
The International Conference on Learning Representations (ICLR) is the premier gathering of professionals dedicated to the advancement of the branch of artificial intelligence called representation learning, but generally referred to as deep learning.
Unrolled Generative Adversarial Networks
Luke Metz and Ben Poole and David Pfau and Jascha Sohl-Dickstein
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2016/11/07 (7 years ago)
Abstract: We introduce a method to stabilize Generative Adversarial Networks (GANs) by defining the generator objective with respect to an unrolled optimization of the discriminator. This allows training to be adjusted between using the optimal discriminator in the generator's objective, which is ideal but infeasible in practice, and using the current value of the discriminator, which is often unstable and leads to poor solutions. We show how this technique solves the common problem of mode collapse, stabilizes training of GANs with complex recurrent generators, and increases diversity and coverage of the data distribution by the generator.
more
less
Luke Metz and Ben Poole and David Pfau and Jascha Sohl-Dickstein
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2016/11/07 (7 years ago)
Abstract: We introduce a method to stabilize Generative Adversarial Networks (GANs) by defining the generator objective with respect to an unrolled optimization of the discriminator. This allows training to be adjusted between using the optimal discriminator in the generator's objective, which is ideal but infeasible in practice, and using the current value of the discriminator, which is often unstable and leads to poor solutions. We show how this technique solves the common problem of mode collapse, stabilizes training of GANs with complex recurrent generators, and increases diversity and coverage of the data distribution by the generator.













[link]
If you’ve ever read a paper on Generative Adversarial Networks (from now on: GANs), you’ve almost certainly heard the author refer to the scourge upon the land of GANs that is mode collapse. When a generator succumbs to mode collapse, that means that, instead of modeling the full distribution, of input data, it will choose one region where there is a high density of data, and put all of its generated probability weight there. Then, on the next round, the discriminator pushes strongly away from that region (since it now is majority-occupied by fake data), and the generator finds a new mode. In the view of the authors of the Unrolled GANs paper, one reason why this happens is that, in the typical GAN, at each round the generator implicitly assumes that it’s optimizing itself against the final and optimal discriminator. And, so, it makes its best move given that assumption, which is to put all its mass on a region the discriminator assigns high probability. Unfortunately for our short-sighted robot friend, this isn’t a one-round game, and this mass-concentrating strategy gives the discriminator a really good way to find fake data during the next round: just dramatically downweight how likely you think data is in the generator’s prior-round sweet spot, which it’s heavy concentration allows you to do without impacting your assessment of other data. Unrolled GANs operate on this key question: what if we could give the generator an ability to be less short-sighted, and make moves that aren’t just optimizing for the present, but are also defensive against the future, in ways that will hopefully tamp down on this running-around-in-circles dynamic illustrated above. If the generator was incentivized not only to make moves that fool the current discriminator, but also make moves that make the next-step discriminator less likely to tell it apart, the hope is that it will spread out its mass more, and be less likely to fall into the hole of a mode collapse. This intuition was realized in UnrolledGANs, through a mathematical approach that is admittedly a little complex for this discussion format. Essentially, in addition to the typical GAN loss (which is based on the current values of the generator and discriminator), this model also takes one “step forward” of the discriminator (calculates what the new parameters of the discriminator would be, if it took one update step), and backpropogates backward through that step. The loss under the next-step discriminator parameters is a function of both the current generator, and the next-step parameters, which come from the way the discriminator reacts to the current generator. When you take the gradient with respect to the generator of both of these things, you get something very like the ideal we described earlier: a generator that is trying to put its mass into areas the current discriminator sees as high-probability, but also change its parameters such that it gives the discriminator a less effective response strategy. https://i.imgur.com/0eEjm0g.png Empirically: UnrolledGANs do a quite good job at their stated aim of reducing mode collapse, and the unrolled training procedure is now a common building-block technique used in other papers.  |

Deep Information Propagation
Schoenholz, Samuel S. and Gilmer, Justin and Ganguli, Surya and Sohl-Dickstein, Jascha
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
Schoenholz, Samuel S. and Gilmer, Justin and Ganguli, Surya and Sohl-Dickstein, Jascha
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
_Objective:_ Fondamental analysis of random networks using mean-field theory. Introduces two scales controlling network behavior. ## Results: Guide to choose hyper-parameters for random networks to be nearly critical (in between order and chaos). This in turn implies that information can propagate forward and backward and thus the network is trainable (not vanishing or exploding gradient). Basically for any given number of layers and initialization covariances for weights and biases, tells you if the network will be trainable or not, kind of an architecture validation tool. **To be noted:** any amount of dropout removes the critical point and therefore imply an upper bound on trainable network depth. ## Caveats: * Consider only bounded activation units: no relu, etc. * Applies directly only to fully connected feed-forward networks: no convnet, etc. |

FractalNet: Ultra-Deep Neural Networks without Residuals
Larsson, Gustav and Maire, Michael and Shakhnarovich, Gregory
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
Larsson, Gustav and Maire, Michael and Shakhnarovich, Gregory
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
* They describe an architecture for deep CNNs that contains short and long paths. (Short = few convolutions between input and output, long = many convolutions between input and output)
* They achieve comparable accuracy to residual networks, without using residuals.
