page demonstrates a learned concept-dimension that maps to “how much is this piece composed of long, held notes, vs short staccato ones”. They show that they can “interpolate” across this dimension (that is: slowly change its value) and see that the output slowly morphs from very long held notes, to a high density of different ones. |
Women also Snowboard: Overcoming Bias in Captioning Models
Kaylee Burns and Lisa Anne Hendricks and Kate Saenko and Trevor Darrell and Anna Rohrbach
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/26 (6 years ago)
Abstract: Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data (e.g., if a word is present in 60% of training sentences, it might be predicted in 70% of sentences at test time). This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over-reliance on the learned prior and image context. In this work we investigate generation of gender-specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender-specific predictions. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men. We also show that unlike other approaches, our model is indeed more often looking at people when predicting their gender.
more
less
Kaylee Burns and Lisa Anne Hendricks and Kate Saenko and Trevor Darrell and Anna Rohrbach
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/03/26 (6 years ago)
Abstract: Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data (e.g., if a word is present in 60% of training sentences, it might be predicted in 70% of sentences at test time). This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over-reliance on the learned prior and image context. In this work we investigate generation of gender-specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender-specific predictions. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men. We also show that unlike other approaches, our model is indeed more often looking at people when predicting their gender.
|
[link]
Concern about the issue of fairness (or the lack of it) in machine learning models is gaining widespread visibility among general public, the governments as well as the researchers. This is especially alarming as AI enabled systems are becoming more and more pervasive in our society as decisions are being taken by AI agents in healthcare to autonomous driving to criminal justice and so on. Bias in any dataset is, in some way or other, a reflection of the general attitude of humankind towards different activities which are typified by certain gender, race or ethnicity. As these datasets are the sources of knowledge for these AI models (especially the multimodal end-to-end models which depend only on the human annotated training datasets for literally everything), their decision making ability also gets shadowed by the bias in the dataset. This paper makes an important observation about the image captioning models that these models not only explore the bias in the dataset but tend to exaggerate them during inference. This is definitely a shortcoming of the current supervised models which are marked by their over-reliance on image context. The related works section of the paper (Section 2 first part: “Unwanted Dataset Bias”) gives an extensive review of the types of bias in the dataset and of the few recent works trying to address them. Gender bias (Presence of woman in kitchen makes most of us to guess a woman in a kitchen scene in case the person is not clearly apprehensible in the scene or a male is supposed to snowboard more often than a woman) and reporting biases (over reporting less common co-occurrences, such as “male nurse” or “green banana”) are two of the many present in machine learning datasets.
The paper addresses the problem of fair caption generation that would not presume a specific gender without appropriate evidence for that gender. This is done by introducing an ‘Equalizer Model’. This includes two complementary losses in addition to the normal cross entropy loss for the image captioning systems. The Appearance Confusion Loss (ACL) encourages the model to generate gender neutral words (for example ‘person’) when an image does not contain enough evidence of gender. During training, images of persons are masked out and the loss term encourages the gender words (“man” and “woman”) to have equal probability i.e., the model is encouraged to get confused when it should get confused instead of hallucinating from the context. The loss expression is pretty much intuitive (eqn (2) and (3)). However, it is not a good idea to make a model confused only. Thus the other loss (the Confident Loss (Conf)) is introduced. This loss encourages the model to predict gender words and predict them correctly when there is enough evidence of gender in the image. The loss function (eqns. (4) and (5)) has an intelligent use of the quotient between predicted probabilities of male and female gender words. If I have to give a single take away line from the paper then it will be the following which summarizes the working principle behind the two losses very succinctly.
> > “These complementary losses allow the Equalizer model to encourage models to be cautious in the absence of gender information and discriminative in its presence.”
The experiments are also well thought out. For experimentations, 3 different versions of the MSCOCO dataset is created - MSCOCO-Bias, MSCOCO-Confident and MSCOCO-Balanced. The bias in the gender gradually decreases in these 3 datasets. Three different metrics are also used to evaluate the model - Error rate (fraction of man/woman misclassifications), gender ratio (how close the gender ratio in the predicted captions of the test set is to the ground truth gender ratio), right for right reasons (whether the visual evidence used by the model for the prediction of the gender words coincide with the person images). There are a few baseline models and ablation studies. The baselines considered a naive image captioning model (‘Show and Tell’ approach), an approach where images corresponding to less common gender are sampled more while training and another baseline where the gender words are given higher weights in the cross-entropy loss. The ablation models considered the two losses (ACL and Conf) separately. For all the datasets, the proposed equalizer model consistently performed well according to all the 3 metrics. The experiments also show that, as the evaluation datasets become more and more balanced (i.e., the gender distribution departs more and more from the biased gender distribution in the training dataset), the performance of all the models falls away. However, the proposed model performs the best with the least inconsistency of performance among the the datasets. The qualitative examples with grad-cam and sliding window saliency maps for the gender words are also a positive point of the paper.
Things I would have liked the paper to contain:
* There are a few confusions in the expression of the conf loss in eqn. (4). Specifically, I am not sure what is the difference between $w_t$ and $\tilde{w}_t$. It seems the first one is the ground truth word and the later is the predicted word. It would have been good to have a clarification.
Overall, the paper is very new in defining the problem and in solving it. The solution strategy is very intuitive and easy to grasp. The paper is well written too. We can, sincerely, hope that this type of works addressing problems at the intersection of machine learning and societal issues would come more frequently and the discussed paper is a very significant first step towards it.
|

RUDDER: Return Decomposition for Delayed Rewards
Jose A. Arjona-Medina and Michael Gillhofer and Michael Widrich and Thomas Unterthiner and Sepp Hochreiter
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, math.OC, stat.ML
First published: 2018/06/20 (6 years ago)
Abstract: We propose a novel reinforcement learning approach for finite Markov decision processes (MDPs) with delayed rewards. In this work, biases of temporal difference (TD) estimates are proved to be corrected only exponentially slowly in the number of delay steps. Furthermore, variances of Monte Carlo (MC) estimates are proved to increase the variance of other estimates, the number of which can exponentially grow in the number of delay steps. We introduce RUDDER, a return decomposition method, which creates a new MDP with same optimal policies as the original MDP but with redistributed rewards that have largely reduced delays. If the return decomposition is optimal, then the new MDP does not have delayed rewards and TD estimates are unbiased. In this case, the rewards track Q-values so that the future expected reward is always zero. We experimentally confirm our theoretical results on bias and variance of TD and MC estimates. On artificial tasks with different lengths of reward delays, we show that RUDDER is exponentially faster than TD, MC, and MC Tree Search (MCTS). RUDDER outperforms rainbow, A3C, DDQN, Distributional DQN, Dueling DDQN, Noisy DQN, and Prioritized DDQN on the delayed reward Atari game Venture in only a fraction of the learning time. RUDDER considerably improves the state-of-the-art on the delayed reward Atari game Bowling in much less learning time. Source code is available at https://github.com/ml-jku/baselines-rudder, with demonstration videos at https://goo.gl/EQerZV.
more
less
Jose A. Arjona-Medina and Michael Gillhofer and Michael Widrich and Thomas Unterthiner and Sepp Hochreiter
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, math.OC, stat.ML
First published: 2018/06/20 (6 years ago)
Abstract: We propose a novel reinforcement learning approach for finite Markov decision processes (MDPs) with delayed rewards. In this work, biases of temporal difference (TD) estimates are proved to be corrected only exponentially slowly in the number of delay steps. Furthermore, variances of Monte Carlo (MC) estimates are proved to increase the variance of other estimates, the number of which can exponentially grow in the number of delay steps. We introduce RUDDER, a return decomposition method, which creates a new MDP with same optimal policies as the original MDP but with redistributed rewards that have largely reduced delays. If the return decomposition is optimal, then the new MDP does not have delayed rewards and TD estimates are unbiased. In this case, the rewards track Q-values so that the future expected reward is always zero. We experimentally confirm our theoretical results on bias and variance of TD and MC estimates. On artificial tasks with different lengths of reward delays, we show that RUDDER is exponentially faster than TD, MC, and MC Tree Search (MCTS). RUDDER outperforms rainbow, A3C, DDQN, Distributional DQN, Dueling DDQN, Noisy DQN, and Prioritized DDQN on the delayed reward Atari game Venture in only a fraction of the learning time. RUDDER considerably improves the state-of-the-art on the delayed reward Atari game Bowling in much less learning time. Source code is available at https://github.com/ml-jku/baselines-rudder, with demonstration videos at https://goo.gl/EQerZV.
|
[link]
[Summary by author /u/SirJAM_armedi](https://www.reddit.com/r/MachineLearning/comments/8sq0jy/rudder_reinforcement_learning_algorithm_that_is/e11swv8/). Math aside, the "big idea" of RUDDER is the following: We use an LSTM to predict the return of an episode. To do this, the LSTM will have to recognize what actually causes the reward (e.g. "shooting the gun in the right direction causes the reward, even if we get the reward only once the bullet hits the enemy after travelling along the screen"). We then use a salience method (e.g. LRP or integrated gradients) to get that information out of the LSTM, and redistribute the reward accordingly (i.e., we then give reward already once the gun is shot in the right direction). Once the reward is redistributed this way, solving/learning the actual Reinforcement Learning problem is much, much easier and as we prove in the paper, the optimal policy does not change with this redistribution. |
CocoNet: A deep neural network for mapping pixel coordinates to color values
Paul Andrei Bricman and Radu Tudor Ionescu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/05/29 (6 years ago)
Abstract: In this paper, we propose a deep neural network approach for mapping the 2D pixel coordinates in an image to the corresponding Red-Green-Blue (RGB) color values. The neural network is termed CocoNet, i.e. COordinates-to-COlor NETwork. During the training process, the neural network learns to encode the input image within its layers. More specifically, the network learns a continuous function that approximates the discrete RGB values sampled over the discrete 2D pixel locations. At test time, given a 2D pixel coordinate, the neural network will output the approximate RGB values of the corresponding pixel. By considering every 2D pixel location, the network can actually reconstruct the entire learned image. It is important to note that we have to train an individual neural network for each input image, i.e. one network encodes a single image only. To the best of our knowledge, we are the first to propose a neural approach for encoding images individually, by learning a mapping from the 2D pixel coordinate space to the RGB color space. Our neural image encoding approach has various low-level image processing applications ranging from image encoding, image compression and image denoising to image resampling and image completion. We conduct experiments that include both quantitative and qualitative results, demonstrating the utility of our approach and its superiority over standard baselines, e.g. bilateral filtering or bicubic interpolation.