### How
* Basic principle:
* They start with two branches. The left branch contains one convolutional layer, the right branch contains a subnetwork.
* That subnetwork again contains a left branch (one convolutional layer) and a right branch (a subnetwork).
* This creates a recursion.
* At the last step of the recursion they simply insert two convolutional layers as the subnetwork.
* Each pair of branches (left and right) is merged using a pair-wise mean. (Result: One of the branches can be skipped or removed and the result after the merge will still be sound.)
* Their recursive expansion rule (left) and architecture (middle and right) visualized:

* Blocks:
* Each of the recursively generated networks is one block.
* They chain five blocks in total to create the network that they use for their experiments.
* After each block they add a max pooling layer.
* Their first block uses 64 filters per convolutional layer, the second one 128, followed by 256, 512 and again 512.
* Drop-path:
* They randomly dropout whole convolutional layers between merge-layers.
* They define two methods for that:
* Local drop-path: Drops each input to each merge layer with a fixed probability, but at least one always survives. (See image, first three examples.)
* Global drop-path: Drops convolutional layers so that only a single columns (and thereby path) in the whole network survives. (See image, right.)
* Visualization:
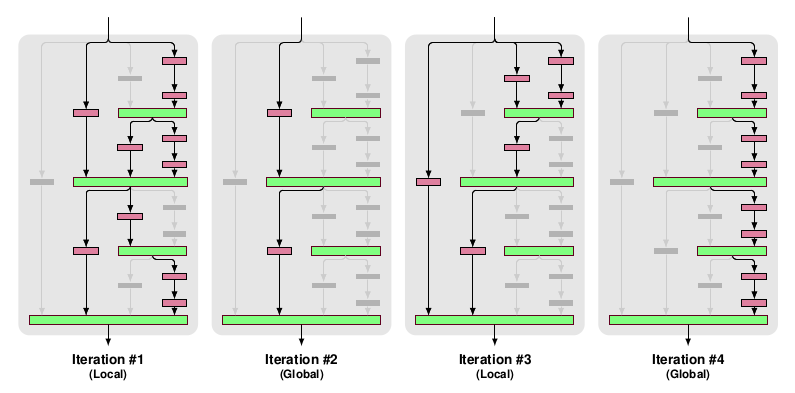
### Results
* They test on CIFAR-10, CIFAR-100 and SVHN with no or mild (crops, flips) augmentation.
* They add dropout at the start of each block (probabilities: 0%, 10%, 20%, 30%, 40%).
* They use for 50% of the batches local drop-path at 15% and for the other 50% global drop-path.
* They achieve comparable accuracy to ResNets (a bit behind them actually).
* Note: The best ResNet that they compare to is "ResNet with Identity Mappings". They don't compare to Wide ResNets, even though they perform best.
* If they use image augmentations, dropout and drop-path don't seem to provide much benefit (only small improvement).
* If they extract the deepest column and test on that one alone, they achieve nearly the same performance as with the whole network.
* They derive from that, that their fractal architecture is actually only really used to help that deepest column to learn anything. (Without shorter paths it would just learn nothing due to vanishing gradients.)
|

Pointer Sentinel Mixture Models
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CL, cs.AI
First published: 2016/09/26 (7 years ago)
Abstract: Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.
more
less
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.CL, cs.AI
First published: 2016/09/26 (7 years ago)
Abstract: Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.