more
less
Paul Andrei Bricman and Radu Tudor Ionescu
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/05/29 (6 years ago)
Abstract: In this paper, we propose a deep neural network approach for mapping the 2D pixel coordinates in an image to the corresponding Red-Green-Blue (RGB) color values. The neural network is termed CocoNet, i.e. COordinates-to-COlor NETwork. During the training process, the neural network learns to encode the input image within its layers. More specifically, the network learns a continuous function that approximates the discrete RGB values sampled over the discrete 2D pixel locations. At test time, given a 2D pixel coordinate, the neural network will output the approximate RGB values of the corresponding pixel. By considering every 2D pixel location, the network can actually reconstruct the entire learned image. It is important to note that we have to train an individual neural network for each input image, i.e. one network encodes a single image only. To the best of our knowledge, we are the first to propose a neural approach for encoding images individually, by learning a mapping from the 2D pixel coordinate space to the RGB color space. Our neural image encoding approach has various low-level image processing applications ranging from image encoding, image compression and image denoising to image resampling and image completion. We conduct experiments that include both quantitative and qualitative results, demonstrating the utility of our approach and its superiority over standard baselines, e.g. bilateral filtering or bicubic interpolation.
|
[link]
The experiment is nice. Though I assume the net practically memorized data and not inferred it as it makes little sense to say something intelligent on the pixel color by its location. What I wonder if this can be made into something more clever. A net with memory (RNN?) that gets the pixel coordinate in addition to estimation of pixels in the neighborhood or something. Anyhow, I wonder if there is a code to replicate results. |
Deep Learning: A Critical Appraisal
Gary Marcus
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG, stat.ML, 97R40, I.2.0; I.2.6
First published: 2018/01/02 (6 years ago)
Abstract: Although deep learning has historical roots going back decades, neither the term "deep learning" nor the approach was popular just over five years ago, when the field was reignited by papers such as Krizhevsky, Sutskever and Hinton's now classic (2012) deep network model of Imagenet. What has the field discovered in the five subsequent years? Against a background of considerable progress in areas such as speech recognition, image recognition, and game playing, and considerable enthusiasm in the popular press, I present ten concerns for deep learning, and suggest that deep learning must be supplemented by other techniques if we are to reach artificial general intelligence.
more
less
Gary Marcus
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG, stat.ML, 97R40, I.2.0; I.2.6
First published: 2018/01/02 (6 years ago)
Abstract: Although deep learning has historical roots going back decades, neither the term "deep learning" nor the approach was popular just over five years ago, when the field was reignited by papers such as Krizhevsky, Sutskever and Hinton's now classic (2012) deep network model of Imagenet. What has the field discovered in the five subsequent years? Against a background of considerable progress in areas such as speech recognition, image recognition, and game playing, and considerable enthusiasm in the popular press, I present ten concerns for deep learning, and suggest that deep learning must be supplemented by other techniques if we are to reach artificial general intelligence.
|
[link]
Deep Learning has a number of shortcomings. (1)Requires lot of data: Humans can learn abstract concepts with far less training data compared to current deep learning. E.g. If we are told who an “Adult” is, we can answer questions like how many adults are there in home?, Is he an adult? etc. without much data. Convolution networks can solve translational invariance but requires lot more data to identify other translations or more filters or different architectures. (2)Lack of transfer: Most of claims of Deep RL helping in transfer is ambiguous. Consider Deepmind claim of concept learning in Breakout such as digging a tunnel through a wall which was soon proved false by Vicarious experiments that added wall in middle and increased Y coordinate of paddle. Current attempt of transfer is based on correlations between trained sequences and test scenario, which is bound to fail when current scenario is tweaked. (3)Hierarchical structure not learnt: Deep learning learns correlations which are non-hierarchical in nature. So sentences like “Salman Khan, who was excellent driver, died in a car accident” can never be represented as major clause(Salman Khan) and minor clause(who was excellent driver) format. Subtleties like these cannot be captured by RNN even though hierarchical RNN tries to capture obvious hierarchies like (letters -> words -> sentences). If hierarchies were captured in Deep RL, transfer would have been easy in Breakout which is not the case. (4)Poor inference in language: Sentences that have subtle differences like “John promised Mary to leave” and “John promised to leave Mary” are treated as same by deep learning. This causes major problems during inferencing because questions related to combining various sentences fail. (5)Not transparent: Why the neural network made the decision in a certain way can help in debuggability and prove to be beneficial in medical diagnosis systems where it is critical to reason out methodology. (6)No priors and commonsense reasoning: Humans function with commonsense reasoning(If A is dad of B, A is elder to B) and priors(physics laws). Deep Learning does not tailor to incorporate this. With heavy interest in end to end learning from raw data, such attempts have been discouraged. (7)Deep Learning is correlation not causation: Causality or analogical reasoning or any abstract concepts of left brain is not dealt by deep learning. (8)Lacks generalization outside training distribution: Fails to incorporate scenario in which nature of data is varying. E.g. Stock prediction. (9)Easily fooled: E.g. Parking signs mistaken for refrigerators, turtle mistaken as rifle. This can be addressed by: (1)Unsupervised learning: Build systems that can set their own goals, use abstract knowledge(priors, affordances as objects can be used in any way etc) and solve problem at high level(like symbolic AI). (2)Symbolic AI - Deep Learning does what primary sensory cortex does of taking raw inputs and converting it into low level representation. Symbolic AI builds abstract concepts like causal, analogical reasoning which is what prefrontal Cortex does. Humans make decisions based on these abstract concepts. |

Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution
Judea Pearl
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/01/11 (6 years ago)
Abstract: Current machine learning systems operate, almost exclusively, in a statistical, or model-free mode, which entails severe theoretical limits on their power and performance. Such systems cannot reason about interventions and retrospection and, therefore, cannot serve as the basis for strong AI. To achieve human level intelligence, learning machines need the guidance of a model of reality, similar to the ones used in causal inference tasks. To demonstrate the essential role of such models, I will present a summary of seven tasks which are beyond reach of current machine learning systems and which have been accomplished using the tools of causal modeling.
more
less
Judea Pearl
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG, cs.AI, stat.ML
First published: 2018/01/11 (6 years ago)
Abstract: Current machine learning systems operate, almost exclusively, in a statistical, or model-free mode, which entails severe theoretical limits on their power and performance. Such systems cannot reason about interventions and retrospection and, therefore, cannot serve as the basis for strong AI. To achieve human level intelligence, learning machines need the guidance of a model of reality, similar to the ones used in causal inference tasks. To demonstrate the essential role of such models, I will present a summary of seven tasks which are beyond reach of current machine learning systems and which have been accomplished using the tools of causal modeling.
|
[link]
Paper overviews importance of Causality in AI and highlights important aspects of it. Current state of AI deals with only association/curve fitting of data without need of a model. But this is far from human-like intelligence who have a mental representation that is manipulated from time-to-time using data and queried with What If? questions. To incorporate this, one needs to add two more layers on top of curve fitting module which are interventions(What if I do this?) and counterfactuals(What if I had done this?). Interventions are represented by P(y|do(x)) where do(x) is action 'x' performed leading to change in behavior of certain variables, thereby making previous data useless for its estimation. Counterfactuals are represented by P(y(x)|x',y') where x',y' are observed and goal is to determine probability of y given x. Pearl suggests use of Structural Causal Models(SCM) for interventions and counterfactuals. SCM takes a query(association, intervention or counterfactual) and graphical model(based on assumptions) to build a estimand(mathematical recipe). Estimand takes data and produces an estimate(answer) with confidence. Assumptions are fine tuned based on data. There are lot of advantages provided by Causal Models - (1)Graphical models make it easier to read the assumptions, thereby providing transparency. It also makes it easier to verify all dependencies encoded in data with the help of d-separation, thereby providing testability (2)Causal models help in mediation analysis that identify mechanisms that change cause to effect for explainability (3)Current transfer learning approaches are tried at association level but it cannot identify mechanisms that are affected by changes (4)Causality provides tools to recover causal relationships when data has missing attributes unlike statistical analysis that provide tools only when values are missing at random i.e. independent of other variables. |
Effective deep learning training for single-image super-resolution in endomicroscopy exploiting video-registration-based reconstruction
Ravì, Daniele and Szczotka, Agnieszka Barbara and Shakir, Dzhoshkun Ismail and Pereira, Stephen P. and Vercauteren, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Ravì, Daniele and Szczotka, Agnieszka Barbara and Shakir, Dzhoshkun Ismail and Pereira, Stephen P. and Vercauteren, Tom
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Main purpose: * This work proposes a software-based resolution augmentation method which is more agile and simpler to implement than hardware engineering solutions. * The paper examines three deep learning single image super resolution techniques on pCLE images * A video-registration based method is proposed to estimate ground truth HR pCLE images (this can be assumed as the main objective of the paper) Highlights: * The papers emphasise that this is the first work to address the image resolution problem in pCLE image acquisitions * The paper introduces useful information on how pCLE devices work * Strong related work * Clear story * Comprehensive evaluation Main Idea: * Use video-registration based techniques to estimate the HR images (real ground truth HR image is not available) * Simulate LR images from estimate HR images with help of Voronoi diagram and Delaunay-based linear interpolation. * Train an Exemplar-based SR model (EBSR -- DL-based approach) to learn the mapping between simulated LR and estimate HR images. Methodology Details * To estimate the HR images, a video-registration based mosaicking techniques (by the same authors in MIA 2006) is used which fuses a collection of input images by averaging the temporal information. * Since mosaicking generates single large filed-of-view mosaic image from LR images, the mosaic-to-image diffeomorphic spatial transformation is used which results from the mosaicking process to propagate and crop the fused information from the mosaic back into each input LR image space. * At this point, the authors observe that the misalignment between input LR images (used in the video-registration based mosaicking technique) and estimate HR cause training problem for the EBSR model. So, they treat the HR images as realistic and chose to simulate LR images from them!!!! * Simulated LR images by obtained using the Voronoi diagram (averaging the Voronoi cell on HR image) + additive noise on estimate HR images. * Finally, they build to experimental datasets 1) LR_org and HR and 2) LR_synth and HR and train three CNN SR models on these twor datasets. * They train FSRCNN, EDSR, SRGAN * The networks are trained using L1+SSIM loss functions Experiment Notes: * SSIM and GCF are used to quantitatively assess the performance of the models. * A composite score is also used to take SSIM and GCF into account jointly * In the ideal case, when the models are trained and etsted on simulated LR and HR images, the quantitative results are convincing. * "From this experiment, it is possible to conclude that the proposed solution is capable of performing SR reconstruction when the models are trained on synthetic data with no domain gap at test time" * When models are trained and tested on original LR and estimate HR images, the performance is not reasonable * When the models are trained on simulated LR images and tested on original LR images, the results become better compared to the previous case, * For a solid conclusion, and MOS study was carried out. The models are trained on simulated LR images. |

Using Deep Learning for Segmentation and Counting within Microscopy Data
Hernández, Carlos X. and Sultan, Mohammad M. and Pande, Vijay S.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
Hernández, Carlos X. and Sultan, Mohammad M. and Pande, Vijay S.