|
[link]
TLDR; The authors combine a standard LSTM softmax with [Pointer Networks](https://arxiv.org/abs/1506.03134) in a mixture model called Pointer-Sentinel LSTM (PS-LSTM). The pointer networks helps with rare words and long-term dependencies but is unable to refer to words that are not in the input. The oppoosite is the case for the standard softmax. By combining the two approaches we get the best of both worlds. The probability of an output words is defined as a mixture of the pointer and softmax model and the mixture coefficient is calculated as part of the pointer attention. The authors evaluate their architecture on the PTB Language Modeling dataset where they achieve state of the art. They also present a novel WikiText dataset that is larger and more realistic then PTB. ### Key Points: - Standard RNNs with softmax struggle with rare and unseen words, even when adding attention. - Use a window of the most recent`L` words to match against. - Probability of output with gating: `p(y|x) = g * p_vocab(y|x) + (1 - g) * p_ptr(y|x)`. - The gate `g` is calcualted as an extra element in the attention module. Probabilities for the pointer network are then normalized accordingly. - Integrating the gating funciton computation into the pointer network is crucial: It needs to have access to the pointer network state, not just the RNN state (which can't hold long-term info) - WikiText-2 dataset: 2M train tokens, 217k validation tokens, 245k test tokens. 33k vocab, 2.6% OOV. 2x larger than PTB. - WikiText-1-3 dataset: 103M train tokens, 217k validation tokens, 245k test tokens. 267k vocab, 2.4% OOV. 100x larger than PTB. - Pointer Sentiment Model leads to stronger improvements for rare words - that makes intuitive sense. |

An Actor-Critic Algorithm for Sequence Prediction
Dzmitry Bahdanau and Philemon Brakel and Kelvin Xu and Anirudh Goyal and Ryan Lowe and Joelle Pineau and Aaron Courville and Yoshua Bengio
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG
First published: 2016/07/24 (7 years ago)
Abstract: We present an approach to training neural networks to generate sequences using actor-critic methods from reinforcement learning (RL). Current log-likelihood training methods are limited by the discrepancy between their training and testing modes, as models must generate tokens conditioned on their previous guesses rather than the ground-truth tokens. We address this problem by introducing a \textit{critic} network that is trained to predict the value of an output token, given the policy of an \textit{actor} network. This results in a training procedure that is much closer to the test phase, and allows us to directly optimize for a task-specific score such as BLEU. Crucially, since we leverage these techniques in the supervised learning setting rather than the traditional RL setting, we condition the critic network on the ground-truth output. We show that our method leads to improved performance on both a synthetic task, and for German-English machine translation. Our analysis paves the way for such methods to be applied in natural language generation tasks, such as machine translation, caption generation, and dialogue modelling.
more
less
Dzmitry Bahdanau and Philemon Brakel and Kelvin Xu and Anirudh Goyal and Ryan Lowe and Joelle Pineau and Aaron Courville and Yoshua Bengio
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG
First published: 2016/07/24 (7 years ago)
Abstract: We present an approach to training neural networks to generate sequences using actor-critic methods from reinforcement learning (RL). Current log-likelihood training methods are limited by the discrepancy between their training and testing modes, as models must generate tokens conditioned on their previous guesses rather than the ground-truth tokens. We address this problem by introducing a \textit{critic} network that is trained to predict the value of an output token, given the policy of an \textit{actor} network. This results in a training procedure that is much closer to the test phase, and allows us to directly optimize for a task-specific score such as BLEU. Crucially, since we leverage these techniques in the supervised learning setting rather than the traditional RL setting, we condition the critic network on the ground-truth output. We show that our method leads to improved performance on both a synthetic task, and for German-English machine translation. Our analysis paves the way for such methods to be applied in natural language generation tasks, such as machine translation, caption generation, and dialogue modelling.
|
[link]
TLDR; The authors propose to use the Actor Critic framework from Reinforcement Learning for Sequence prediction. They train an actor (policy) network to generate a sequence together with a critic (value) network that estimates the q-value function. Crucially, the actor network does not see the ground-truth output, but the critic does. This is different from LL (log likelihood) where errors are likely to cascade. The authors evaluate their framework on an artificial spelling correction and a real-world German-English Machine Translation tasks, beating baselines and competing approaches in both cases. #### Key Points - In LL training, the model is conditioned on its own guesses during search, leading to error compounding. - The critic is allowed to see the ground truth, but the actor isn't - The reward is a task-specific score, e.g. BLEU - Use bidirectional RNN for both actor and critic. Actor uses a soft attention mechanism. - The reward is partially receives at each intermediate step, not just at the end - Framework is analogous to TD-Learning in RL - Trick: Use additional target network to compute q_t (see Deep-Q paper) for stability - Trick: Use delayed actor (as in Deep Q paper) for stability - Trick: Put constraint on critic to deal with large action spaces (is this analogous to advantage functions?) - Pre-train actor and critic to encourage exploration of the right space - Task 1: Correct corrupt character sequence. AC outperforms LL training. Longer sequences lead to stronger lift. - Task 2: GER-ENG Machine Translation: Beats LL and Reinforce models - Qualitatively, critic assigns high values to words that make sense - BLUE scores during training are lower than those of LL model - Why? Strong regularization? Can't overfit the training data. #### Notes - Why does the sequence length for spelling prediction only go up to 30? This seems very short to me and something that an LSTM should be able to handle quite easily. Would've like to see much longer sequences. |
Reinforcement Learning with Unsupervised Auxiliary Tasks
Max Jaderberg and Volodymyr Mnih and Wojciech Marian Czarnecki and Tom Schaul and Joel Z Leibo and David Silver and Koray Kavukcuoglu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.NE
First published: 2016/11/16 (7 years ago)
Abstract: Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.
more
less
Max Jaderberg and Volodymyr Mnih and Wojciech Marian Czarnecki and Tom Schaul and Joel Z Leibo and David Silver and Koray Kavukcuoglu
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, cs.NE
First published: 2016/11/16 (7 years ago)
Abstract: Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.
|
[link]
TLDR; The authors augment the A3C (Asynchronous Actor Critic) algorithm with auxiliary tasks. These tasks share some of the network parameters but value functions for them are learned off-policy using n-step Q-Learning. The auxiliary tasks only used to learn a better representation and don't directly influence the main policy control. The technique, called UNREAL (Unsupervised Reinforcement and Auxiliary Learning), outperforms A3C on both the Atari and Labyrinth domains in terms of performance and training efficiency.
#### Key Points
- Environments contain a wide variety of possible training signals, not just cumulative reward
- Base A3C agent uses CNN + RNN
- Auxiliary Control and Prediction tasks share the convolutional and LSTM network for the "base agent". This forces the agent to balance improvement and base and aux. tasks.
- Auxiliary Tasks
- Use off-policy RL algorithms (e.g. n-step Q-Learning) so that the same stream of experience from the base agent can be used for maximizing all tasks. Experience is sampled from a replay buffer.
- Pixel Changes (Auxiliary Control): Learn a policy for maximally changing the pixels in a grid of cells overlaid over the images
- Network Features (Auxiliary Control): Learn a policy for maximally activating units in a specific hidden layer
- Reward Prediction (Auxiliary Reward): Predict the next reward given some historical context. Crucially, because rewards tend to be sparse, histories are sampled in a skewed manner from the replay buffer so that P(r!=0) = 0.5. Convolutional features are shared with the base agent.
- Value Function Replay: Value function regression for the base agent with varying window for n-step returns.
- UNREAL
- Base agent is optimized on-policy (A3C) and aux. tasks are optimized off-policy.
- Experiments
- Agent is trained with 20-step returns and aux. tasks are performed every 20 steps.
- Replay buffer stores the most recent 2k observations, actions and rewards
- UNREAL tends to be more robust to hyperparameter settings than A3C
- Labyrinth
- 38% -> 83% human-normalized score. Each aux. tasks independently adds to the performance.
- Significantly faster learning, 11x across all levels
- Compared to input reconstruction technique: Input reconstruction hurts final performance b/c it puts too much focus on reconstructing relevant parts.
- Atari
- Not all experiments are completed yet, but UNREAL already surpasses state of the art agents and is more robust.
#### Thoughts
- I want an algorithm box please :)
|
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Chris J. Maddison and Andriy Mnih and Yee Whye Teh
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2016/11/02 (7 years ago)
Abstract: The reparameterization trick enables the optimization of large scale stochastic computation graphs via gradient descent. The essence of the trick is to refactor each stochastic node into a differentiable function of its parameters and a random variable with fixed distribution. After refactoring, the gradients of the loss propagated by the chain rule through the graph are low variance unbiased estimators of the gradients of the expected loss. While many continuous random variables have such reparameterizations, discrete random variables lack continuous reparameterizations due to the discontinuous nature of discrete states. In this work we introduce concrete random variables -- continuous relaxations of discrete random variables. The concrete distribution is a new family of distributions with closed form densities and a simple reparameterization. Whenever a discrete stochastic node of a computation graph can be refactored into a one-hot bit representation that is treated continuously, concrete stochastic nodes can be used with automatic differentiation to produce low-variance biased gradients of objectives (including objectives that depend on the log-likelihood of latent stochastic nodes) on the corresponding discrete graph. We demonstrate their effectiveness on density estimation and structured prediction tasks using neural networks.