arXiv e-Print archive - 2018 via Local Bibsonomy
Keywords: dblp
|
[link]
Given microscopy cell data, this work tries to determine the number of cells in the image. The whole pipeline is composed of two steps:
1. Cells segmentation:
- Feature Pyramid Network is used for generating a foreground mask;
- The last output of FPN is used for predicting mean foreground masks and aleatoric uncertainty masks. Each mask in both outputs is trained with aleatoric loss $ \frac{||y_{pred} - y_{gt} ||^2}{2\sigma} + \log{2\sigma}$ and [total-variational](https://en.wikipedia.org/wiki/Total_variation_denoising) loss. https://i.imgur.com/ssTuGVe.png
2. Cell counting:
- VGG-11 network is used as a feature extractor from the predicted foreground segmentation masks. There are two output branches following VGG: cell count branch and estimated variance branch. Training is done using L2 loss function with aleatoric uncertainty for cell counts.
https://i.imgur.com/aijZn7e.png
While the idea to utilize neural networks to count cells in the image seems fascinating, the real benefit of such system in production is quite questionable. Specifically, why would you need to add a VGG-like feature extractor on top of already predicted cell segmentation masks, if you could simply do more work in segmentation network (i.e. separate cells better, predict objectness/contour) and get the number of cells directly from the predicted masks?
|
Addressing Function Approximation Error in Actor-Critic Methods
Scott Fujimoto and Herke van Hoof and Dave Meger
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG, stat.ML
First published: 2018/02/26 (6 years ago)
Abstract: In value-based reinforcement learning methods such as deep Q-learning, function approximation errors are known to lead to overestimated value estimates and suboptimal policies. We show that this problem persists in an actor-critic setting and propose novel mechanisms to minimize its effects on both the actor and critic. Our algorithm takes the minimum value between a pair of critics to restrict overestimation and delays policy updates to reduce per-update error. We evaluate our method on the suite of OpenAI gym tasks, outperforming the state of the art in every environment tested.
more
less
Scott Fujimoto and Herke van Hoof and Dave Meger
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI, cs.LG, stat.ML
First published: 2018/02/26 (6 years ago)
Abstract: In value-based reinforcement learning methods such as deep Q-learning, function approximation errors are known to lead to overestimated value estimates and suboptimal policies. We show that this problem persists in an actor-critic setting and propose novel mechanisms to minimize its effects on both the actor and critic. Our algorithm takes the minimum value between a pair of critics to restrict overestimation and delays policy updates to reduce per-update error. We evaluate our method on the suite of OpenAI gym tasks, outperforming the state of the art in every environment tested.
|
[link]
As in Q-learning, modern actor-critic methods suffer from value estimation errors due to high bias and variance. While there are many attempts to address this in Q-learning (such as Double DQN), not much was done in actor-critic methods.
Authors of the paper propose three modifications to DDPG and empirically show that they help address both bias and variance issues:
* 1.) Clipped Double Q-Learning:
Add a second pair of critics $Q_{\theta}$ and $Q_{\theta_\text{target}}$ (so four critics total) and use them to upper-bound the value estimate target update: $y = r + \gamma \min\limits_{i=1,2} Q_{\theta_{target,i}}(s', \pi_{\phi_1}(s'))$
* 2.) Reduce number of policy and target networks updates, and magnitude of target networks updates: $\theta_{target} \leftarrow \tau\theta + (1-\tau)\theta_{target}$
* 3.) Inject (clipped) random noise to the target policy: $\hat{a} \leftarrow \pi_{\phi_{target}}(s) + \text{clip}(N(0,\sigma), -c, c)$
Implementing these results, authors show significant improvements on seven continuous control tasks, beating not only reference DDPG algorithm, but also PPO, TRPO and ACKTR.
Full algorithm from the paper:
https://i.imgur.com/rRjwDyT.png
Source code: https://github.com/sfujim/TD3
|

Image-based Synthesis for Deep 3D Human Pose Estimation
Grégory Rogez and Cordelia Schmid
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/12 (6 years ago)
Abstract: This paper addresses the problem of 3D human pose estimation in the wild. A significant challenge is the lack of training data, i.e., 2D images of humans annotated with 3D poses. Such data is necessary to train state-of-the-art CNN architectures. Here, we propose a solution to generate a large set of photorealistic synthetic images of humans with 3D pose annotations. We introduce an image-based synthesis engine that artificially augments a dataset of real images with 2D human pose annotations using 3D motion capture data. Given a candidate 3D pose, our algorithm selects for each joint an image whose 2D pose locally matches the projected 3D pose. The selected images are then combined to generate a new synthetic image by stitching local image patches in a kinematically constrained manner. The resulting images are used to train an end-to-end CNN for full-body 3D pose estimation. We cluster the training data into a large number of pose classes and tackle pose estimation as a $K$-way classification problem. Such an approach is viable only with large training sets such as ours. Our method outperforms most of the published works in terms of 3D pose estimation in controlled environments (Human3.6M) and shows promising results for real-world images (LSP). This demonstrates that CNNs trained on artificial images generalize well to real images. Compared to data generated from more classical rendering engines, our synthetic images do not require any domain adaptation or fine-tuning stage.
more
less
Grégory Rogez and Cordelia Schmid
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/12 (6 years ago)
Abstract: This paper addresses the problem of 3D human pose estimation in the wild. A significant challenge is the lack of training data, i.e., 2D images of humans annotated with 3D poses. Such data is necessary to train state-of-the-art CNN architectures. Here, we propose a solution to generate a large set of photorealistic synthetic images of humans with 3D pose annotations. We introduce an image-based synthesis engine that artificially augments a dataset of real images with 2D human pose annotations using 3D motion capture data. Given a candidate 3D pose, our algorithm selects for each joint an image whose 2D pose locally matches the projected 3D pose. The selected images are then combined to generate a new synthetic image by stitching local image patches in a kinematically constrained manner. The resulting images are used to train an end-to-end CNN for full-body 3D pose estimation. We cluster the training data into a large number of pose classes and tackle pose estimation as a $K$-way classification problem. Such an approach is viable only with large training sets such as ours. Our method outperforms most of the published works in terms of 3D pose estimation in controlled environments (Human3.6M) and shows promising results for real-world images (LSP). This demonstrates that CNNs trained on artificial images generalize well to real images. Compared to data generated from more classical rendering engines, our synthetic images do not require any domain adaptation or fine-tuning stage.
|
[link]
Aim: generate realistic-looking synthetic data that can be used to train 3D Human Pose Estimation methods. Instead of rendering 3D models, they choose to combine parts of real images. Input: RGB images with 2D annotations + a query 3D pose. Output: A synthetic image, stitched from patches of the images, so that it looks like a person in the query 3D pose. Steps: - Project 3D pose on random camera to get 2D coords - For each joint, find an image in the 2D annotated dataset whose annotation is locally similar - Based on the similarities, decide for each pixel which image is most relevant. - For each pixel, take the histogram of the chosen images in a neighborhood, and use this as blending factors to generate the result. They also present a method that they trained on this synthetic dataset. |

PoTrojan: powerful neural-level trojan designs in deep learning models
Minhui Zou and Yang Shi and Chengliang Wang and Fangyu Li and WenZhan Song and Yu Wang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CR, cs.LG
First published: 2018/02/08 (6 years ago)
Abstract: With the popularity of deep learning (DL), artificial intelligence (AI) has been applied in many areas of human life. Neural network or artificial neural network (NN), the main technique behind DL, has been extensively studied to facilitate computer vision and natural language recognition. However, the more we rely on information technology, the more vulnerable we are. That is, malicious NNs could bring huge threat in the so-called coming AI era. In this paper, for the first time in the literature, we propose a novel approach to design and insert powerful neural-level trojans or PoTrojan in pre-trained NN models. Most of the time, PoTrojans remain inactive, not affecting the normal functions of their host NN models. PoTrojans could only be triggered in very rare conditions. Once activated, however, the PoTrojans could cause the host NN models to malfunction, either falsely predicting or classifying, which is a significant threat to human society of the AI era. We would explain the principles of PoTrojans and the easiness of designing and inserting them in pre-trained deep learning models. PoTrojans doesn't modify the existing architecture or parameters of the pre-trained models, without re-training. Hence, the proposed method is very efficient.
more
less
Minhui Zou and Yang Shi and Chengliang Wang and Fangyu Li and WenZhan Song and Yu Wang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CR, cs.LG
First published: 2018/02/08 (6 years ago)
Abstract: With the popularity of deep learning (DL), artificial intelligence (AI) has been applied in many areas of human life. Neural network or artificial neural network (NN), the main technique behind DL, has been extensively studied to facilitate computer vision and natural language recognition. However, the more we rely on information technology, the more vulnerable we are. That is, malicious NNs could bring huge threat in the so-called coming AI era. In this paper, for the first time in the literature, we propose a novel approach to design and insert powerful neural-level trojans or PoTrojan in pre-trained NN models. Most of the time, PoTrojans remain inactive, not affecting the normal functions of their host NN models. PoTrojans could only be triggered in very rare conditions. Once activated, however, the PoTrojans could cause the host NN models to malfunction, either falsely predicting or classifying, which is a significant threat to human society of the AI era. We would explain the principles of PoTrojans and the easiness of designing and inserting them in pre-trained deep learning models. PoTrojans doesn't modify the existing architecture or parameters of the pre-trained models, without re-training. Hence, the proposed method is very efficient.
|
[link]
To keep it simple, this figure shows the basic idea. https://i.imgur.com/a2I4EGY.png |

DensePose: Dense Human Pose Estimation In The Wild
Rıza Alp Güler and Natalia Neverova and Iasonas Kokkinos
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/01 (6 years ago)
Abstract: In this work, we establish dense correspondences between RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense correspondences for 50K persons appearing in the COCO dataset by introducing an efficient annotation pipeline. We then use our dataset to train CNN-based systems that deliver dense correspondence 'in the wild', namely in the presence of background, occlusions and scale variations. We improve our training set's effectiveness by training an 'inpainting' network that can fill in missing groundtruth values and report clear improvements with respect to the best results that would be achievable in the past. We experiment with fully-convolutional networks and region-based models and observe a superiority of the latter; we further improve accuracy through cascading, obtaining a system that delivers highly0accurate results in real time. Supplementary materials and videos are provided on the project page http://densepose.org
more
less
Rıza Alp Güler and Natalia Neverova and Iasonas Kokkinos
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/02/01 (6 years ago)
Abstract: In this work, we establish dense correspondences between RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense correspondences for 50K persons appearing in the COCO dataset by introducing an efficient annotation pipeline. We then use our dataset to train CNN-based systems that deliver dense correspondence 'in the wild', namely in the presence of background, occlusions and scale variations. We improve our training set's effectiveness by training an 'inpainting' network that can fill in missing groundtruth values and report clear improvements with respect to the best results that would be achievable in the past. We experiment with fully-convolutional networks and region-based models and observe a superiority of the latter; we further improve accuracy through cascading, obtaining a system that delivers highly0accurate results in real time. Supplementary materials and videos are provided on the project page http://densepose.org
|
[link]
## Task
They introduce a dense version of the human pose estimation task: predict body surface coordinates for each pixel in an RGB image.