more
less
Chris J. Maddison and Andriy Mnih and Yee Whye Teh
arXiv e-Print archive - 2016 via Local arXiv
Keywords: cs.LG, stat.ML
First published: 2016/11/02 (7 years ago)
Abstract: The reparameterization trick enables the optimization of large scale stochastic computation graphs via gradient descent. The essence of the trick is to refactor each stochastic node into a differentiable function of its parameters and a random variable with fixed distribution. After refactoring, the gradients of the loss propagated by the chain rule through the graph are low variance unbiased estimators of the gradients of the expected loss. While many continuous random variables have such reparameterizations, discrete random variables lack continuous reparameterizations due to the discontinuous nature of discrete states. In this work we introduce concrete random variables -- continuous relaxations of discrete random variables. The concrete distribution is a new family of distributions with closed form densities and a simple reparameterization. Whenever a discrete stochastic node of a computation graph can be refactored into a one-hot bit representation that is treated continuously, concrete stochastic nodes can be used with automatic differentiation to produce low-variance biased gradients of objectives (including objectives that depend on the log-likelihood of latent stochastic nodes) on the corresponding discrete graph. We demonstrate their effectiveness on density estimation and structured prediction tasks using neural networks.
|
[link]
This paper presents a way to differentiate through discrete random variables by replacing them with continuous random variables. Say you have a discrete [categorical variable][cat] and you're sampling it with the [Gumbel trick][gumbel] like this ($G_k$ is a Gumbel distributed variable and $\boldsymbol{\alpha}/\sum_k \alpha_k$ are our categorical probabilities):
$$
z = \text{one_hot} \left( \underset{k}{\text{arg max}} [ G_k + \log \alpha_k ] \right)
$$
This paper replaces the one hot and argmax with a softmax, and they add a $\lambda$ variable to control the "temperature". As $\lambda$ tends to zero it will equal the above equation.
$$
z = \text{softmax} \left( \frac{ G_k + \log \alpha_k }{\lambda} \right)
$$
I made [some notes][nb] on how this process works, if you'd like more intuition.
Comparison to [Gumbel-softmax][gs]
--------------------------------------------
These papers are proposed precisely the same distribution with notation changes ([noted there][gs]). Both papers also reference each other and the differences. Although, they mention differences in the variatonal objectives to the Gumbel-softmax. This paper also compares to [VIMCO][], which is probably a harder benchmark to compare against (multi-sample versus single sample).
The results in both papers compare to SOTA score function based estimators and both report high scoring results (often the best). There are some details about implementations to consider though, such as scheduling and exactly how to define the variational objective.
[cat]: https://en.wikipedia.org/wiki/Categorical_distribution
[gumbel]: https://hips.seas.harvard.edu/blog/2013/04/06/the-gumbel-max-trick-for-discrete-distributions/
[gs]: http://www.shortscience.org/paper?bibtexKey=journals/corr/JangGP16
[nb]: https://gist.github.com/gngdb/ef1999ce3a8e0c5cc2ed35f488e19748
[vimco]: https://arxiv.org/abs/1602.06725
|

Recurrent Batch Normalization
Cooijmans, Tim and Ballas, Nicolas and Laurent, César and Courville, Aaron
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
Cooijmans, Tim and Ballas, Nicolas and Laurent, César and Courville, Aaron
arXiv e-Print archive - 2016 via Local Bibsonomy
Keywords: dblp
|
[link]
This paper describes how to apply the idea of batch normalization (BN) successfully to recurrent neural networks, specifically to LSTM networks. The technique involves the 3 following ideas: **1) Careful initialization of the BN scaling parameter.** While standard practice is to initialize it to 1 (to have unit variance), they show that this situation creates problems with the gradient flow through time, which vanishes quickly. A value around 0.1 (used in the experiments) preserves gradient flow much better. **2) Separate BN for the "hiddens to hiddens pre-activation and for the "inputs to hiddens" pre-activation.** In other words, 2 separate BN operators are applied on each contributions to the pre-activation, before summing and passing through the tanh and sigmoid non-linearities. **3) Use of largest time-step BN statistics for longer test-time sequences.** Indeed, one issue with applying BN to RNNs is that if the input sequences have varying length, and if one uses per-time-step mean/variance statistics in the BN transformation (which is the natural thing to do), it hasn't been clear how do deal with the last time steps of longer sequences seen at test time, for which BN has no statistics from the training set. The paper shows evidence that the pre-activation statistics tend to gradually converge to stationary values over time steps, which supports the idea of simply using the training set's last time step statistics. Among these ideas, I believe the most impactful idea is 1). The papers mentions towards the end that improper initialization of the BN scaling parameter probably explains previous failed attempts to apply BN to recurrent networks. Experiments on 4 datasets confirms the method's success. **My two cents** This is an excellent development for LSTMs. BN has had an important impact on our success in training deep neural networks, and this approach might very well have a similar impact on the success of LSTMs in practice. |