Body surface is representated on two levels:
- Body part label (24 parts)
- Head, torso, hands, feet, etc.
- Each leg split in 4 parts: upper/lower front/back. Same for arms.
- 2 coordinates (u,v) within body part
- head, hands, feet: based on SMPL model
- others: determined by Multidimensional Scaling on geodesic distances
## Data
* They annotate COCO for this task
- annotation tool: draw mask, then click on a 3D rendering for each of up to 14 points sampled from the mask
- annotator accuracy on synthetic renderings (average geodesic distance)
- small parts (e.g. feet): ~2 cm
- large parts (e.g. torso): ~7 cm
## Method
Fully-convolutional baseline
- ResNet-50/101
- 25-way body part classification head (cross-entropy loss)
- Regression head with 24*2 outputs per pixel (Huber loss)
Region-based approach
- Like Mask-RCNN
- New branch with same architecture as the keypoint branch
- ResNet-50-FPN (Feature Pyramid Net) backbone
Enhancements tested:
- Multi-task learning
- Train keypoint/mask and dense pose task at once
- Interaction implicit by sharing backbone net
- Multi-task *cross-cascading*
- Explicit interaction of tasks
- Introduce second stage that depends on the first-stage-output of all tasks
- Ground truth interpolation (distillation)
- Train a "teacher" FCN with the pointwise annotations
- Use its dense predictions as ground truth to train final net
- (To make the teacher as accurate as possible, they use ground-truth mask to remove background)
## Results
**Single-person results (train and test on single-person crops)**
Pointwise eval measure:
- Compute geodesic distance between prediction and ground truth at each annotated point
- For various error thresholds, plot percentage of points with lower error than the threshold
- Compute Area Under this Curve
Training (non-regional) FCN on new dataset vs. synthetic data improves AUC10 from 0.20 to 0.38
This paper's FCN method vs. model-fitting baseline
- Baseline: Estimate body keypoint locations in 2D (usual "pose estimation" task) + fit 3D model
- AUC10 improves from 0.23 to 0.43
- Speed: 4-25 fps for FCN vs. model-fitting taking 1-3 minutes per frame (!).
**Multi-person results**
- Region-based method outperforms FCN baseline: 0.25 -> 0.32
- FCN cannot deal well with varying person scales (despite multi-scale testing)
- Training on points vs interpolated ground-truth (distillation) 0.32 -> 0.38
- AUC10 with cross-task cascade: 0.39
Also: Per-instance eval ("Geodesic Point Similarity" - GPS)
- Compute a Gaussian function on the geodesic distances
- Average it within each person instance (=> GPS)
- Compute precision and recall of persons for various thresholds of GPS
- Compute average precision and recall over thresholds
Comparison of multi-task approaches:
1. Just dense pose branch (single-task) (AP 51)
2. Adding keypoint (AP 53) OR mask branch (multi-task without cross-cascade) (AP 52)
3. Refinement stage without cross-links (AP 52)
4. Multi-task cross-cascade (keypoints: AP 56, masks: AP 53)
|
Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers
Jianbo Ye and Xin Lu and Zhe Lin and James Z. Wang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG
First published: 2018/02/01 (6 years ago)
Abstract: Model pruning has become a useful technique that improves the computational efficiency of deep learning, making it possible to deploy solutions on resource-limited scenarios. A widely-used practice in relevant work assumes that a smaller-norm parameter or feature plays a less informative role at the inference time. In this paper, we propose a channel pruning technique for accelerating the computations of deep convolutional neural networks (CNNs), which does not critically rely on this assumption. Instead, it focuses on direct simplification of the channel-to-channel computation graph of a CNN without the need of performing a computational difficult and not always useful task of making high-dimensional tensors of CNN structured sparse. Our approach takes two stages: the first being to adopt an end-to-end stochastic training method that eventually forces the outputs of some channels being constant, and the second being to prune those constant channels from the original neural network by adjusting the biases of their impacting layers such that the resulting compact model can be quickly fine-tuned. Our approach is mathematically appealing from an optimization perspective and easy to reproduce. We experimented our approach through several image learning benchmarks and demonstrate its interesting aspects and the competitive performance.
more
less
Jianbo Ye and Xin Lu and Zhe Lin and James Z. Wang
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.LG
First published: 2018/02/01 (6 years ago)
Abstract: Model pruning has become a useful technique that improves the computational efficiency of deep learning, making it possible to deploy solutions on resource-limited scenarios. A widely-used practice in relevant work assumes that a smaller-norm parameter or feature plays a less informative role at the inference time. In this paper, we propose a channel pruning technique for accelerating the computations of deep convolutional neural networks (CNNs), which does not critically rely on this assumption. Instead, it focuses on direct simplification of the channel-to-channel computation graph of a CNN without the need of performing a computational difficult and not always useful task of making high-dimensional tensors of CNN structured sparse. Our approach takes two stages: the first being to adopt an end-to-end stochastic training method that eventually forces the outputs of some channels being constant, and the second being to prune those constant channels from the original neural network by adjusting the biases of their impacting layers such that the resulting compact model can be quickly fine-tuned. Our approach is mathematically appealing from an optimization perspective and easy to reproduce. We experimented our approach through several image learning benchmarks and demonstrate its interesting aspects and the competitive performance.
|
[link]
The central argument of the paper is that pruning deep neural networks by removing the smallest weights is not always wise. They provide two examples to show that regularisation in this form is unsatisfactory.
## **Pruning via batchnorm**
As an alternative to the traditional approach of removing small weights, the authors propose pruning filters using regularisation on the gamma term used to scale the result of batch normalization.
Consider a convolutional layer with batchnorm applied:
```
out = max{ gamma * BN( convolve(W,x) + beta, 0 }
```
By imposing regularisation on the gamma term the resulting image becomes constant almost everywhere (except for padding) because of the additive beta. The authors train the network using regularisation on the gamma term and after convergence remove any constant filters before fine-tuning the model with further training.
The general algorithm is as follows:
- **Compute the sparse penalty for each layer.** This essentially corresponds to determining the memory footprint of each channel of the layer. We refer to the penalty as lambda.
- **Rescale the gammas.** Choose some alpha in {0.001, 0.01, 0.1, 1} and use them to scale the gamma term of each layer - apply `1/alpha` to the successive convolutional layers.
- **Train the network using ISTA regularisation on gamma.** Train the network using SGD but applying the ISTA penalty to each layer using `rho * lambda` , where rho is another hyperparameter and lambda is the sparse penalty calculated in step 1.
- **Remove constant filters.**
- **Scale back.** Multiply gamma by `1 / gamma` and gamma respectively to scale the parameters back up.
- **Finetune.** Retrain the new network format for a small number of epochs.
1 Comments
 |

Curiosity-driven reinforcement learning with homeostatic regulation
Ildefons Magrans de Abril and Ryota Kanai
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI
First published: 2018/01/23 (6 years ago)
Abstract: We propose a curiosity reward based on information theory principles and consistent with the animal instinct to maintain certain critical parameters within a bounded range. Our experimental validation shows the added value of the additional homeostatic drive to enhance the overall information gain of a reinforcement learning agent interacting with a complex environment using continuous actions. Our method builds upon two ideas: i) To take advantage of a new Bellman-like equation of information gain and ii) to simplify the computation of the local rewards by avoiding the approximation of complex distributions over continuous states and actions.
more
less
Ildefons Magrans de Abril and Ryota Kanai
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.AI
First published: 2018/01/23 (6 years ago)
Abstract: We propose a curiosity reward based on information theory principles and consistent with the animal instinct to maintain certain critical parameters within a bounded range. Our experimental validation shows the added value of the additional homeostatic drive to enhance the overall information gain of a reinforcement learning agent interacting with a complex environment using continuous actions. Our method builds upon two ideas: i) To take advantage of a new Bellman-like equation of information gain and ii) to simplify the computation of the local rewards by avoiding the approximation of complex distributions over continuous states and actions.
|
[link]
Exploring an environment with non-linearities in a continuous action space can be optimized by regulating the agent curiosity with an homeostatic drive. This means that a heterostatic drive to move away from habitual states is blended with a homeostatic motivation to encourage actions that lead to states where the agent is familiar with a state-action pair.
This approach improves upon forward models and ICM Pathak et al 17 with an enhanced information gain that basically consists of the following: while the reward in \cite{Pathak17} is formulated as the forward model prediction error, the extended forward model loss in this paper is extended by substracting from the forward model prediction error the error knowing not only $s_t$ and $a_t$, but also $a_{t+1}$.
Curiosity-driven reinforcement learning shows that an additional homeostatic drive enhances the information gain of a classical curious/heterostatic agent.
Implementation: They take advantage of a new Bellman-like equation of information gain and simplify the computation of the local rewards. It could help by prioritizing the exploration of the state-action space according to how hard is to learn each region.
Background: The concept of homeostatic regulation in social robots was first proposed in Breazeal et al. 04. They extend existing approaches by compensating the heterostacity drive encouraged by the curiosity reward with an additional homeostatic drive. 1) The first component implements the heterostatic drive (same as referred to in Pathak et al 17). In other words, this one refers to the tendency to push away our agent from its habitual state; 2) Homeostatic motivation: the second component is our novel contribution. It encourages taking actions $a_t$ that lead to future states $s_{t+1}$ where the corresponding future action $a_{t+1}$ gives us additional information about $s_{t+1}$. This situation happens when the agent is "familiar" with the state-action pair: $\{s_{t+1}, a_{t+1}\}$.
The article misses exact comparison with Pathak et al regarding a joint task. In this paper the tasks consists of a 3 room navigation map is used to measure exploration.
|
Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation
Mark Sandler and Andrew Howard and Menglong Zhu and Andrey Zhmoginov and Liang-Chieh Chen
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/01/13 (6 years ago)
Abstract: In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
more
less
Mark Sandler and Andrew Howard and Menglong Zhu and Andrey Zhmoginov and Liang-Chieh Chen
arXiv e-Print archive - 2018 via Local arXiv
Keywords: cs.CV
First published: 2018/01/13 (6 years ago)
Abstract: In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
|
[link]
- **Linear Bottlenecks**. Authors show, that even though theoretically activations can be working in linear regime, removing activation from bottlenecks of residual network gives a boost to performance. -**Inverted residuals**. The shortcut connecting bottleneck perform better than shortcuts connecting the expanded layers - **SSDLite**. Authors propose to replace convolutions in SSD by depthwise convolutions, significantly reducing both number of parameters and number of calculations, with minor impact on precision. - **MobileNetV2**. A new architecture, which is basically ResNet with changes mentioned above, outperforms or shows comaparable performance with MobileNetV1, ShuffleNet and NASNet for same number of MACs. Object detection with SSDLite can be ran on ARM core in 200ms. Also a potential of semantic segmentation on mobile devices is chown: a network achieving 75.32% mIOU on PASCAL and only requiring 2.75B MACs. |
